-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-07-17 원천데이터 수정 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-13 신규 샘플데이터 개방 2022-07-12 콘텐츠 최초 등록 소개
자체적으로 수집한 원시데이터를 기반으로 최대한의 음소 범위와 다양한 화자가 포함될 수 있도록 3,400명 이상의 일반인 화자가 25개의 대본으로 2,000~2,400개의 문장을 녹음하여 총 10,152시간의 음성 데이터를 확보
구축목적
소량의 녹음 데이터만으로 개인의 음성을 합성할 수 있는 음성 합성기 구축을 위한 음성합성 데이터셋
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 데이터 형식 WAV 데이터 출처 신규 구축 데이터 라벨링 유형 전사(음성) 라벨링 형식 JSON 데이터 활용 서비스 다화자 음성 합성기, 한국어 음성 합성 연구, 개인화 음성 합성 서비스, 다화자 음성 합성 서비스 개발, 일상 대화 음성 합성 기술, 로봇, 인공지능 스피커, 키오스크, 가상 아바타 서비스, 게임, 감정 테라피, 재활, 돌봄 서비스 분야 등 데이터 구축년도/
데이터 구축량2021년/10,152시간 -
1. 데이터 구축 규모
1. 데이터 구축 규모 구분 연령대 총 데이터 수집 성별에 따른 수집 내역 남성 여성 인원(명) 시간(h) 비율(%) (명) 시간(h) (명) 시간(h) 데이터
수집
시간
및
인원10대 276 841 8.30% 119 448 157 393 20대 1,195 3,692 36.40% 641 2,336 554 1,356 30대 894 2,559 25.20% 384 1,301 510 1,259 40대 599 1,597 15.70% 170 520 429 1,077 50대 420 1,138 11.20% 108 314 312 824 60대~ 111 325 3.20% 25 84 86 241 합계 3,495 10,152 100.00% 1,477 5,002 2,048 5,150 2. 데이터 분포
2. 데이터 분포 성별 분포 남자 1,447명 / 41% 여자 2,048명 / 59% 연령 분포 10대 276명/841시간/8.3% 20대 1,195명/3,689시간/36.3% 30대 894명/2,563시간/25.2% 40대 599명/1,597시간/15.7% 50대 420명/1,138시간/11.2% 60대 111명/325시간/3.2% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 모델 선정
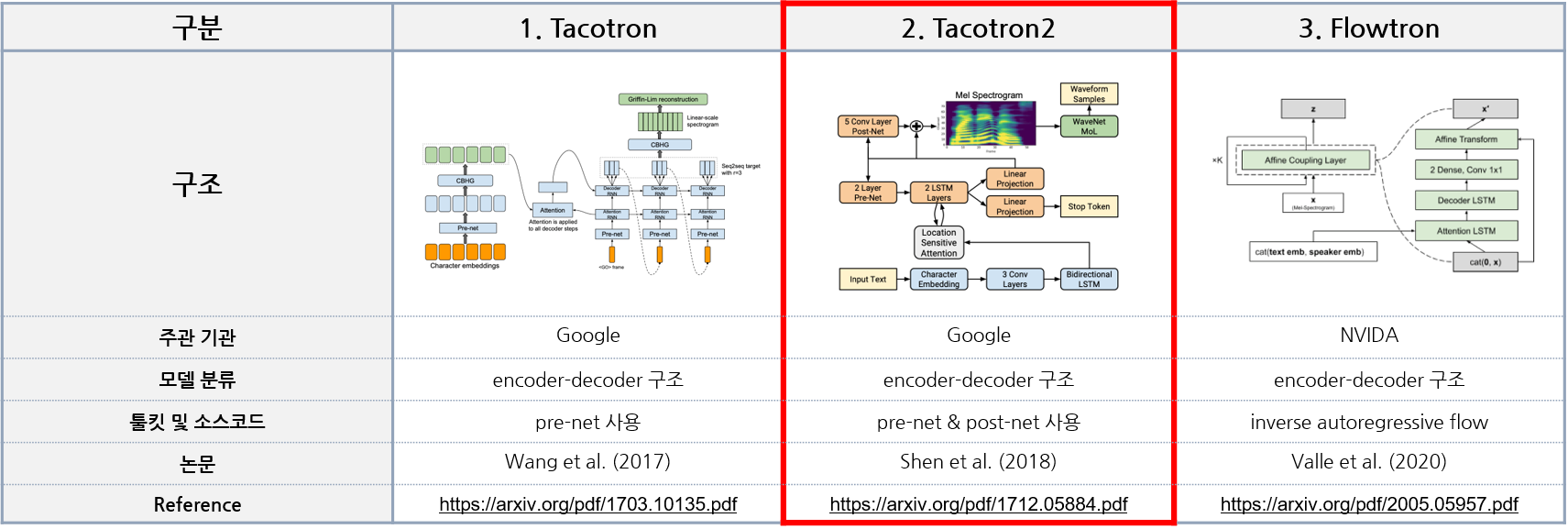
- 선정 모델 : Tacorton2
- 선정 사유 : 경쟁 알고리즘에 비해 고음질의 안정적인 음성을 생성함

- 모델 적합성 검토
 [1] https://github.com/NVIDIA/tacotron2
[1] https://github.com/NVIDIA/tacotron2
[2] https://arxiv.org/pdf/1712.05884.pdf
[3] Shen et al. (2018) Natural TTS synthesis by conditioning wavenet on mel spectrogram predictions.
