-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2023-10-05 라벨링데이터 수정 1.1 2022-11-16 Validation-원천데이터/라벨링데이터 재연결 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-11-13 AI모델 도커 이미지 등록 2023-10-05 저작도구 등록 2023-03-23 담당자 변경 2022-11-29 교육활용 동영상 등록 2022-10-13 신규 샘플데이터 개방 2022-07-12 콘텐츠 최초 등록 소개
병원(한림대 강남성심병원, 동탄성심병원 등), 청각 센터(한림대 청각학과 졸업생 네트워크 활용)에서 최소 1,200명(총 5,000 시간 이상 5,250시간 이하)의 원시데이터를 확보하여 다양한 나이, 지역, 성별, 질환으로부터 정제된 발화 데이터 추출 및 질환 분류 인공지능 데이터셋 구축
구축목적
구음장애 중재 시 진전 과정을 모니터링하거나 여러 중재 방법들을 비교하는데 유용하게 사용하거나 병증 진단의 목표 수준을 제시하는데 활용할 수 있도록 구음장애 환자를 대상으로 1200명(5,000시간 이상 5250시간 이하) 발화 데이터 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 데이터 형식 wav 데이터 출처 자체 수급 라벨링 유형 전사(음성) 라벨링 형식 Json 데이터 활용 서비스 의료 서비스 데이터 구축년도/
데이터 구축량2021년/5,000 시간 이상 -
1. 지역 비율
1. 지역 비율 번호 대분류 데이터수량(분) 비율 1 충청 17337 5.77% 2 경상 25179 8.38% 3 강원 1382 0.46% 4 제주 1142 0.38% 5 전라 19500 6.49% 6 경기 106035 35.29% 7 경상 240 0.08% 8 서울 129321 43.04% 9 미상 361 0.12% 2. 연령 비율
2. 연령 비율 번호 대분류 데이터수량(분) 비율 1 ~10 1082 0.36% 2 11~20 15835 5.27% 3 21~30 132235 44.01% 4 31~40 50358 16.76% 5 41~50 24999 8.32% 6 51~60 22475 7.48% 7 61~70 24278 8.08% 8 71~80 22024 7.33% 9 81~90 5619 1.87% 10 91 이상 1562 0.52% 3. 성별 비율
3. 성별 비율 번호 대분류 데이터수량(분) 비율 1 여성 173910 57.88% 2 남성 126557 42.12% 4. 스트립트 분류 비율
4. 스트립트 분류 비율 번호 대분류 데이터수량(분) 비율 1 단어 33652 11.20% 2 문장 185328 61.68% 3 문단 71721 23.87% 4 준자유 9345 3.11% 5 자유 421 0.14% 5. 장애 분류 비율
5. 장애 분류 비율 번호 대분류 데이터수량(분) 비율 1 뇌신경 62557 20.82% 2 언어청각 91192 30.35% 3 후두 146718 48.83% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 같은 음소의 경우라도 정상인과 다른 음성을 발화할 뿐 아니라 장애에 따라서도 다른 음성으로 발화하는 것을 고려하여 장애별 음성 모델을 딥러닝 알고리즘을 이용하여 각각 구현함.
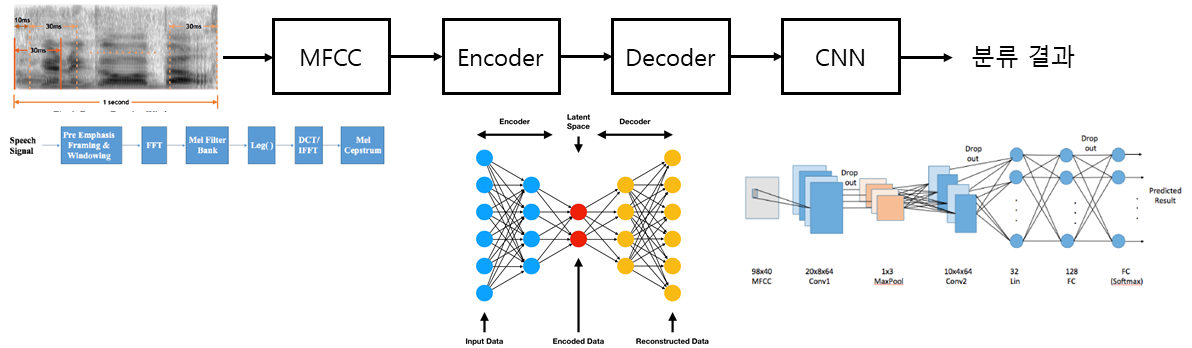
- 음성 인식 학습을 위한 인공지능 모델에는 CNN-HMM, CNN-biLSTM, 그리고 CNN-biLSTM-CTC를 이용하고 질병 분류 학습을 위한 인공지능 모델에는 AE-CNN을 이용함.
