한국어-중국어 번역 말뭉치(기술과학)
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021-06-18 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-09-25 저작도구 및 AI모델 소스코드 등록 소개
기술과학(예: 인공지능, 빅데이터, IT, SNS, 의학, 특허 등) 등 한-중 번역 말뭉치
구축목적
양질, 대규모 인공지능 학습 데이터를 구축 및 공개하여 중소ㆍ벤처기업, 스타트업 등 민간 기업들의 인공지능 기술개발을 촉진하고, 이들 기업이 인공지능 기술을 바탕으로 인공지능 서비스, 인공지능 제품을 공급하는 등 인공지능 활용 산업이 활성화를 위함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 데이터 출처 라벨링 유형 라벨링 형식 데이터 활용 서비스 데이터 구축년도/
데이터 구축량2020년/130만 -
구축 내용 및 제공 데이터량
- 데이터 구축분야: 의료/보건, 특허/기술, 자동차/교통/소재, IT/컴퓨터/모바일
- 한글 원문 어절 수 : 평균 15어절
- 수량 : 병렬 말뭉치 130만개
- 분야별 세부 구축 수량(단위:만): 의료/보건(25만), 특허/기술(15만), 자동차/교통/소재(30만), IT/컴퓨터/모바일(60만)
-
-
AI 모델 상세 설명서 다운로드
AI 모델 다운로드 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021.06.18 데이터 최초 개방 데이터셋명
- 한국어-중국어 번역 말뭉치(기술과학) [Construction of a Korean-Chinese Parallel Corpus(Technical science)]
구축 목적
- 양질, 대규모 인공지능 학습 데이터를 구축 및 공개하여 중소ㆍ벤처기업, 스타트업 등 민간 기업들의 인공지능 기술개발을 촉진하고, 이들 기업이 인공지능 기술을 바탕으로 인공지능 서비스, 인공지능 제품을 공급하는 등 인공지능 활용 산업이 활성화를 위함
활용 분야
- 민간 및 기관의 한국어-중국어 AI 자동번역 기술 개발 등
주요 키워드
- 크라우스소싱(집단지성), 인공지능, NMT, MTPE, 기계학습, 말뭉치, 인공지능 학습, 생태계, 번역, 기계번역
소개
- 다양한 분야의 한국어 원문 데이터로부터 정제된 한국어-중국어 번역 말뭉치를 구축하고 검증한 데이터셋으로, 특정 산업 영역에 편중되지 않으면서도 인공지능 개발에 공통적으로 활용할 수 있는 범용성 높은 데이터를 구축하였으며, 데이터의 재사용에 제한이 없도록 저작권 문제를 완전히 해결한 원천 데이터를 확보하여 인공지능 학습용 데이터 구축
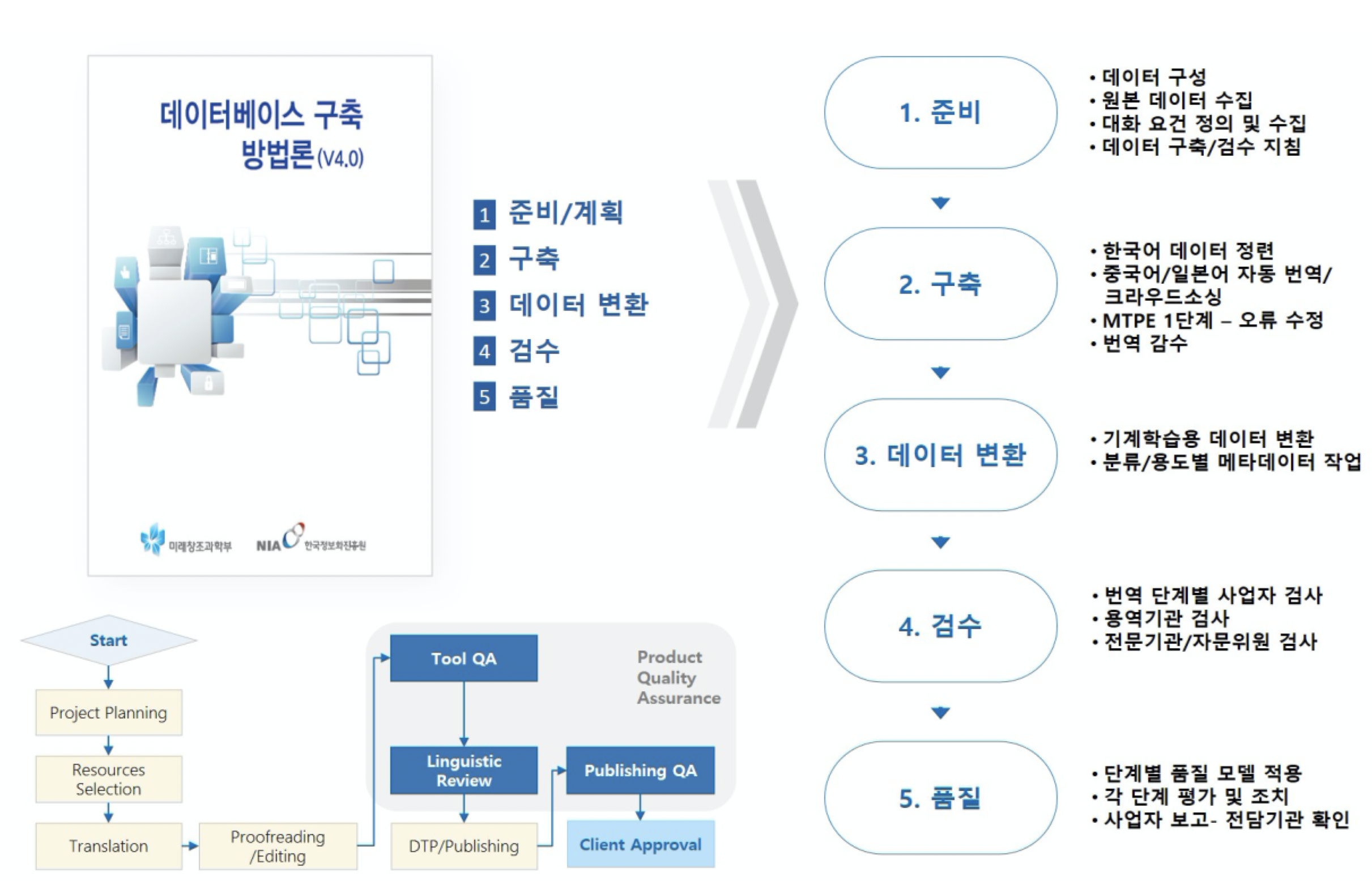