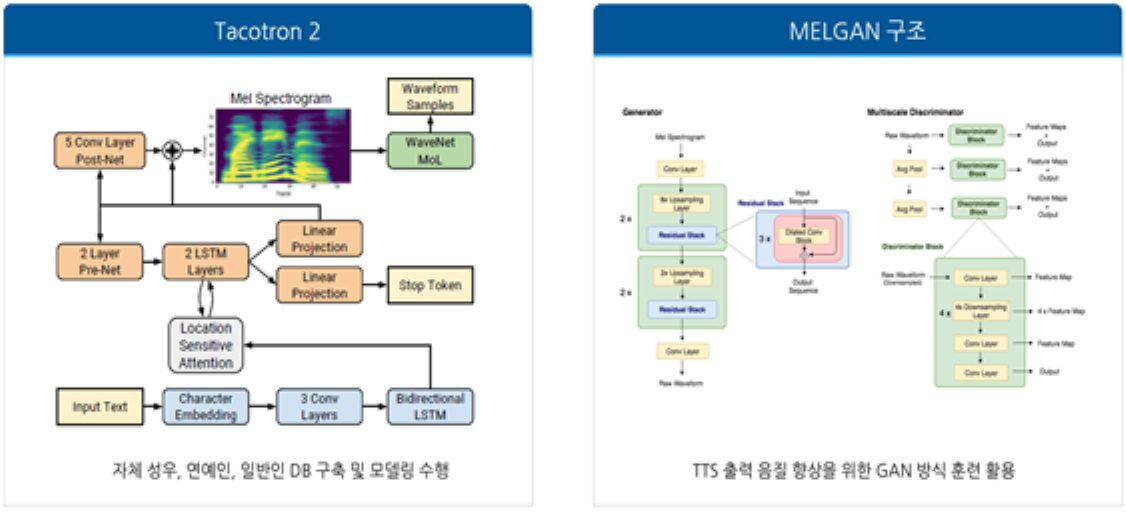
2. Tacotron2 기반 TTS 엔진
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 시청각 음성인식 모델 Speech Recognition Transformer CER 25 % 13.85 % 2 음성합성 Speech Synthesis Transformer MOS 3.6 점 4.09 점 3 시청각 음성인식 모델 Speech Recognition Transformer WER 50 % 20.21 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- 원천데이터 포맷 예시
1. 데이터 포맷 파일명 0001_G2A2E7_KMJ_001111.wav 발화문장 주변 관광지를 검색합니다. 언어 한국어 파일크기/길이 221KB / 2.36초 감정 중립 감성 중립 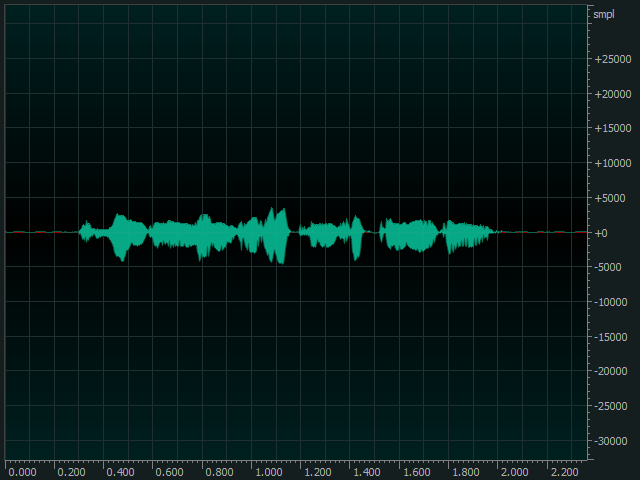
- JSON 형식
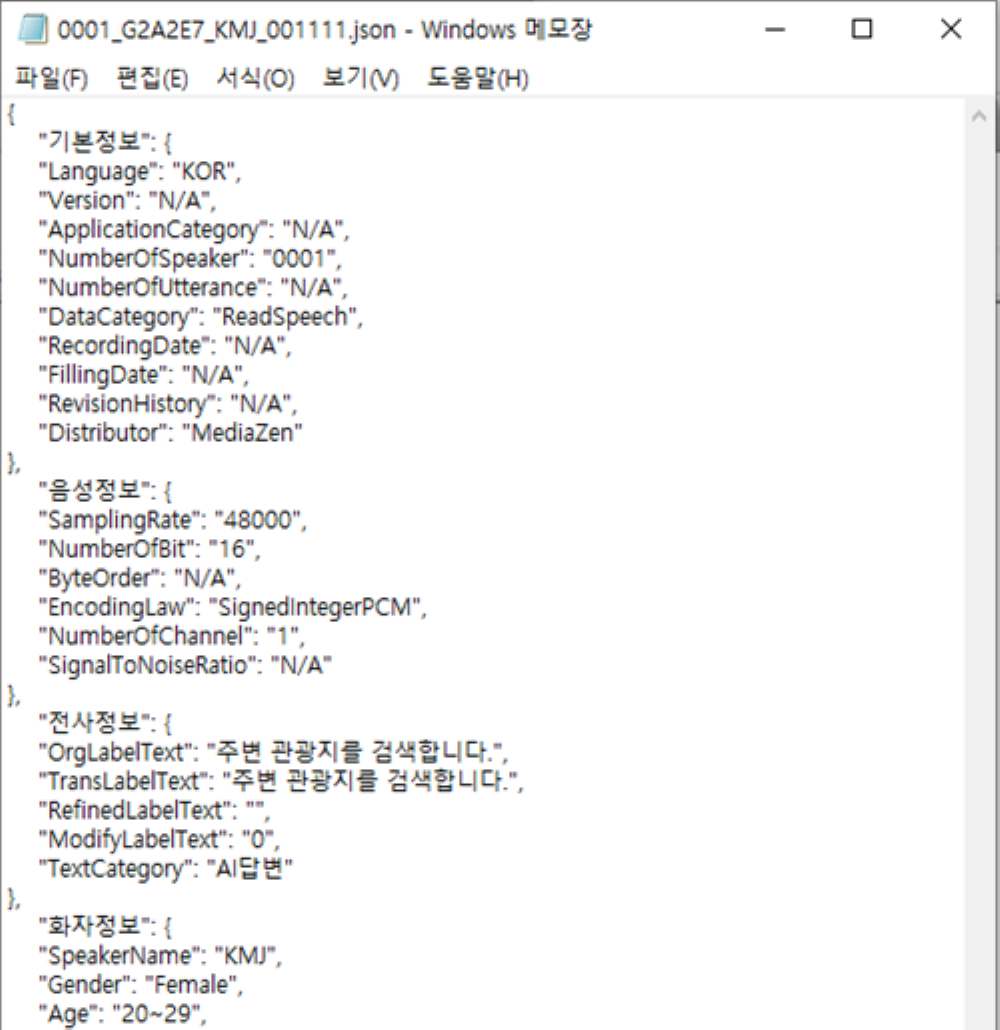
2. 데이터 구성
2. 데이터 구성 대분류 속성 표기 의미 타입 필수여부 기본 정보 (DB_Info) Language 언어 String Y Version 버전 String ApplicationCategory 응용 분야 String NumberOfSpeaker 발성화자 수 String Y NumberOfUtterance 발화 수 String DataCategory DB종류 String Y RecordingDate 녹음날짜 String FillingDate 수정날짜 String RevisionHistory 수정기록 String Distributer 수행기관 String Y 음성 정보 (Wave_Info) SamplingRate 주파수 String NumberOfBit 비트 수 String ByteOrder 바이트정보 String EncodingLaw 인코딩방식 String