※온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-13 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-07-13 콘텐츠 최초 등록 소개
후두 음성 질환 진단 및 분류를 위한 정상 및 병적 음성에 대한 데이터셋으로, 보건복지부 가이드라인에 의거하여 원시 음성 데이터(WAV)를 멜-스펙트럼 수치 행렬 데이터(CSV)로 변환하여 제공되는 1,102건의 정상 및 병적 음성 데이터 셋
구축목적
음성 질환의 분류 학습을 위한 음성 데이터에 대한 스펙트럼 변환 수치 데이터셋
-
메타데이터 구조표 데이터 영역 헬스케어 데이터 유형 오디오 데이터 형식 CSV 데이터 출처 의료기관 라벨링 유형 음절 구간 및 전사 라벨링 형식 JSON 데이터 활용 서비스 음성질환 진단 및 감별을 목적으로 하는 헬스케어 AI 서비스 데이터 구축년도/
데이터 구축량2021년/1,102건 -
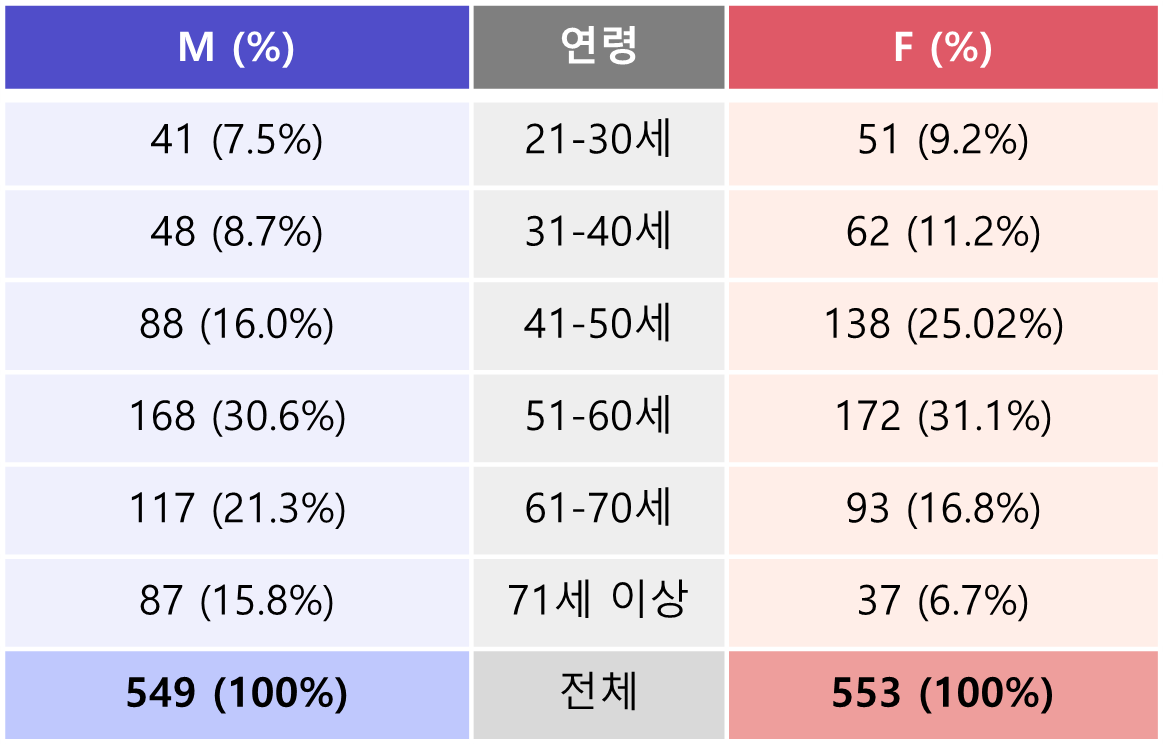
총 1,102건의 데이터
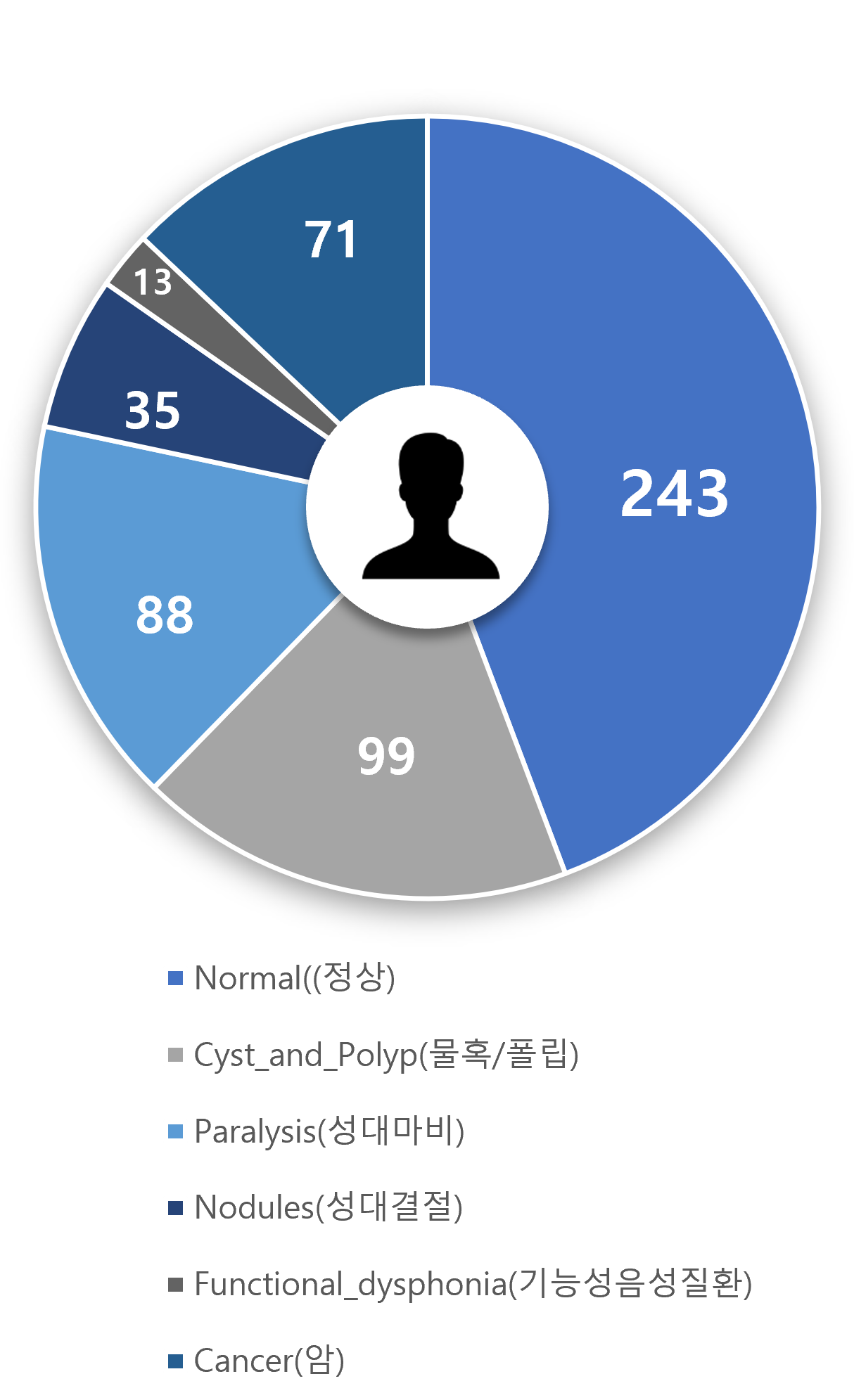
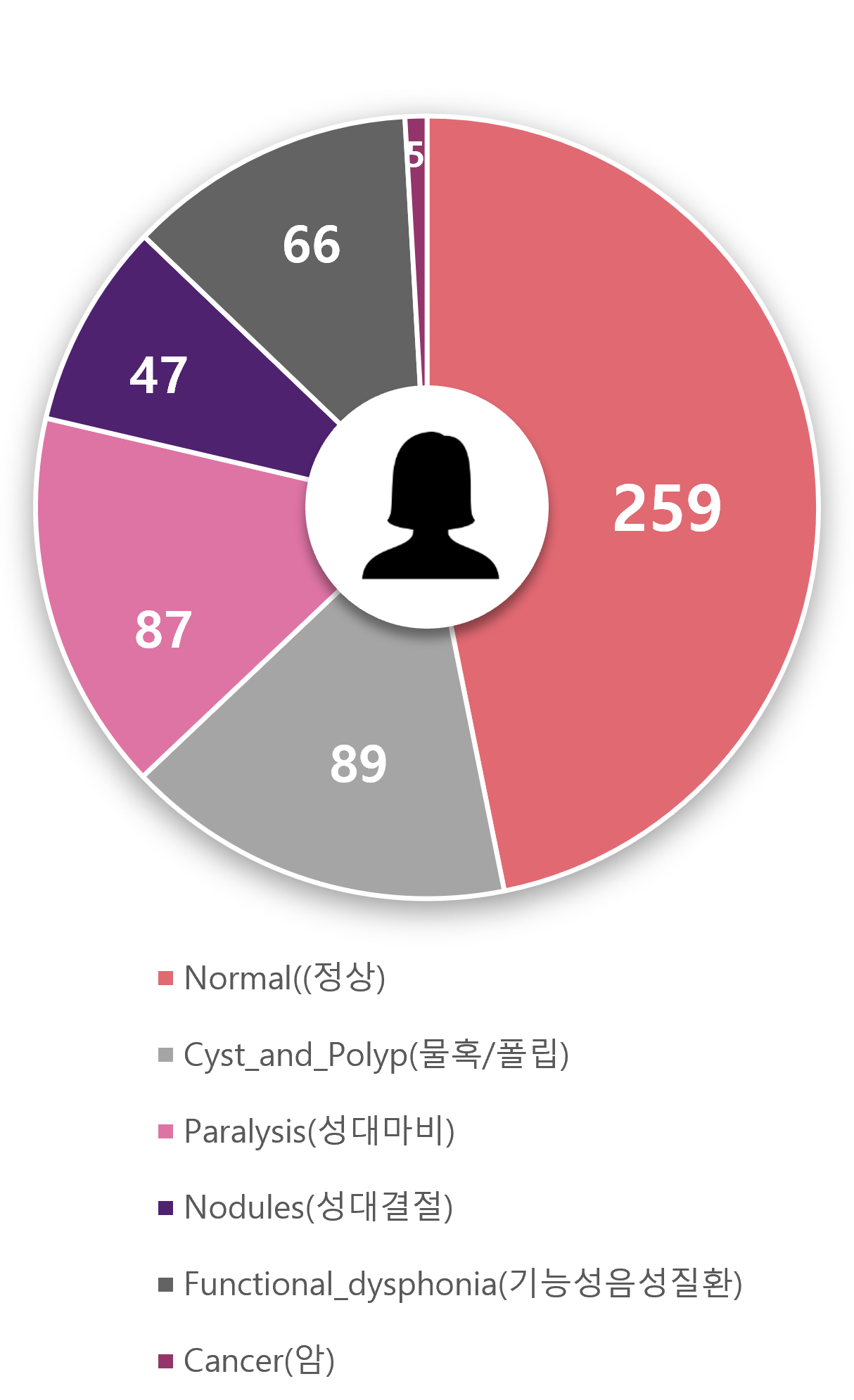
나이별 분포 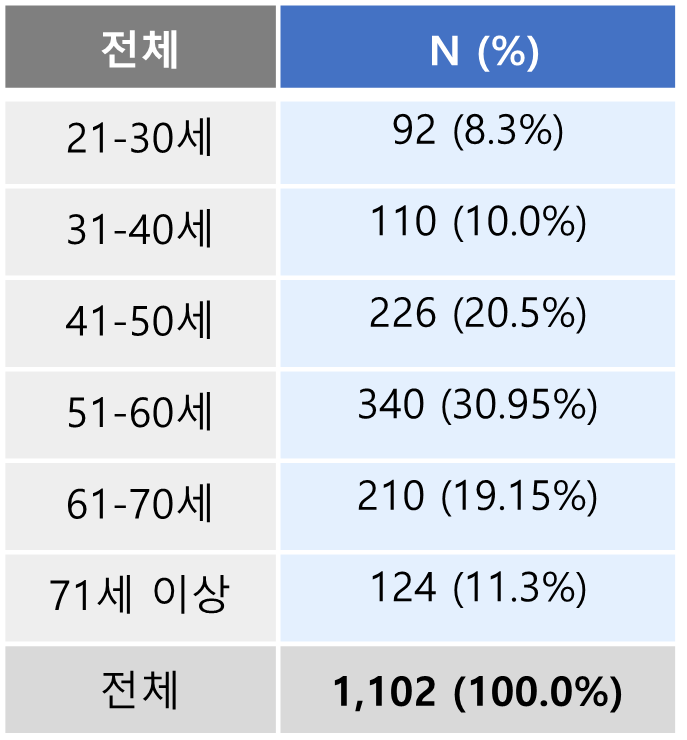
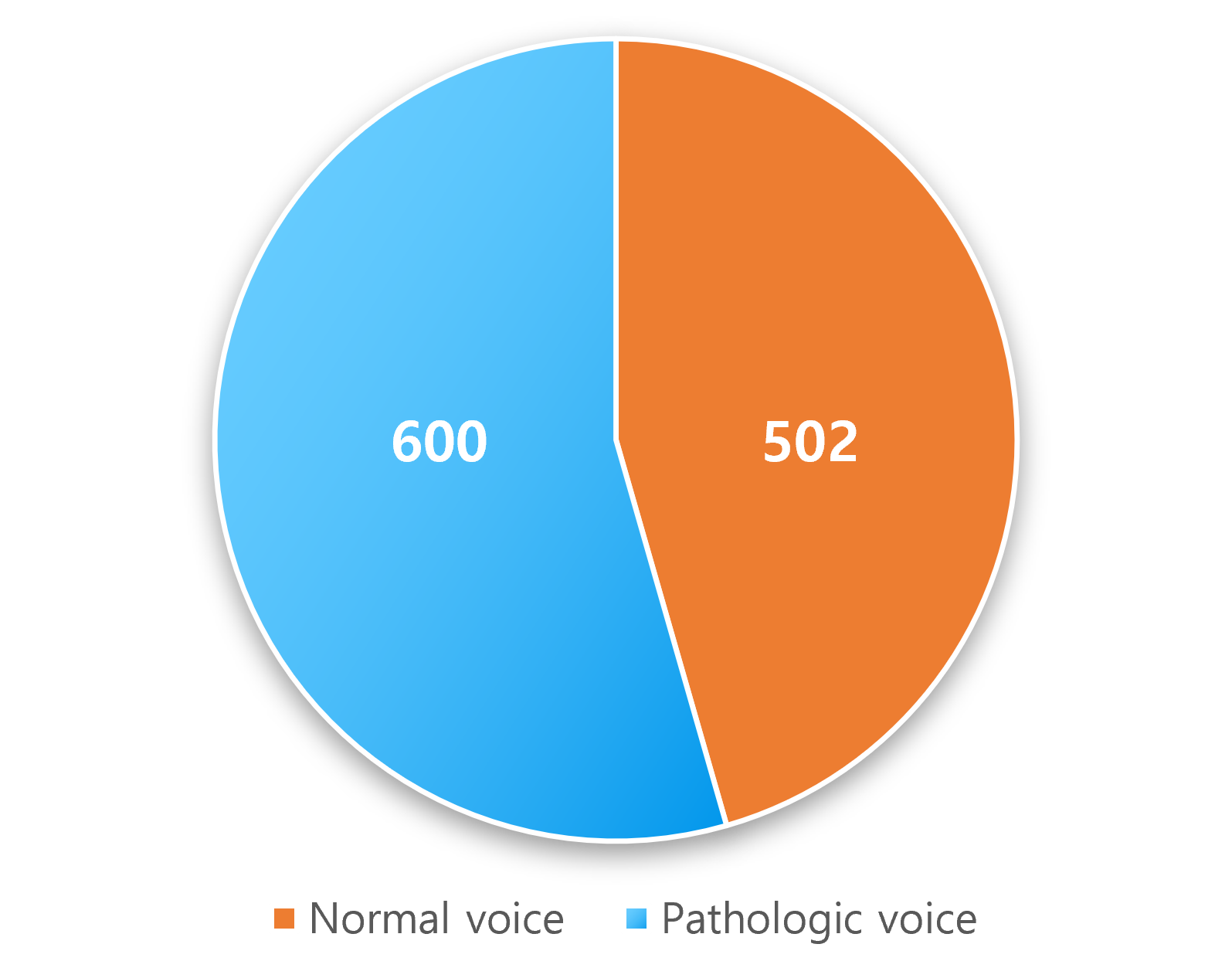
나이별 분포 정상 502건 / 병적음성 600건
병적 음성 600건은 세부적으로 물혹/폴립 188건, 성대마비 175건, 성대결절 82건, 기능성 음성질환 79건, 후두암 76건으로 분류됨
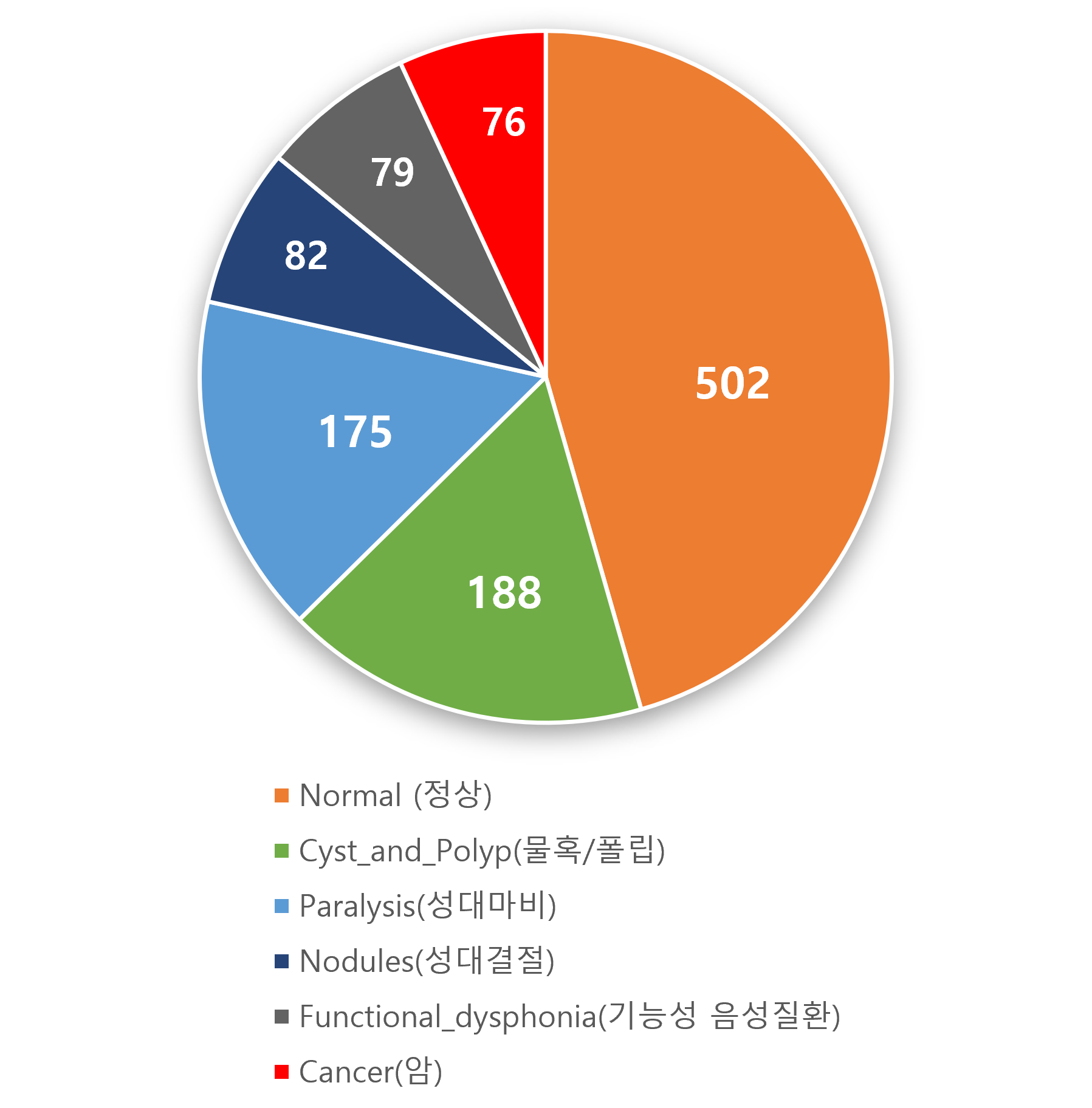
기능성 음성질환의 경우 여성에서 비율이 높으며, 후두암의 경우 남성의 비율이 높아, 남녀 간 수치의 차이가 크게 발생. 이는 실제 해당 질환이 특정 성별에서 유의하게 높게 발현되는 현실이 반영임
