-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-13 신규 샘플데이터 개방 2022-07-12 콘텐츠 최초 등록 소개
저작권 포함 미디/가사파일 구매하여 발라드/R&B, 락/팝, 트로트 장르를 대상으로 1,500곡을 18명의 가수에게 분배되어 총 4,500개의 음성 데이터를 구축.
구축목적
가수의 목소리를 학습해 새로운 가창 데이터를 생성할 수 있는 가창합성 인공지능 모델을 훈련하기 위한 데이터셋
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 데이터 형식 wav 데이터 출처 한국의 가요 라벨링 유형 전사(음성) 라벨링 형식 JSON, Midi 데이터 활용 서비스 가상 가수의 가창 합성 데이터 구축년도/
데이터 구축량2021년/4,681개 -
1. 데이터 구축 규모
구분 구분 성과목표(개) 구축실적(개) 달성율 데이터셋 발라드 / R&B 1,500 1,560 104.00% 록 / 팝 1,500 1,560 104.00% 트로트 1,500 1,561 104.10% 학습모델 평가지표(MOS) 3.4 이상 4.52 2. 데이터 분포
2. 데이터 분포 다양성 항목 지표 실적 (곡 수) 성별 남 2,400 여 2,281 연령 20대 1,591 30대 1,563 40대 이상 1,527 장르 발라드/R&B 1,560 록 1,560 트로트 1,561 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 모델 적용 방안
가. 모델 선정방안
1) 인공지능 학습모델 선정 기준 및 고려사항- 본 AI 데이터는 Singing Voice Synthesis 모델링에 활용하기 위한 것으로, 참여기관이 보유한 데이터와 동일한 구조의 가창 데이터를 수집하여 활용해야 함.
- 가창 데이터이기 때문에 고음질 생성이 가능해야하며, 형식에 제한이 없도록 다양한 vocoder 활용이 가능해야 함.
- 사람마다 가창의 특성이 다르기 때문에, 다양한 음성/가창 특징을 활용할 수 있어야 함.
2) 모델 선정 절차
- AI 모델에 대한 리서치 수행
- 선행 연구 및 알고리즘 자료 검토
