-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2021-08-11 데이터 추가 개방 1.1 2021-07-20 Info Table 추가 개방 1.0 2021-06-18 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-28 데이터 통계 항목 구축 수량 수정 소개
당뇨병 환자의 식단 관리를 위한 주재료 및 칼로리 정보가 포함된 음식 이미지 데이터
구축목적
인공지능의 학습용 데이터로 활용하기 위한 음식의 카테고리 및 음식이미지 데이터베이스는 점차 증가하고 있으며 해외에서는 인공지능 학습에 활용 가능한 다양한 음식 이미지 dataset이 구축되어 있음. 그러나 한국의 경우 인공지능 학습데이터로 활용 가능한 공개된 음식 이미지 데이터베이스가 부족한 실정임. 특히 한국음식의 경우 다양한 양념과 조리법을 활용한 mixed food가 주를 이루고 있기 때문에 음식 인식(recognition)과 분류(classification)가 어렵다는 단점이 있음. 따라서 인공지능 학습을 위한 수백만 장의 한국음식 이미지 데이터 수집을 위한 가장 기초 자료로 한국인이 많이 섭취하는 다빈도․다소비 식품 및 음식을 중심으로 음식 수집을 위한 카테고리를 구축하고 수집된 이미지와 매칭하기 위한 코드 표준화가 필요함
-
메타데이터 구조표 데이터 영역 헬스케어 데이터 유형 이미지 데이터 형식 데이터 출처 라벨링 유형 라벨링 형식 데이터 활용 서비스 데이터 구축년도/
데이터 구축량2020년/300만 -
구축 내용 및 제공 데이터량
- 시각지능기술 및 서비스 개발을 위해 필요한 각종 음식 이미지 데이터(음식명, 음식 건강정보 등)의 제작, 수집, 분 체계를 마련하고 관련 정보를 라벨링.
음식 인식성능의 강화를 위해 카테고리 500여개(카테고리별 약 50000여장)의 음식 데이터 확보 (다양한 음식 데이터 확보(한식, 중식, 일식, 수산물, 분식, 정통양식, 패스트푸드, 제과제빵케익, 커피 등))
데이터 종류 구축 수량 포함 내용 제공 방식 음식이미지 데이터베이스 500여종 X 60,000장 = 30,000,000장 원본이미지, JSON파일 파일 다운로드 - 시각지능기술 및 서비스 개발을 위해 필요한 각종 음식 이미지 데이터(음식명, 음식 건강정보 등)의 제작, 수집, 분 체계를 마련하고 관련 정보를 라벨링.
-
-
AI 모델 상세 설명서 다운로드
AI 모델 다운로드 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 재식별 정확도 Re-Identification YOLO v3 (Realtime Object Detection) AccuracyTop-1 85 % 86.5 % 2 음식이미지 주변 객체인식 모델 Object Detection YOLO v3 (Realtime Object Detection) mAP 85 % 87.65 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
건강관리를 위한 음식이미지-데이터변경이력 버전 일자 변경내용 비고 1.2 2021.08.11 데이터 추가 개방 1.1 2021.07.20 Info Table 추가 개방 1.0 2021.06.18 데이터 최초 개방 구축 목적
- 인공지능의 학습용 데이터로 활용하기 위한 음식의 카테고리 및 음식이미지 데이터베이스는 점차 증가하고 있으며 해외에서는 인공지능 학습에 활용 가능한 다양한 음식 이미지 dataset이 구축되어 있음.
- 그러나 한국의 경우 인공지능 학습데이터로 활용 가능한 공개된 음식 이미지 데이터베이스가 부족한 실정임.
- 특히 한국음식의 경우 다양한 양념과 조리법을 활용한 mixed food가 주를 이루고 있기 때문에 음식 인식(recognition)과 분류(classification)가 어렵다는 단점이 있음.
