-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-14 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-25 저작도구 개방 2022-10-13 신규 샘플데이터 개방 2022-07-14 콘텐츠 최초 등록 소개
현존 고문헌의 대부분을 차지하고 있는 조선시대 고서의 원문 한자를 AI 기반의 OCR 기술을 통해 디지털 텍스트로 자동 확보하기 위하여, 고서 원문 내의 각 낱자 한자들에 대한 바운딩박스와 라벨링(유니코드 한자) 정보로 구성된 JSON 파일과 해당 고서 원문이미지 파일의 쌍으로 구성된 한자 글자수 기준 1천만 자 규모의 고서 한자 인식(OCR) AI 학습용 데이터셋
구축목적
한자로 기록된 국가기록유산(고서, 고문헌 등)의 활용성과 접근성 향상을 위해 고서 이미지 속 한자의 디지털 텍스트를 자동으로 확보하기 위한 인공지능 기반 OCR 기술 개발용 학습 데이터
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 텍스트 , 이미지 데이터 형식 JPG 데이터 출처 조선시대에 출간된 고도서류 라벨링 유형 바운딩박스(이미지) 라벨링 형식 JSON 데이터 활용 서비스 고문헌 한자 인식(OCR), 고문헌 이미지 검색, 고문헌 자동번역 데이터 구축년도/
데이터 구축량2021년/한자 글자수 기준 10,439,251자 -
1. 서체별 통계
1. 서체별 통계 서체 글자수(※기준) 비율 이미지수(참고) 해서 6,841,923 65.50% 36,306 행서 3,024,903 29.00% 16,302 초서 529,010 5.10% 1,990 전서 26,455 0.30% 910 예서 16,960 0.20% 177 계 10,439,251 100.00% 55,685 2. 판본별 통계
2. 판본별 통계 판본 글자수(※기준) 비율 이미지수 인출본 목판본 7,239,623 3,636,715 69.35% 34.80% 40,539 21,167 석인본 3,602,908 34.50% 19,372 활자본 목활자본 2,586,036 802,859 24.77% 7.70% 12,177 4,831 연활자본 467,471 4.50% 2,174 금속활자본 1,315,706 12.60% 5,172 필사본 필사본 613,592 613,592 5.88% 5.90% 2,969 2,969 계 10,439,251 10,439,251 100.00% 100.00% 55,685 55,685 -
-
저작도구 설명서 및 저작도구 다운로드
저작도구 다운로드 -
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 세그멘테이션 모델 (HRCenterNet 기반. CNN 계열)
- 고서의 이미지 분할(Image Segmentation)을 목적으로 고서에서 발생하는 다양한 크기와 서체, 글자의 왜곡 현상을 적합하게 반영할 수 있도록 설계된 CNN 모델로 기존 에 많이 사용되던 ResNet 기반의 U-Net이나 PSPNet 보다 좋은 성능을 보임. 2020년 대만 NCCU에서 제안하여 고서 인식에 탁월한 효과를 보임
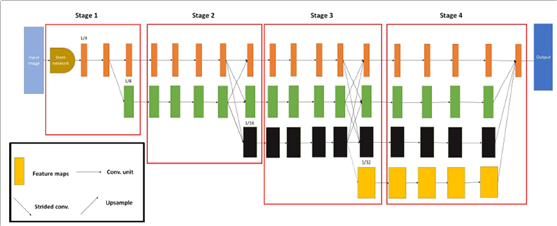
[그림] HRCenterNet 기반의 세그먼테이션 모델
2. 클러스터 모델 (ResNet 기반)
- 클러스터링 학습 모델은 Bottleneck을 적용한 ResNet을 기반으로 구성됨. 고문서 한자 낱자 데이터가 부족한 학습 데이터 구축 초기에는 한글 및 한자 오픈 데이터를 이용하여 모델을 학습한 후, 특징 추출부만 이용하여 한자 낱자 이미지의 특징 벡터를 추출하고 이를 각 글자의 특징벡터로 이용하여 특징 벡터간의 Cosine Similarity를 통해 글자간 유사도를 산출하고 유사도를 기준으로 유사 글자 클러스터를 구축함
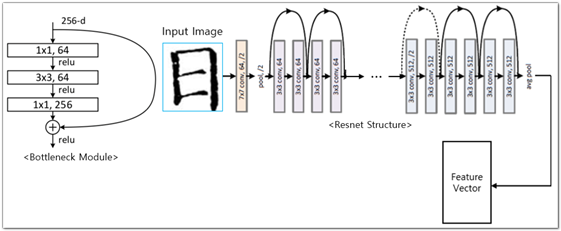