구축 내용 및 제공 데이터량
- 데이터 구축분야: 의료/보건, 특허/기술, 자동차/교통/소재, IT/컴퓨터/모바일
- 한글 원문 어절 수 : 평균 15어절
- 수량 : 병렬 말뭉치 130만개
- 분야별 세부 구축 수량(단위:만): 의료/보건(25만), 특허/기술(15만), 자동차/교통/소재(30만), IT/컴퓨터/모바일(60만)
대표도면

필요성
- 현재 대한민국은 AI 기술 연구 개발 및 활용의 시작 단계
- AI 데이터 축적/활용 미흡 (선진국[미국] 대비 약 2년의 기술력 차)
- AI 기술 개발을 위해 대규모 AI 학습용 데이터 확보 필수
- 중소·벤처 기업 수요는 있으나 구축 역량 부족
- AI 학습 데이터 자체 구축 시간/예산 부족 및 원천 데이터 확보의 어려움으로 정부 차원의 투자/지원 필요
데이터 구조
- 데이터 구성
데이터 구조 데이터 구성표 No. 속성명 타입 필수 여부 1 관리번호 string 필수 2 분야 string 필수 3 한국어 string 필수 4 중국어 string 필수 5 한국어_어절수 number 필수 6 중국어_글자수 number 필수 7 길이_분류 number 필수 8 출처 string 선택 9 수행기관 string 필수 - 구체적인 필드
데이터 구조 구체적인 필드 필드 정보 세부 내용 데이터 셋 명칭 한국어-중국어 기술과학 분야 이중 말뭉치 구축분야 의료/보건, 특허/기술, 자동차/교통/소재, IT/컴퓨터/모바일 구축량 130만 문장쌍 응용분야 언어모델, 자동번역 언어 원시어-한국어, 목적어-중국어 기타 - 제공형태
- JSON 중국어

-
데이터셋 구축 담당자
수행기관(주관) : 플리토
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 이정수 02-512-0162 [email protected] · 사업 관리 총괄 / 위탁용역 계약 및 업무관리 · 크라우드 소싱 활용한 한-중/일 번역(MTPE 번역/감수) · 활용 서비스 개발 및 방안 도출 수행기관(참여)
수행기관(참여) 기관명 담당업무 솔트룩스파트너스 · 한-일 번역(MTPE 번역/감수)
· 서비스 활용 방안 도출온아시아 · 한-중 번역 디엠티랩스 · 한-중 번역(MTPE 번역/감수)
· 서비스 활용 방안 도출에버트란 · 한-중/일 번역(MTPE 번역/감수)
· 서비스 활용 방안 도출윤즈정보개발 · 원시데이터 정제
· 저작권 구매(한국언론진흥재단, 한국학중앙연구원 등)데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이정수(플리토) 02-512-0162 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.