- 따라서 인공지능 학습을 위한 수백만 장의 한국음식 이미지 데이터 수집을 위한 가장 기초 자료로 한국인이 많이 섭취하는 다빈도․다소비 식품 및 음식을 중심으로 음식 수집을 위한 카테고리를 구축하고 수집된 이미지와 매칭하기 위한 코드 표준화가 필요함
활용 분야
- 당뇨환자의 식단을 분석 관리할 수 있는 앱 상용화 및 건강 관리 정보 서비스 사업화 및 다양한 헬스케어산업의 발전에 이바지할 것으로 사료됨.
소개
- 본 연구를 통해 구축하고자 하는 인공지능(AI) 애프터케어 플랫폼 시스템은 개인건강, 병원 건강관리정보 서비스, 헬스케어센터의 건강관리정보 제공 서비스 등에 활용할 수 있는 이미지 기반 데이터 운영 플랫폼으로 이용자가 이미지로 저장된 음식정보에 대해 편리한 접근성과 사용성을 제공함.
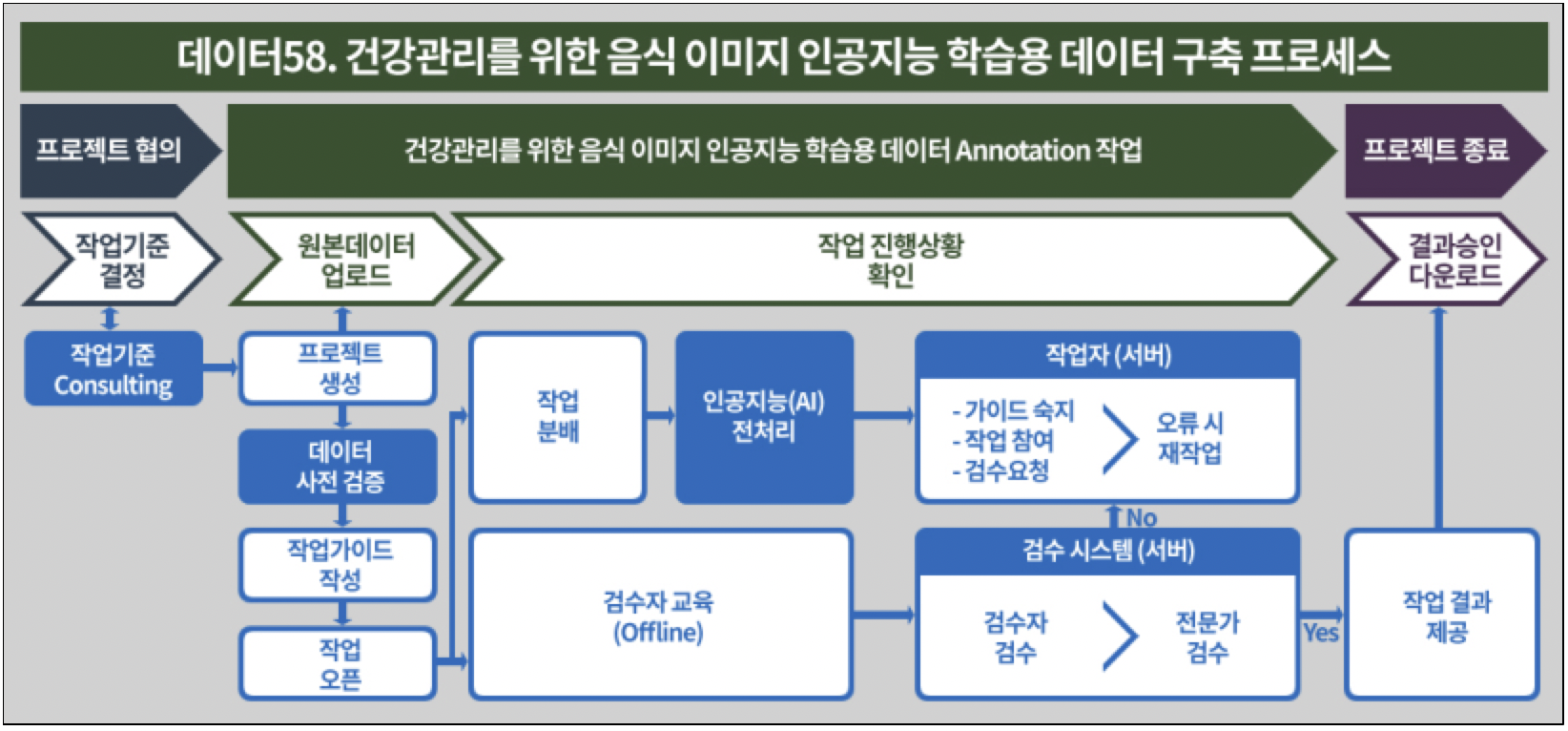
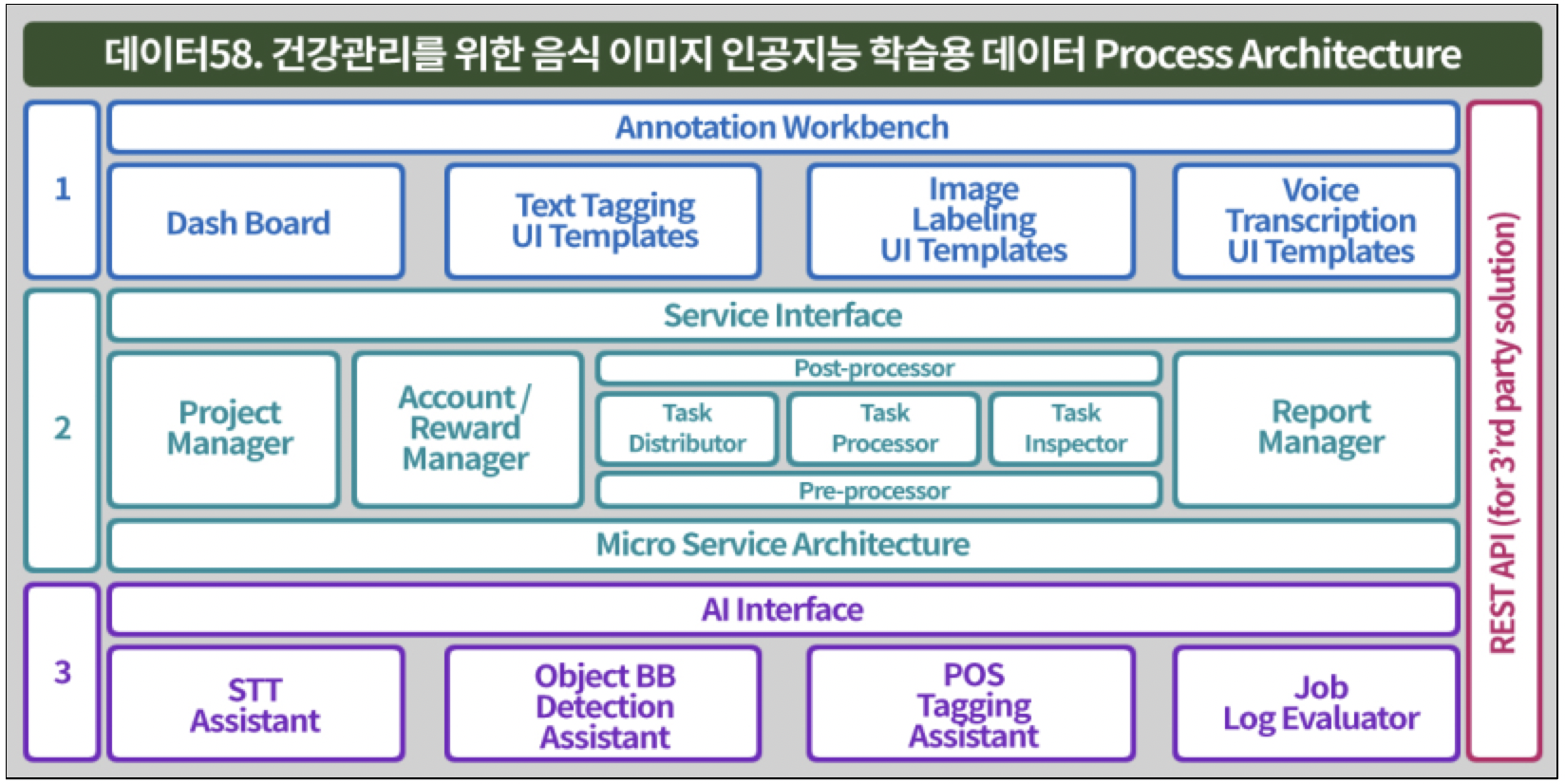
구축 내용 및 제공 데이터량
- 시각지능기술 및 서비스 개발을 위해 필요한 각종 음식 이미지 데이터(음식명, 음식 건강정보 등)의 제작, 수집, 분 체계를 마련하고 관련 정보를 라벨링.