[그림] ResNet 기반의 클러스터 모델
3. 한자 객체 인식 학습모델 (ResNet 기반)
- OCR 인식 모델도 ResNet을 이용함. 클러스터를 기반으로 작업자들이 구축한 OCR용 한자 데이터를 이용해 학습하였으며 Softmax를 이용해 각 글자 이미지에 적합한 유니코드로 분류함
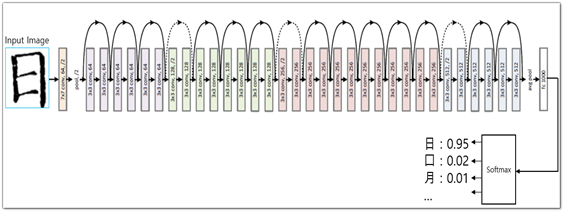
[그림] ResNet 기반의 한자 객체 인식 학습모델
- 고서의 이미지 분할(Image Segmentation)을 목적으로 고서에서 발생하는 다양한 크기와 서체, 글자의 왜곡 현상을 적합하게 반영할 수 있도록 설계된 CNN 모델로 기존 에 많이 사용되던 ResNet 기반의 U-Net이나 PSPNet 보다 좋은 성능을 보임. 2020년 대만 NCCU에서 제안하여 고서 인식에 탁월한 효과를 보임
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 객체검출 정확도 Optical Character Recognition HRCenterNet F1-Score 0.8 점 0.8472 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- 원시데이터 특성
1. 데이터 포맷 원시데이터 특성 종류 내용 자료형태 디지털 이미지 글자체 해서, 행서, 초서, 전서, 예서 원본형태 고서(고도서) 원본제작유형 인출본(목판본, 석인본), 활자본(목활자본, 연활자본, 금속활자본), 필사본 원본제작시기 조선시대 자료분류 문집류, 경전류 파일포멧 JPG 이미지해상도 기구축 이미지 100dpi 이상, 신규 이미지 획득 시 300dpi 이상 이미지색상 흑백, 컬러 규모 55,685면 중요성 다양한 서체로 인쇄 및 필사된 한자 고문헌(고서) 자료들로서 한자 인식 학습데이터 구축에 최적의 자료 법률문제 저작권, 초상권, 개인정보, 민감정보 등 없음 예시이미지 
- JSON 형식
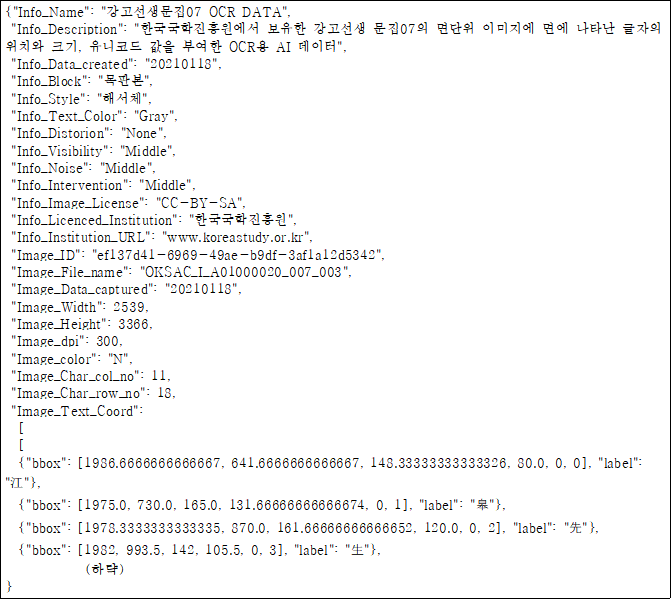
2. 데이터 구성
2. 데이터 구성 Key Description Type Child Type Info_Name 데이터셋명 String Info_Description 데이터셋설명 String Info_Data_created 데이터셋생성일자 String Info_Block 판본 정보 String Info_Style 글자체 정보 String Info_Text_Color 글자색 정보 String Info_Distortion 왜곡 정보 String Info_Visibility 선명도 정보 String Info_Noise 노이즈 정보 String Info_Intervention 글자 간섭 정보 String Info_Image_License 이미지라이선스 String Info_Licenced_Institution 라이선스소유기관 String Info_Institution_URL 라이선스소유기관URL String Image_ID 이미지식별자 String Image_File_name 이미지파일명 String Image_Data_captured 이미지생성일자 String Image_Width 이미지너비 Number Image_Height 이미지높이 Number Image_dpi 해상도 Number Image_color 컬러이미지 String Image_Char_col_no 문자 열 최고 갯수 Number Image_Char_row_no 문자 행 최고 갯수 Number Image_Text_Coord 문자위치BOX리스트(페이지/행) List JsonAray [ 페이지 JsonAray JsonObject [ 행 JsonAray JsonObject bbox 바운딩박스정보 [ JsonObject X BOX좌상단 X좌표 Number Y BOX좌상단 Y좌표 Number Width BOX 너비 Number Height BOX 높이 Number col_no 문자 열 정보 Number row_no 문자 행 정보 Number ] JsonObject label 라벨정보 Unicode 인식문자 String ] 행 JsonObject ] 페이지 JsonObject