- AI 모델에 대한 모델링 실시
- AI 모델 성능 및 특성 분석
- AI 모델 간 상호 비교 후 선정
나. 모델 적합성 검토
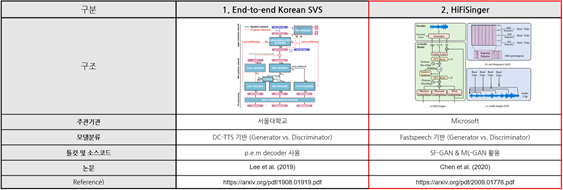
[1] https://arxiv.org/pdf/2009.01776.pdf
[2] Chen et al. (2020), HiFiSinger: Towards high-fidelity neural singing voice synthesis다. 모델 선정 및 적용방안
1) AI 모델 선정 후보 (Singing Voice Synthesis 엔진)
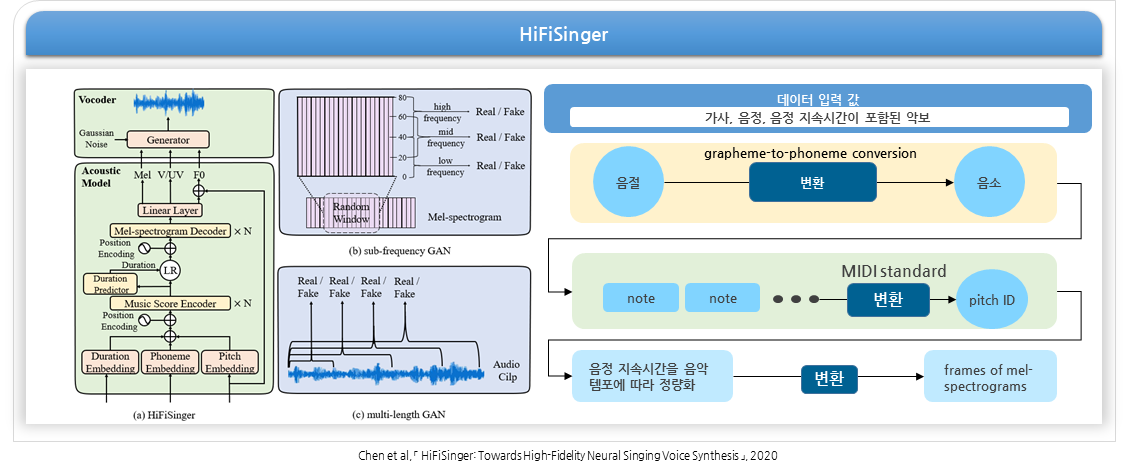
- 선정 모델: HiFiSinger
- 선정 이유
(1) 경쟁 알고리즘에 비해 다양한 음성 특징 활용이 가능하고, 고음질 노래 생성이 가능한 HiFiSinger 모델을 선정

2) HiFiSinger를 적용한 참여 기관의 엔진
- 가창 데이터 모델링을 위한 연구 활동 진행
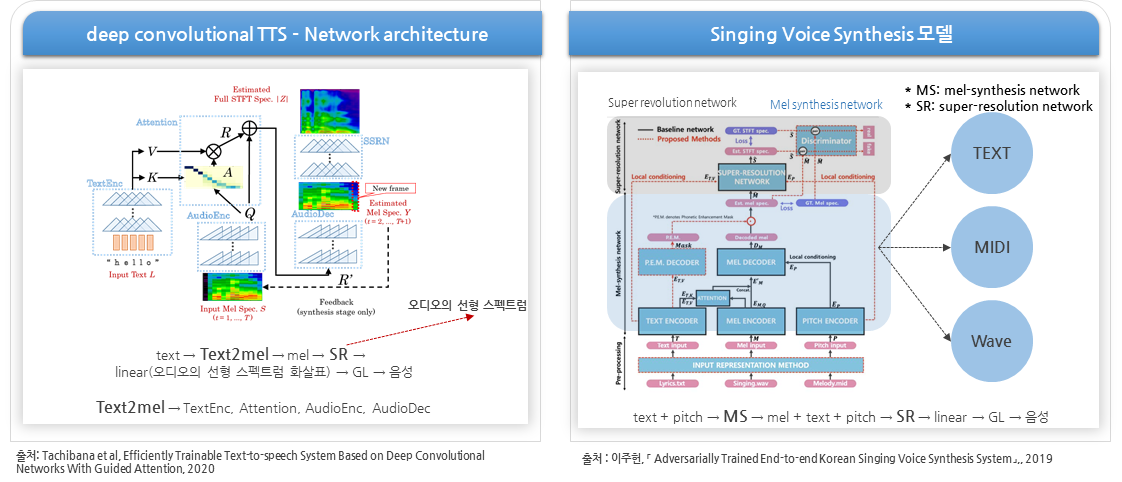
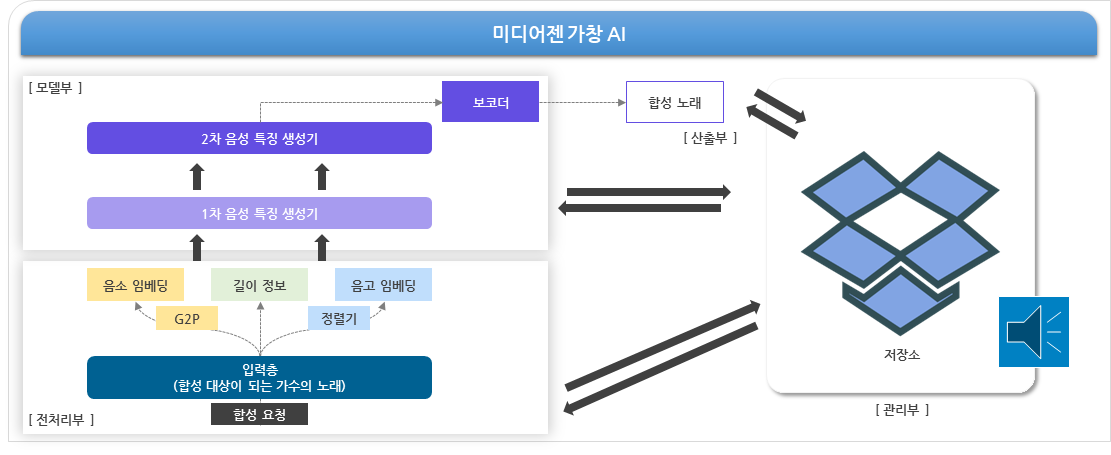
- 미디어젠 자체 개발 가창 AI 모델 구조
- 합성 가수의 가창력 평가 방안
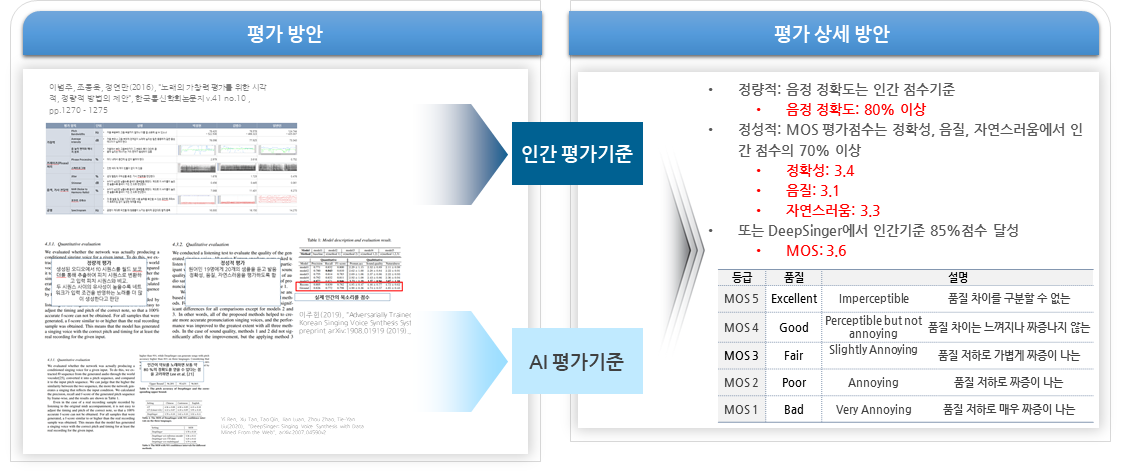
2. 향후 활용 분야 및 활용 서비스
- 보이스-이모지 서비스: 짧은 미디 탬플릿에 가사를 수정해 음악 클립 공유

- 작곡 어시스턴트: 곡에 어울리는 목소리를 바꿔가며 확인

-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 가창 합성(SVS) Speech Synthesis HiFiSinger+PWGAN MOS 3.4 점 4.52 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
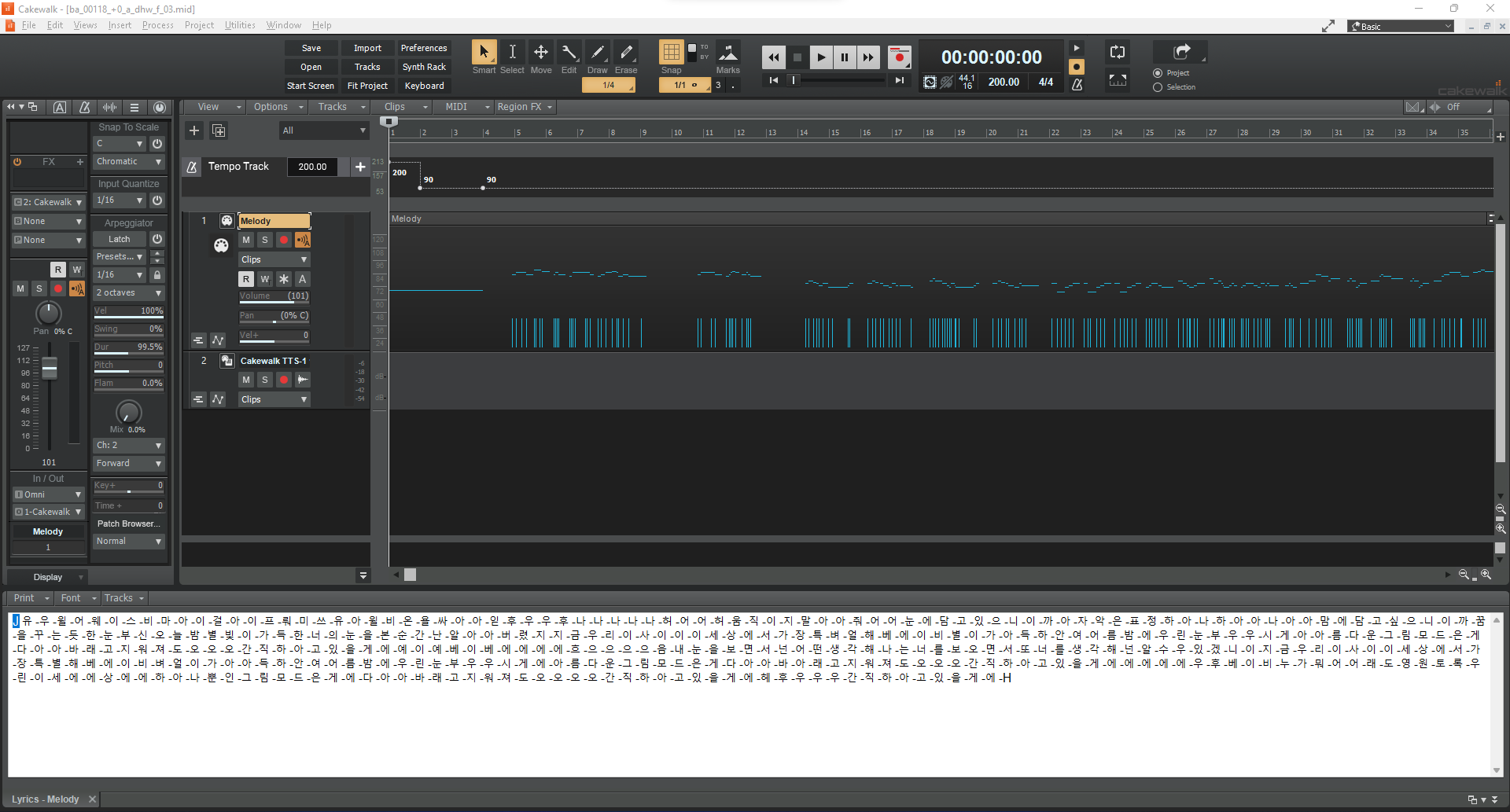
데이터 설명서 다운로드 구축활용가이드 다운로드미디 파일 예제
2. 라벨링 데이터 구성