NumberOfChannel 채널 수 String SignalToNoiseRatio SNR String 전사 정보 (Label_Info) OrgLabelText 텍스트 전사 String Y TransLabelText 텍스트 전사 String Y RefinedLabelText 텍스트 전사 String ModifyLabelText 수정 정보 String Y TextCategory 텍스트 정보 String Y 화자 정보 (Speaker Info) SpeakerName 화자 이름 String Y Gender 성별 String Y Age 나이 String Y Region 지역 String Y Dialect 방언 String Emotion 감정상태 String Y Sensitivity 감성상태 String Y 환경 정보 (Environment_Info) RecordingEnviron 녹음 환경 String Y NoiseEnviron 노이즈 환경 String Y RecordingDevices 녹음 장치 String Y 파일 정보 (File_Info) FileCategory 파일 종류 String Y FileName 파일 이름 String Y DirectoryPath 파일 위치 String Y HeaderSize 헤더 크기 String FileLength 파일 길이 String FileFormat 파일 포맷 String NumberOfRepeat 반복 차수 String Y TimeInterval 녹음 주기 String Distance 녹음 거리 String 기타 정보 (Miscellaneous_Info) QualityStatus 품질 상태 String SpeechStart 음성시작시간 String SpeechEnd 음성 끝시간 String 3. 어노테이션 포맷