음식 인식성능의 강화를 위해 카테고리 500여개(카테고리별 약 50000여장)의 음식 데이터 확보 (다양한 음식 데이터 확보(한식, 중식, 일식, 수산물, 분식, 정통양식, 패스트푸드, 제과제빵케익, 커피 등))
데이터 종류 구축 수량 포함 내용 제공 방식 음식이미지 데이터베이스 500여종 X 60,000장 = 3,000,000장 원본이미지, JSON파일 파일 다운로드 대표도면
- 카테고리별로 사용된 레시피 자료와 식품별 100g 메타정보를 활용하여 1인 1회분량에 대한 메타 정보(에너지, 탄수화물, 단백질, 지방)를 계산하여 구축하였음
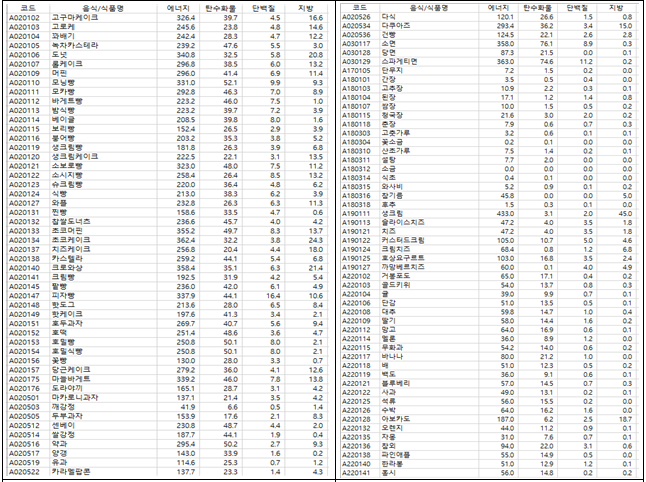
- 500여개 카테고리에 포함된 음식/식품을 분류
대표도면 표3 대분류 소분류 밥, 국, 탕, 찌개, 전골 짬뽕밥, 냉이된장국, 누룽지, 다슬기국, 수수밥, 수제비,
순대국, 달걀볶음밥, 순대전골, 미역국, 참치찌개 등스프, 죽, 조림, 장아찌, 조림, 나물 숙주나물, 단무지, 단호박샐러드, 쪽파무침, 시금치나물, 달걀찜 등 구이, 튀김, 육류, 어류 냉채족발, 너비아니구이, 느타리버섯꼬치, 수육, 순대,
쪽갈비구이, 순살치킨, 쭈꾸미구이, 버섯볶음 등면, 만두류 냉모밀, 짬뽕, 라면, 우동, 쫄면, 미소라멘, 카레우동,
칼국수, 해물크림파스타 등빵, 과자 녹차카스테라, 슈크림빵, 찐방, 샌뒤위치, 햄버거 등 차, 음료, 유제품 과일류 주스, 커피류, 우유류, 채소주스, 탄산음료 등 견과류 호두, 캐슈넛, 아몬드, 아보카도, 땅콩, 마카다미아,
피스타치오, 잣, 피칸, 햄프씨드, 브라질너트 등양념, 소스 참기름, 장류, 들기름, 들깨가루, 고추장, 핫소스,
홀스래디쉬소스, 히비스커스차, 칠리소스, 코코넛오일, 등과일 수박, 단감, 연시, 참외, 밀감, 천도복숭아, 포도,
키위, 곶감, 딸기, 람부탄, 배, 살구, 앵두, 오렌지 등채소 단호박, 쪽파, 콜라비, 양상추, 군고구마, 군밤, 깻잎,
마늘, 토마토, 치커리, 파프리카, 양배추, 등
필요성
- 국내 인공지능 기술의 활성화를 위해서는 무엇보다 기계학습에 활용할 다양한 패턴의 고품질 이미지 데이터 확보가 중요.
