-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-07-12 콘텐츠 최초 등록 소개
정제가 완료된 다양한 방송 콘텐츠 대본 데이터로부터 생성 요약문을 도출한 방송 콘텐츠 대본 요약 AI 데이터셋으로, 방송 데이터의 분류는 물론, 대사의 요약, 상황 묘사, 상황 추론의 데이터를 구축함으로써 방송콘텐츠의 보존과 더불어 재활용의 가치를 부여하여 방송콘텐츠의 재생산, 유통을 활성화
구축목적
요약 텍스트 데이터셋 개방 및 활용 기술/가이드 공개를 활용한 다양한 문서 텍스트 요약 알고리즘 모델 개발 및 응용 서비스 구축 기회 제공
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 KBS 방송 대본 라벨링 유형 내용요약(자연어) 라벨링 형식 json 데이터 활용 서비스 문서요약서비스, 주요문장추출서비스 등 데이터 구축년도/
데이터 구축량2021년/114,364 -
1. 데이터 구축 규모
1. 데이터 구축 규모 데이터 데이터 출처 데이터 규모 데이터 분포 데이터 형식 가족관련방송 KBS 미디어 20,000 20% - 원시 데이터 (mp4) 현대드라마 KBS 미디어 20,000 20% 원천 데이터 (xml/json) 역사극 KBS 미디어 14,000 14% 시사 KBS 미디어 17,000 17% 교양지식 KBS 미디어 13,000 13% 예능 KBS 미디어 16,000 16% 합계 100,000 100% 2. 데이터 분포
2.1 문서 유형 및 문서 종류별 분포2.1 문서 유형 및 문서 종류별 분포 데이터 종류 2~3문장 20% 요약 합계 fm_drama 10,786 11,214 22,000 fs_drama 11,500 10,502 22,002 history 8,333 7,350 15,683 c_event 9,642 9,341 18,983 culture 7,625 6,825 14,450 enter 11,278 9,968 21,246 합계 59,164 55,200 114,364 - 각 요약 별 1문장 요약은 필수로 포함되어 있어, 실제 학습 데이터 규모는 2배임2.2 요약 길이별 분포
2.2 요약 길이별 분포 요약 길이 건수 비율 2~3문장 59,164 51.73% 20% 요약 55,200 48.27% 합계 114,364 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드방송 콘텐츠 대본 요약 모델 설계/개발 개요
- 트랜스포머(Transformer) 아키텍처를 사용하는 T5(Text-to-text transfer transformer) 모델을 활용하여 멀티-태스크 러닝으로 방송 콘텐츠 대본 요약 모델을 개발하여 성능을 측정함
- 최종 성능은 한문장 요약, 3문장 요약, 20% 요약의 모든 태스크를 멀티로 수행한 결과 ROUGE-L 기준 37.549로 측정됨
요약 모델 구조
- 요약 모델에 사용한 사전학습 모델은 와이즈넛에서 개발한 KoT5 (https://github.com/wisenut-research/KoT5)를 사용하여 파인튜닝을 진행함
- KoT5는 구글에서 공개한 T5: Text-To-Text Transfer Transformer 모델의 구조를 그대로 사용하며, 한국어 데이터로 학습한 모델로 각 레이어 마다 Self Attention, Multi-head Attention, Feed Forward 구조를 가지고 있음
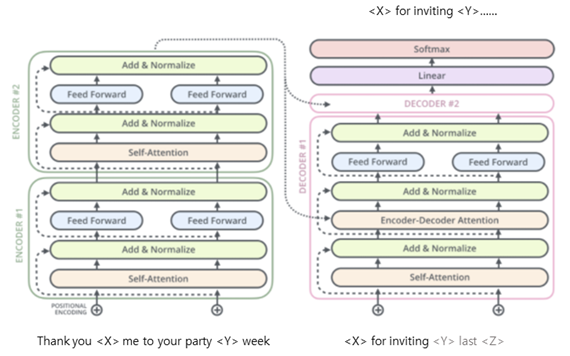 <그림> KoT5 모델 구조도
<그림> KoT5 모델 구조도- 활용한 모델은 small 모델과 base 모델로 각 모델의 구성은 다음 표와 같음
모델의 구성 파라메터 수 hidden size 레이어 수 어텐션 헤드 수 (임베딩 차원) (인코더+디코더) KoT5-small 60M 512 6 + 6 8 KoT5-base 220M 768 12 + 12 12 요약 모델 파인튜닝
- 학습데이터는 (5)에서 검수완료된 방송 콘텐츠 대본 요약 데이터 중 Training셋과 Validation 셋을 사용하여 학습을 수행하였고, Test 셋은 평가용으로만 사용함
- 각 도메인별, 출력 길이별 멀티 태스크러닝을 하기 위해서 모델의 입력을 프롬프팅(prompting)하도록 구현하였음. 프롬프팅은 입력의 앞부분에 수행할 도메인, 출력 길이, TASK를 자연어 형식으로 바꿔 주는 것으로 아래 그림과 같이 입력하였음

요약 모델 평가 결과
- 평가데이터는 (5)에서 검수완료된 방송 콘텐츠 대본 요약 데이터 중 Test셋을 사용하여 각 도메인 별, 길이 별 ROUGE 점수를 계산함
- ROUGE는 문장간 중복되는 단어의 수에 따라 ROUGE-1(유니그램), ROUGE-2(바이그램), ROUGE-L(최장 길이 매칭)으로 계산할 수 있음
- 평가시 사용한 토큰의 단위는 형태소 분석 결과로 나온 형태소단위로 오픈소스 형태소 분석기인 KOMORAN(https://github.com/shineware/KOMORAN)을 사용하였음