3. 어노테이션 포맷 구분 어노테이션 항목명 타입 필수여부 설명 범위 비고 1 DB_Info Object 기본정보 1.1 Language string Y 언어 1.2 Version string 버전 1.3 ApplicationCategory string 응용 분야 1.4 NumberOfSpeaker string Y 발성화자 수 1.5 NumberOfUtterance string 발화 수 1.6 DataCategory string Y DB종류 1.7 RecordingDate string 녹음날짜 1.8 FillingDate string 수정날짜 1.9 RevisionHistory string 수정기록 1.1 Distributer string Y 수행기관 2 Wave_Info Object 음성정보 2.1 SamplingRate string 주파수 2.2 NumberOfBit string 비트수 2.3 ByteOrder string 바이트정보 2.4 EncodingLaw string 인코딩방식 2.5 NumberOfChannel string 채널수 2.6 SignalToNoiseRatio string SNR 3 Label_Info 전사정보 3.1 OrgLabelText string Y 텍스트 전사 3.2 TransLabelText string Y 텍스트 전사 3.3 RefinedLabelText string 텍스트 전사 녹음 진행 시 대본과 다르게 발화한 경우 수정된 내용으로 입력 3.4 ModifyLabelText string Y 수정 정보 녹음 진행 시 대본과 다르게 발화한 경우를 구분하기 위해 “1”로 표시 3.5 TextCategory string Y 텍스트 정보 4 Speaker Info Object 화자정보 4.1 SpeakerName string Y 화자 이름 4.2 Gender string Y 성별 4.3 Age string Y 나이 4.4 Region string Y 지역 4.5 Dialect string 방언 4.6 Emotion string Y 감정상태 기쁨/슬픔/분노/불안/상처/당황/중립
총 7개 대표 감정4.7 Sensitivity string Y 감성상태 감정 별 12~14개 감성 분류