- 이미지 인식 기술은 사람보다 더 정확해지고 있지만, 문제는 AI가 그만큼 많은 양의 데이터를 학습해야만 하고, 사람은 몇 장의 사진만으로도 어떤 사물인지 쉽게 학습할 수 있는데, 현재의 AI는 다량의 사진을 통해 학습해야 인식 성능이 높다.
- 기존 식단관리 플랫폼은 수기로 자신이 섭취한 음식들을 찾아서 선택하거나 직접 입력해야 하는 데 비해 당사의 플랫폼은 음식 이미지를 촬영하여 그식에 대한 기본 영양정보(단백질, 탄수화물, 지방, 칼로리, 당)와 음식의 기본 재료 항목을 제공한다. 식이조절, 식단관리 플랫폼을 활용하고 싶어도 수기로 입력하는 방식에 어려움을 느끼는 노년층 또는 입력에 불편함을 느끼는 집단에서 더 수월하게 서비스를 활용할 수 있게 됨.
데이터 구조
-
데이터 포맷
- 이미지
a) 포맷 : jpeg, png
b) 최저해상도 : 720dpi이상, HD급 이상(90만화소 이상), 해상도: 1,280 x 720 이상
- 데이터 셋
a) 종류 : 바운딩 박스, 향후제공 (폴리곤 세그멘테이션, 서피스 마스킹 , 뎁스 프리딕션)
b) 이미지 수량 : 300만주
c) JSON 수량 : 300만개
d) 작업폴더 수량 : 500여개
e) 폴더당 구성 : 카데고리\image(.jpg or .png) 500~6000장 + (json or xml) 1개
- 레이블링 텍스트
a) 특별한 규격은 없고 정제 이후에 이미지 파일과 쌍(pair) 을 이루도록 align
특별한 규격은 없고 데이터구축 단계 후 이미지와 JSON 파일이 쌍(pair) 을 이루도록 align
b)공공 데이터(식품 영양성분 Database)를 활용하여 분석한 식재료에 대해 열량, 탄수화물, 단백질, 지방 등의 성분함량 DB 음식사진 카테고리별 메타정보(에너지, 탄수화물, 지방, 단백질, 당류)를 구축.
c)카테고리별로 사용된 레시피 자료와 식품 별 100g 메타정보를 활용하여 1인 1회분량에 대한 메타 정보(에너지, 탄수화물, 단백질, 지방)를 계산하여 구축하였음. - 어노테이션 포맷
내용 이름 타입 필수 요소 데이터셋명 Code Name string Y 음식이름 Name string Y 이미지 너비 W Number Y 이미지 높이 H Number Y 파일포맷 File Format string Y 대분류 Cat 1 Number Y 중분류 Cat 2 Number Y 소분류 Cat 3 Number Y 미소분류 Cat 4 Number N annotation 유형 Annotation Type string Y 라벨링 영역 Point (x,y) Number Y class 정보 Label Number Y 정량 Serving Size Number N 촬영각도 Camera Angle Number N 방위각도 Cardinal Angle Number N 용기색상 Color of Container Number N 용기재질 Material of Container Number N 조도 Illuminance Number N
-
데이터셋 구축 담당자
수행기관(주관) : 호서대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 임대환 1566-7454 [email protected] · 데이터 구축 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 지디엠홀딩스 · 데이터 수집(크라우드소싱 활용)
· 데이터셋 구축에스엔시랩 · 데이터 수집(크라우드소싱 활용)
· AI 요약모델을 활용한 서비스 앱/관리자 웹 개발알티데이텀 · AI학습 엔진 개발 및 음식 데이터셋 학습파일 구축 아임헬스케어 · 데이터 수집 및 서비스 백앤드 검증
· 결과물 검수 및 검증데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 임대환(호서대학교 산학협력단) 1566-7454 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.