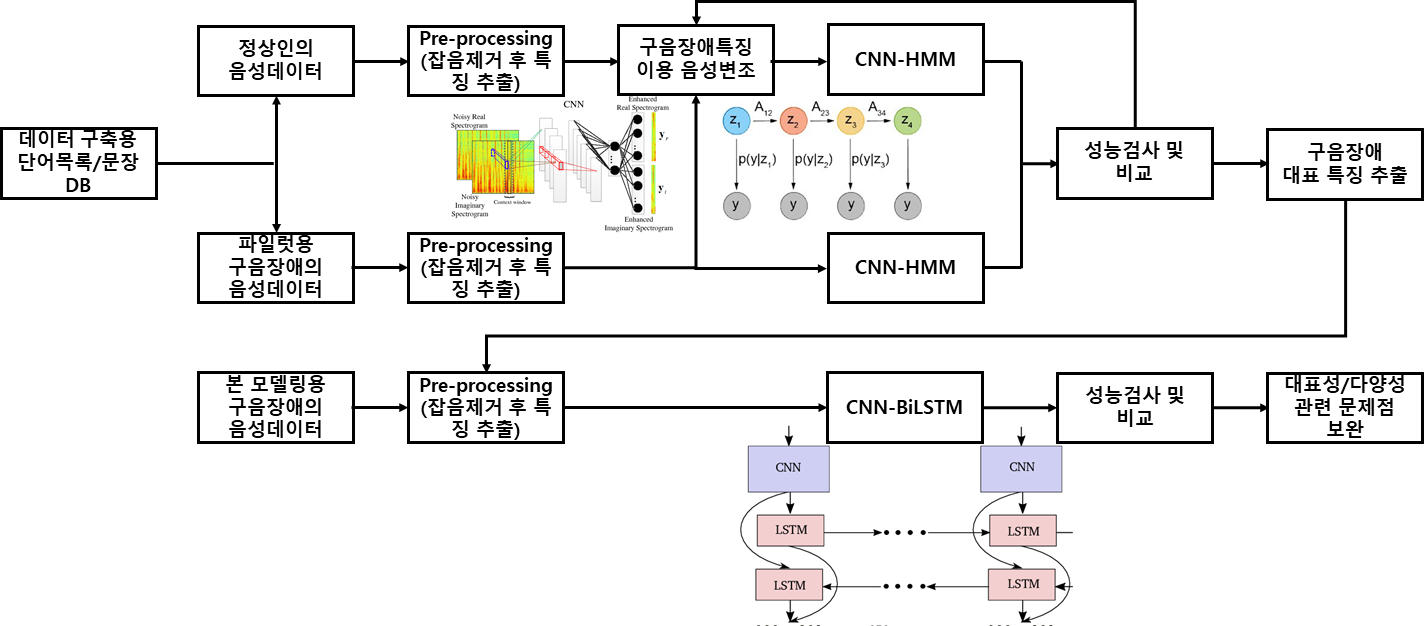
- 음향 모델은 기존의 렉시콘과 언어 모델과 함께 뇌신경/청각/후두 장애의 음성 인식 시스템 구축에 활용함.