대분류 대분류 속성 표기 의미 타입 필수여부 기본 정보 (DB_Info) Language 언어 String Version 버전 String Y ApplicationCategory 응용 분야 String NumberOfSpeaker 가창자 코드 String Y NumberOfUtterance 발화 수 String DataCategory DB종류 String RecordingDate 녹음날짜 String FillingDate 수정날짜 String RevisionHistory 키 변경정보 String Y Distributor 수행기관 String 음성 정보 (Wave_Info) SamplingRate 주파수 String Y NumberOfBit 비트 수 String Y ByteOrder 바이트정보 String EncodingLaw 인코딩방식 String Y NumberOfChannel 채널 수 String Y 전사 정보 (Label_Info) LabelText 텍스트 전사 String Y 화자 정보 (Speaker Info) SpeakerName 화자 이름 String Y Gender 성별 String Y Age 나이 String Y Genre 지역 String Y Professional 준프로/아마추어 String Y Skill 방언 String Y 음악 정보 (Song_Info) SongNumber 곡 번호 String Y SongGenre 장르 String Y 파일 정보 (File_Info) FileCategory 파일 종류 String Y FileName 파일 이름 String DirectoryPath 파일 위치 String HeaderSize 헤더 크기 String FileLength 파일 길이 String FileFormat 파일 포맷 String Y NumberOfRepeat 반복 차수 String TimeInterval 녹음 주기 String 기타 정보 (Miscellaneous_Info) QualityStatus 품질 상태 String Y
3. 라벨링데이터 실제예시{
"기본 정보":{
"Language":"KOR",
"Version":"nia2021_1.0",
"ApplicationCategory":"N/A",
"NumberOfSpeaker":"07",