3. 어노테이션 포맷※1~23번은 동일 레벨 데이터. 23번 하위로만 계층을 갖는 데이터.3. 어노테이션 포맷 No. 항목 길이 타입 필수여부 비고 한글명 영문명 1 데이터셋정보 Info 1 데이터셋명 Info_Name 128 String ○ 2 데이터셋설명 Info_Description 1024 String 3 데이터셋생성일자 Info_Data_created 16 String ○ 4 판본 정보 Info_Block 128 String ○ 5 글자체 정보 Info_Style 128 String ○ 6 글자색 정보 Info_Text_Color 128 String Gray, Color 7 왜곡 정보 Info_Distortion 128 String None, horizontality, Verticality, Mixed 8 선명도 정보 Info_Visibility 128 String Best, Middle, Worst 9 노이즈 정보 Info_Noise 128 String Best, Middle, Worst 10 글자 간섭 정보 Info_Intervention 128 String Best, Middle, Worst 11 이미지라이선스 Info_Image_License 128 String ○ 12 라이선스소유기관 Info_Licenced_Institution 128 String ○ 13 라이선스소유기관URL Info_Institution_URL 128 String 2 이미지정보 Image 14 이미지식별자 Image_ID 128 String ○ 15 이미지파일명 Image_File_name 128 String ○ 16 이미지생성일자 Image_Data_captured 16 String ○ 17 이미지너비 Image_Width 4 Number ○ 18 이미지높이 Image_Height 4 Number ○ 19 해상도 Image_dpi 4 Number 20 컬러이미지 Image_color 1 String 21 문자 열 최고 갯수 Image_Char_col_no 4 Number 22 문자 행 최고 갯수 Image_Char_row_no 4 Number 23 문자위치BOX리스트 Image_Text_Coord List ○ 23-1-1 BOX좌상단 X좌표 X 4 Number ○ 23-1-2 BOX좌상단 Y좌표 Y 4 Number ○ 23-1-3 BOX 너비 Width 4 Number ○ 23-1-4 BOX 높이 Height 4 Number ○ 23-1-5 문자 열 정보 col_no 4 Number 23-1-6 문자 행 정보 row_no 4 Number 23-2 인식문자 Unicode 1 String ○ 4. 실제 예시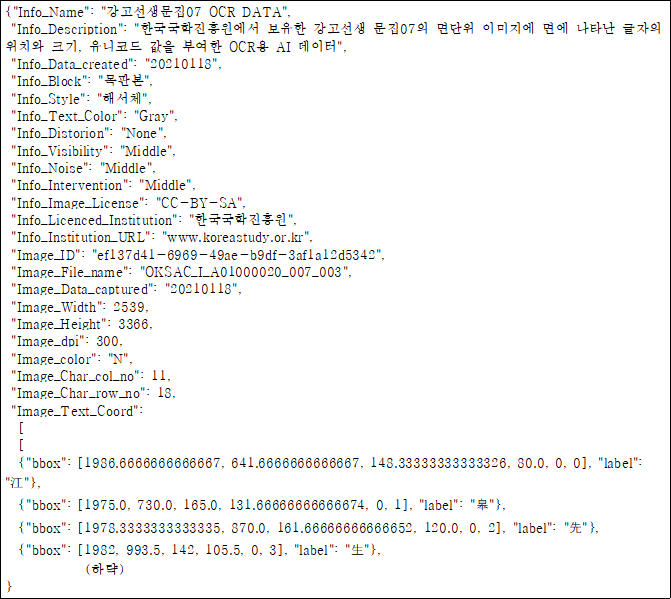
- 원시데이터 특성
-
데이터셋 구축 담당자
수행기관(주관) : 동양시스템즈
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김현 02-405-7700 [email protected] · 총괄책임 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜누리아이디티 · 구축 총괄관리
· 원시데이터 수집/분석
· 데이터 정제 및 가공
· 1차 검수/교정
· 2차 검수/교정
· 최종품질검수㈜에프아이솔루션 · 데이터 정제 및 가공
· 1차 검수/교정㈜문원씨앤디 · 데이터 정제 및 가공
· 1차 검수/교정한국국학진흥원 · 원시데이터 수집/분석/제공
· 최종품질검수데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김현 02-405-7700 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.