요약 모델 평가 결과 도메인 길이 KoT5 small KoT5 base ROUGE-1, ROUGE-2, ROUGE-L ROUGE-1, ROUGE-2, ROUGE-L 전체 전체 48.003 23.655 35.779 49.697 25.401 37.549 전체 한문장 43.460 20.315 34.288 45.224 22.013 35.929 전체 세문장 54.016 28.070 37.894 55.690 29.935 39.915 전체 20% 48.002 23.652 35.788 49.692 25.405 37.545 시사 전체 44.967 20.788 32.662 47.255 23.163 35.043 교양지식 전체 46.707 23.815 35.617 48.715 26.023 37.599 예능 전체 49.521 26.968 38.627 50.966 28.550 40.133 드라마1 전체 47.960 22.425 34.981 49.562 23.942 36.641 드라마2 전체 49.022 23.966 36.247 50.616 25.572 38.009 역사극 전체 49.743 24.474 36.956 50.934 25.769 38.216 - 전체 평균 ROUGE-L 기준으로 37.549의 결과를 보였고, 요약의 길이가 짧은 한문장 요약 보다 요약의 길이가 긴 20% 요약과 세문장 요약이 더 좋은 성능을 보임
- 도메인 별로는 직관적인 표현이 많은 예능이 가장 높고 상대적으로 사전 지식이 필요한 시사와 드라마 장르에서 낮은 결과를 보임
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 생성요약 모델 성능평가 Text Summary Transformer ROUGE-L 35 % 37.55 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷 및 원문데이터 포맷
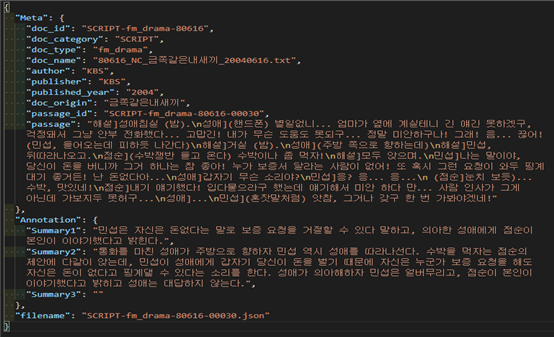
데이터 포맷 및 원문데이터 포맷 내용 문서 ID SCRIPT-fm_drama-80616 문서범주 SCRIPT 문서유형 fm_drama 문서명 80616_NC_금쪽같은내새끼_20040616.txt 발행자 KBS 발행처 KBS 발행연도 2004 출처 금쪽같은내새끼 원문 ID SCRIPT-fm_drama-80616-00030 원문 해설]성애침실 (밤).
성애](핸드폰) 별일없니... 엄마가 옆에 계실테니 긴 얘긴 못하겠구, 걱정돼서 그냥 안부 전화했다... 고맙긴! 내가 무슨 도움도 못되구... 정말 미안하구나! 그래! 음... 끊어! (민섭, 들어오는데 피하듯 나간다)
해설]거실 (밤).
성애](주방 쪽으로 향하는데)
해설]민섭, 뒤따라나오고.
점순](수박쟁반 들고 온다) 수박이나 좀 먹자!
해설]모두 앉으며.
민섭]나는 말이야, 당신이 돈을 버니까 그거 하나는 참 좋아! 누가 보증서 달라는 사람이 없어! 또 혹시 그런 요청이 와두 핑계 대기 좋거든! 난 돈없다아...
성애]갑자기 무슨 소리야?
민섭]응? 응... 응...
(점순]눈치 보듯)... 수박, 맛있네!
점순]내기 얘기했다! 입다물으라구 했는데 얘기해서 미안 하다 만... 사람 인사가 그게 아닌데 가보지두 못허구...
성애]...
민섭](혼잣말처럼) 앗참, 그거나 갖구 한 번 가봐야겠네!"어노테이션 포맷
어노테이션 포맷 단계 수준 1 수준 2 수준3 타입 필수값 다양성분석여부 설명 유효값 / 허용범위 / 예시 여부 수집 Meta doc_id 문서ID string Y 문서범주(과제구분)-문서유형-획득SEQ# (5자리숫자) SCRIPT-fm_drama-12345 획득 doc_category 문서범주 string Y - SCRIPT: 방송 콘텐츠 대본 요약 SCRIPT doc_type 문서유형 string Y O 1.가족관련방송fm_drama 1. fm_drama 2.현대드라마fs_drama 2.fs_drama 3.역사극history 3.history 4.시사c_event 4.c_event 5.교양지식culture 5.culture 6.예능enter 6.enter doc_name 문서명 string Y (확보 수집한 원천데이터 파일명) author 발행자 string Option publisher 발행처 string Option published_year 발행연도 string Option YYYY ex. 2018,2021 doc_origin 출처 string Y 정제 passage_id 원문 ID string Y 문서 ID + 분리순서(가공SEQ#) SCRIPT-fm_drama-12345-00032 SCRIPT-fm_drama-00001(5자리) -00001(5자리) passage 원문(전체글) string Y 구축 대상 원문/원본 문단 가공 Annotation Summary1 1문장 요약 string Y Summary2 2~3문장요약 string Option Summary3 20% 요약 string Option 공통 filename 파일명 string Y passage_id SCRIPT-fm_drama-00001-00032.json SCRIPT-fm_drama-12345-00032 실제 예시
-
데이터셋 구축 담당자
수행기관(주관) : ㈜와이즈넛
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김정민 이사 02-3404-7237 [email protected] 총괄 책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜딥네츄럴 전영민 이사 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김정민 이사 02-3404-7237 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.