"NumberOfUtterance":"1",
"DataCategory":"sing",
"RecordingDate":"44415",
"FillingDate":"N/A",
"RevisionHistory":"0",
"Distributor":"MediaZen"
},
"음성 정보":{
"SamplingRate":"48000",
"NumberOfBit":"16",
"ByteOrder":"N/A",
"EncodingLaw":"Wave",
"NumberOfChannel":"1"
},
"전사 정보":{
"LabelText":"휴식같은 친구",
"Lyrics":"내 좋은 여자"
},
"화자 정보":{
"SpeakerName":"lsm",
"Gender":"f",
"Age":"03",
"Genre":"ro",
"Professional":"s",
"Skill":"ro"
},
"음악 정보":{
"SongNumber":"02814",
"SongGenre":"락"
},
"파일 정보":{
"FileCategory":"Audio",
"FileName":"ro_02814_+0_s_lsm_f_03",
"DirectoryPath":"/path/to/the/folder",
"HeaderSize":"N/A",
"FileLength":"N/A",
"FileFormat":"PCM",
"NumberOfRepeat":"1",
"TimeInterval":"N/A"
},
"기타 정보":{
"QualityStatus":" Good"
}
} -
데이터셋 구축 담당자
수행기관(주관) : 미디어젠㈜
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 윤종성 수석 02-6429-7100 [email protected] 데이터 구축, AI 모델링 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜비디 공정관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 윤종성 수석 02-6429-7100 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.