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드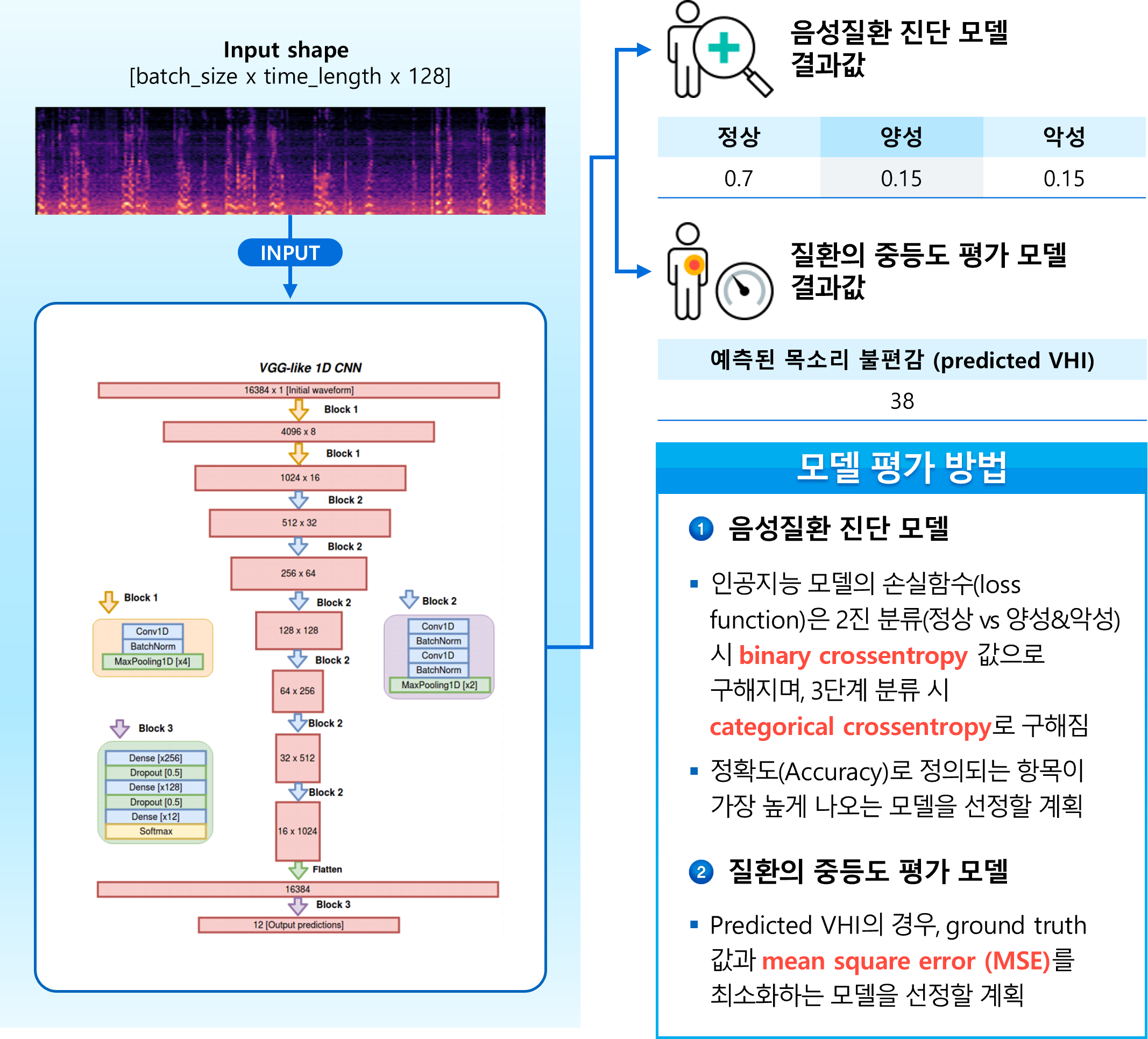
모델 학습
- 음성의 스펙트럼 변환 데이터는 2차원 배열로 구성되어있어, 이미지로 인식하여 인공지능 모델을 학습시킬 수 있음.
- 그 예측 결과물은 정상/병적 음성 분류 뿐 아닌 병적 음성 내 세부 질환을 카테고리로 분류할 수 있음
서비스 활용 시나리오
- 음성을 이용한 후두 질환 스크리닝
- 의료기관에서 질환 치료 후 증상 재발 및 치료 경과 평가
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 진단 분류 모델 (정상 음성 vs 병적 음성) Audio Classification Convolution 2D Accuracy 80 % 94 