-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2021-12-03 데이터 추가 개방 1.0 2021-06-30 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-13 신규 샘플데이터 개방 소개
인공지능 기반의 컴퓨터 비전 기술 및 서비스 개발에 활용하기 위해 국내 특성(지리 공간적, 기능적)이 반영된 국내 도심 민간건물, 공공기관, 관광명소, 편의시설 등 국내 도시별 주요 랜드마크 이미지 데이터 구축
구축목적
AI 기술 및 응용서비스 개발에 활용가치가 높은 인공지능 학습용 데이터 구축 및 개방, AI응용 서비스 개발 국내 특성(지리 공간적, 기능적)이 반영된 국내 도심 민간건물, 공공기관, 관광명소, 편의시설 등 국내 도시별 주요 랜드마크 이미지 데이터 구축
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 이미지 데이터 형식 데이터 출처 라벨링 유형 라벨링 형식 데이터 활용 서비스 데이터 구축년도/
데이터 구축량2020년/500만장 이상 -
구축 내용 및 제공 데이터량
- AI 학습용 데이터 구축량
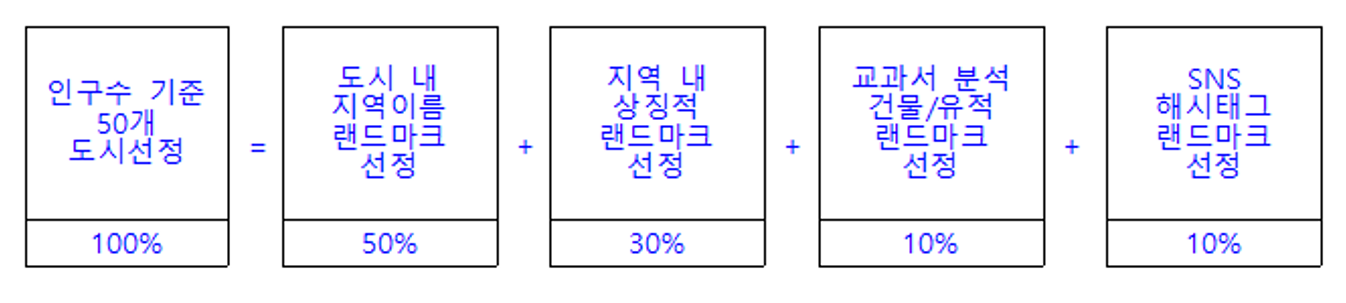
- 전국 50개 도시의 랜드마크(국내 공공기관, 주요 건물, 관광명소, 편의시설 등) 이미지를 구축하되 도시별 500개 랜드마크 각 200장 내외, 총 500만장 이상 이미지 구축
- 인공지능 학습용 데이터 활용 응용서비스‧제품 개발 방안
- 사전학습 모델(Pre-Trained Model) 연구 개발
: 구축된 500만장의 랜드마크 이미지를 활용하여 25,000개의 클래스(50개 도시, 500 랜드마크)를 분류하는 Instance-Level Recognition 모델과 이미지가 주어졌을때 유사 이미지를 판별하는 Retrieval 모델 개발 - 사전학습 모델을 활용한 응용서비스 개발 방안
- Instance-Level Image-classification 모델 개발
- AI 학습용 데이터 구축량
-
-
AI 모델 상세 설명서 다운로드
AI 모델 다운로드 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 이미지 분류 Image Classification ResNet50 + ArcFace GAP 20 % 96 % 2 이미지 검색 Estimation DELF mAP 20 % 98 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2021.12.03 데이터 추가 개방 1.0 2021.06.30 데이터 최초 개방 구축목적
- AI 기술 및 응용서비스 개발에 활용가치가 높은 인공지능 학습용 데이터 구축 및 개방, AI응용 서비스 개발
- 국내 특성(지리 공간적, 기능적)이 반영된 국내 도심 민간건물, 공공기관, 관광명소, 편의시설 등 국내 도시별 주요 랜드마크 이미지 데이터 구축
활용분야
- 인공지능 학습용 데이터를 구축‧개방하고자 하는 기업, 협회, 출연연, 공공기관, 대학 등 민간‧공공 법인 등의 서비스 개발에 활용, 대용량 이미지 검색 및 추상화-레벨 분류 AI 모델 개발(A Large-Scale Instance-level Recognition and Image Retrieval), 랜드마크 객체 검출 AI 모델에 활용(Landmark Object Detection)
주요 키워드
- 인공지능(Artificial Intelligence), 데이터셋(Data Set), 랜드마크(Landmark)), 기계학습(Machine Learning), 딥러닝(Deep Learning), 객체 검출(Object Detection), 이미지 분류(Image Classification), 이미지 검색(Image Retrieval)
소개
- 인공지능 기반의 컴퓨터 비전 기술 및 서비스 개발에 활용하기 위한 국내 특성이 반영된 국내 도심 민간건물, 공공기관, 관광명소, 편의시설 등 국내 도시별 주요 랜드마크 이미지 데이터 구축