(총 93개 감성) 사용)5 Environment_Info Object 환경정보 5.1 RecordingEnviron string Y 녹음 환경 5.2 NoiseEnviron string Y 노이즈 환경 5.3 RecordingDevices string Y 녹음 장치 6 File_Info Object 파일정보 6.1 FileCategory string Y 파일 종류 6.2 FileName string Y 파일 이름 6.3 DirectoryPath string Y 파일 위치 6.4 HeaderSize string 헤더 크기 6.5 FileLength string 파일 길이 6.6 FileFormat string 파일 포멧 6.7 NumberOfRepeat string Y 반복 차수 6.8 TimeInterval string 녹음 주기 6.9 Distance string 녹음 거리 7 Miscellaneous_Info Object 기타정보 7.1 QualityStaus string 품질 상태 7.2 SpeechStart String 음성 시작 시간 7.3 SpeechEnd String 음성 끝 시간 4. 실제 예시
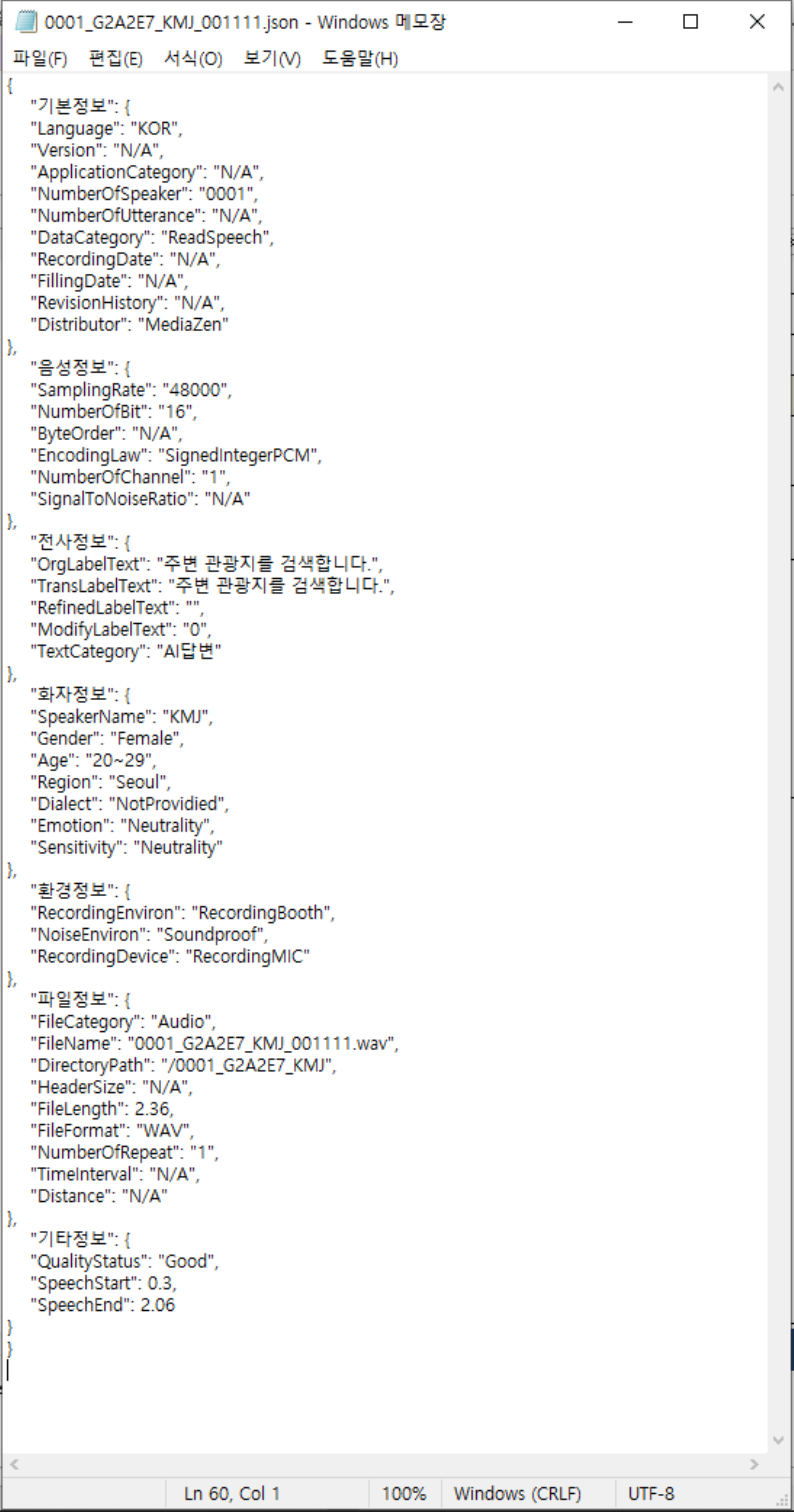
- 원천데이터 포맷 예시
-
데이터셋 구축 담당자
수행기관(주관) : 미디어젠(주)
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 송민규 상무 02-6429-7104 [email protected] · 데이터 설계 · 검수 · 모델링 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜애드사운드 · 데이터 구축
· 데이터 가공
· 데이터 정제
· 검수데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 송민규 상무 02-6429-7104 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.