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드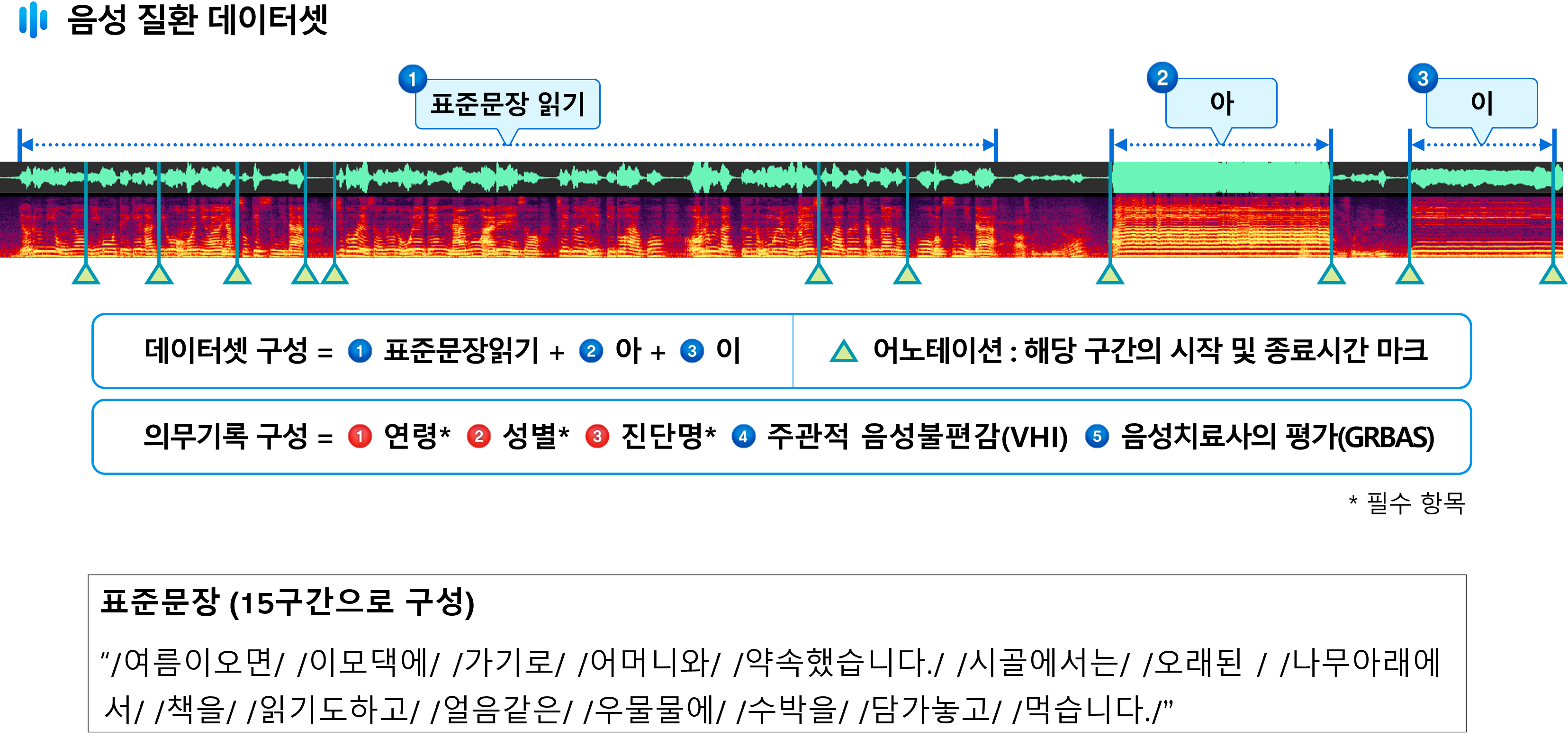
총 1,102개의 데이터 (각 데이터는 3개의 파일로 구성됨)
1. 표준 문장, /아/, /이/ 모음으로 구성된 음성데이터로부터 멜-스펙트럼 변환된 원천데이터(CSV)
2. 음절 구간을 나눈 어노테이션(JSON)
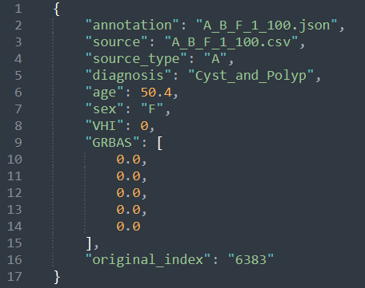
3. 비식별화된 임상 정보로 구성된 의무기록 데이터(JSON)1. 표준 문장, /아/, /이/ 모음으로 구성된 음성데이터로부터 멜-스펙트럼 변환된 원천데이터(CSV)
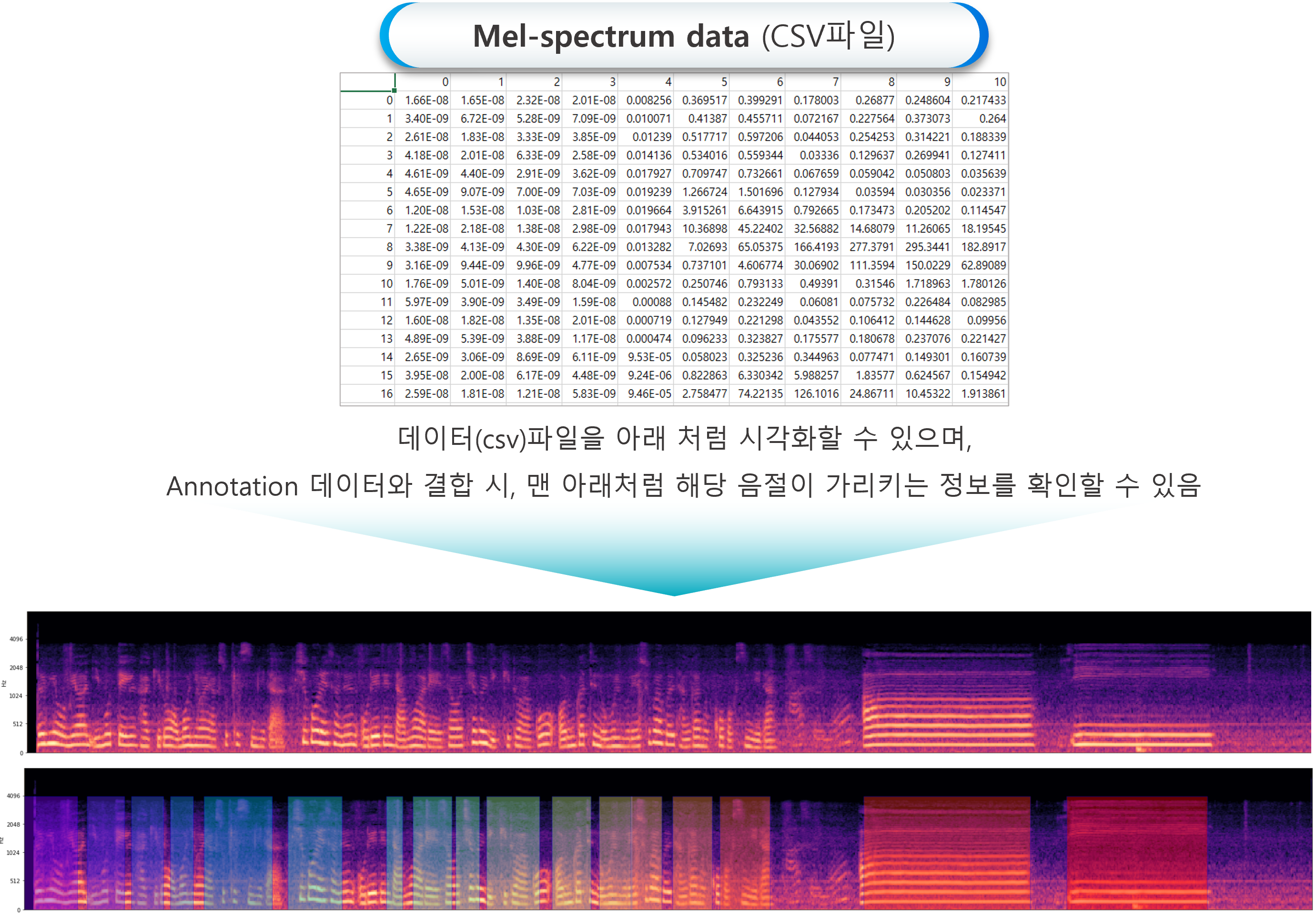 2. 음절 구간을 나눈 어노테이션(JSON)