구축 내용 및 제공 데이터량
- AI 학습용 데이터 구축량
- 전국 50개 도시의 랜드마크(국내 공공기관, 주요 건물, 관광명소, 편의시설 등) 이미지를 구축하되 도시별 500개 랜드마크 각 200장 내외, 총 500만장 이상 이미지 구축
- 인공지능 학습용 데이터 활용 응용서비스‧제품 개발 방안
- 사전학습 모델(Pre-Trained Model) 연구 개발
: 구축된 500만장의 랜드마크 이미지를 활용하여 25,000개의 클래스(50개 도시, 500 랜드마크)를 분류하는 Instance-Level Recognition 모델과 이미지가 주어졌을때 유사 이미지를 판별하는 Retrieval 모델 개발 - 사전학습 모델을 활용한 응용서비스 개발 방안
- Instance-Level Image-classification 모델 개발
대표도면
< 랜드마크 이미지 수집 저작도구 >
필요성
- 국내 공공데이터의 개방수준은 세계 최고 수준이지만, AI 성능향상에 필수적인 기계학습용 데이터의 제공은 부족한 상황
- 학습용 데이터, 알고리즘, 컴퓨팅 파워는 AI 혁신의 핵심원천이나, 공공․민간의 자발적 축적‧개방을 통한 활성화 노력이 미진
- 국내 중소·벤처기업들은 AI 학습용 데이터를 자체 구축하기에 많은 시간과 비용이 소요되고 원천 데이터 확보의 어려움 호소
데이터 구조
특허 데이터 구축내용 표 (구축년도,데이터종류,포함내용,제공방식) No 항목 길이 타입 필수여부 비고 한글명 영문명 1 기본정보 info object 1-1 데이터 정보 description 200 string Y 1-2 데이터 공개 URL url 200 string 1-3 데이터버전 version 20 string 1-4 데이터 공개 연도 year 50 string 2 라이센스정보 licenses list 2-1 소유권 possession 100 string 2-2 라이센스 id값 id 50 string 3 이미지 정보 images list 3-1 라이센스 id값 license 50 string 3-2 파일네임 file name 100 number Y 3-3 이미지 사이즈 (높이) height 100
100number Y 3-4 이미지 사이즈 (넓이) width number Y 4 어노테이션 정보 Annotations list 4-1 bounding box type list Y 4-2 대상체 클래스 class 100 string Y 4-3 x좌표 x 200 number Y 4-4 y좌표 y 200 number Y 4-5 bounding box 사이즈(높이) height 200 number Y 4-6 bounding box 사이즈(넓이) width 200 number Y 5 메타정보 metainfo list 5-1 지역정보 inlocationfo 100 string Y 5-2 하위지역정보 location_sub 20 string Y 5-3 유형 Type 20 string Y 5-4 유형(하위속성) Type_sub 20 string Y 5-5 랜드마크 한글명 landmark_kr 50 string Y 56 랜드마크 주소정보 add 200 string Y -
데이터셋 구축 담당자
수행기관(주관) : 피씨앤
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 안지용 02-565-7740 [email protected] · 랜드마크이미지 AI데이터 구축 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 크라우드웍스 · 참여기관 총괄
· 크라우드소싱을 통한 데이터 수집 및 정제
· 수집 데이터 가공
· 데이터 저작도구 개발 및 제공㈜데이콘 · AI해커톤 개최 및 상용서비스 개발 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 강진규(크라우드웍스) 02-6954-2960 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.