2. 음절 구간을 나눈 어노테이션(JSON)2. 음절 구간을 나눈 어노테이션(JSON) 구분 항목 타입 필수 여부 설명 범위 비고 1 data_idx String O 어노테이션 작업 내부 고유 코드 2 value Array M 17개로 구성된 음절 배열 2-1 ~ 2-6의 값이 총 17개 존재함 2-1 value[].timestamp Number O 작업 일시정보 2-2 value[].token_no String M 음절 번호 1~17 “1”, “17” 등 문자열로 기록됨 1.여름이오면 2.이모댁에 3.가기로 4.어머니와 5.약속했습니다 6.시골에서는 7.오래된 8.나무아래에서 9.책을 10.읽기도하고 11.얼음같은 12.우물물에 13.수박을 14.담가놓고 15.먹습니다 16.아 17.이 2-3 value[].token_skip String M 음성 정보 존재 여부 “normal”, “skip” 2개 중 하나 2-4 value[].token_pronounce String M 음성 발음 정상 여부 “normal”, “abnormal” 3개 중 하나 “skip” 2-5 value[].startFrame Number M 멜스펙트럼데이터 시작 프레임값 0-9999 2-6 value[].endFrame Number M 멜스펙트럼데이터 종료 프레임값 0-9999 3 check_end_date String O 검수 시간 4 check_id String O 검수자 ID 5 work_end_date String O 작업 시간 6 work_id String O 작업자 ID 7 metadata String M 메타데이터 파일명 8 source String M 원천데이터 파일명 9 original_index String M 원시 데이터(미제출) 파일의 인덱싱 번호 “3845” 5자리 숫자로 구성된 문자열 3. 비식별화된 임상 정보로 구성된 의무기록 데이터(JSON)
3. 비식별화된 임상 정보로 구성된 의무기록 데이터(JSON) 구분 항목 타입 필수 여부 설명 범위 비고 1 annotation String M 어노테이션파일명 2 source String M 원천데이터 파일명 3 source_type String M 음성 제출 기관 식별자 “A”,“B”,“C” 3개 중 하나 4 diagnosis String M 진단명 "Cancer", 6개 중 하나 "Cyst_and_Polyp", "Functional_dysphonia", "Nodules", "Normal", "Paralysis 5 age Number M 나이 6 sex String M 성별 “M”,“F” 2개 중 하나 7 VHI Number O 주관적 음성 불편감 -1 ~ 120 -1로 입력될 경우 NULL값을 의미 8 GRBAS Number Array (float) O 검사자 평가 음성 불편감 -1 ~ 5 -1로 입력될 경우 NULL값을 의미 9 original_index String M 원시 데이터(미제출) 파일의 인덱싱 번호 “3845” 5자리 숫자로 구성된 문자열 어노테이션 데이터 예시 익명화된 의무기록 데이터 예시 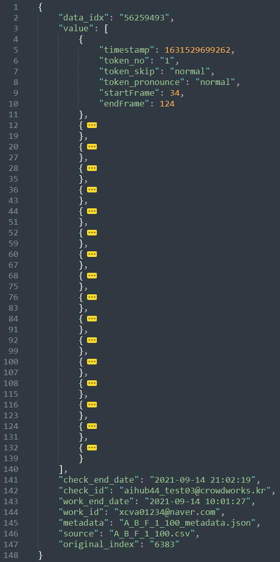
-
데이터셋 구축 담당자
수행기관(주관) : 서울대병원
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정은재 / 김인걸 02-2072-4676 [email protected] 사업 전체 업무 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 국립암센터 자료 수집 및 정제 보라매병원 자료 수집 및 정제 ㈜크라우드웍스 데이터 어노테이션 및 툴 제작 ㈜EPI랩 데이터 검증 및 해커톤 진행 ㈜노웨어소프트 유효성 검증을 위한 인공지능 모델 개발 인포뱅크㈜ 시범서비스 구축 및 시연
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.