- Pre-processing : 파이럿 스터디 과정에서 정상인과 구음장애 각 음성데이터는 샘플링 과정을 통해 디지털 데이터로 변환된 후 MFCC를 통한 특징벡터들과 함께 추가적으로 pitch, jitter (피치의 변화율), Shimmer (최대 진폭 변화율), HNR (Harmonics to Noise Ratio : 고조파 성분과 잡음 비율), PPT (Pitch Period Entrophy : 피치 주기 엔트로피), DFA (Detrended Fluctuation Analysis : 자기 상관도), RPDE (Recurrence period density entropy : 재귀 주기 밀도 엔트로피), 등을 포함하는 특징벡터 추출. 이 때, 오디오 파일을 일정 간격 (10-20ms)의 윈도우 사이즈로 프레임을 나누고 각 프레임 마다 이산푸리에변환을 취한 다음 MFCC 파라미터 값들을 추출함.
- 각 프레임 마다 문자열을 할당할 때 자모를 분리하고 초성, 중성, 중성을 분리하여 할당함.
- 정상인 음성데이터 변조 : 정상인과 구음장애의 특징벡터를 비교하여 가장 차이가 큰 순서대로 n개의 특징 파라미터 선별하여 정상인 음성데이터에 적용
- CNN-HMM : 구음장애의 특징벡터를 활용 변조된 정상인 음성데이터, 구음장애 음성데이터에 각각 CNN-HMM 알고리즘을 이용하여 학습하여 학습 모델 생성
- 성능검사 및 비교 : 정상인과 구음장애 테스트용 음성데이터를 각각 해당 CNN -HMM 학습 모델을 이용하여 성능 검사 후 비교
- 구음장애 대표 특징 추출 : 정상인 음성데이터 변조 단계부터 성능검사 및 비교 단계를 반복 시행을 통하여 구음 장애를 가장 잘 나타내는 대표 특징 추출
- CNN-BiLSTM(-CTC) 학습모델 생성 : 본 과제에서 구축할 구음장애 데이터를 학습용과 테스트용으로 나눈 다음 학습용 데이터로부터 구음장애 대표 특징을 추출하고, CNN-BiLSTM(-CTC) 알고리즘을 이용하여 학습 모델 생성
- (가) CNN-BiLSTM(-CTC) 구조 : Hybrid CTC/attention based E2E : RNN
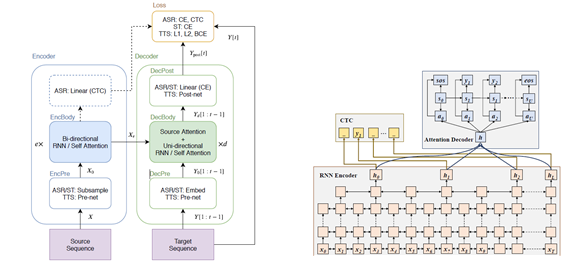
* (bench mark한 논문 : https://www.mdpi.com/2076 -3417/10/19/6936, http://oa.ee.tsinghua.edu.cn/ouzhijian/pdf/iscslp18_xiaozy.pdf, https://merl.com/publications/docs/TR2019 -158.pdf) - Encoder type : VGG-like CNN + BiRNN (LSTM/GRU)
- No. input layers : 2 VGG (sub-sampling=4)
- No. encoder layers×cells : 5×1024
- Decoder type : LSTM
- No. decoder layers×cells : 2×1024
- No. feature maps : 10
- window size : 100
- Optimizer : AdaDelta
- CTC weight : 0.5
- Epochs : 20
- Early stop : 3
- Drop out : 0.2
- (나) CNN-BiLSTM(-CTC) 구조 : Hybrid CTC/attention based E2E : Transformer
* (bench mark한 논문 : https://www.mdpi.com/2076-3417/10/19/6936, http://oa.ee.tsinghua.edu.cn/ouzhijian/pdf/iscslp18_xiaozy.pdf, https://merl.com/publications/docs/TR2019-158.pdf) - Encoder and decoder Types : transformer
- No. input layers : 2 VGG (sub -sampling=4)
- No. encoder layers×dim : 12×2048
- No. decoder layers×dim : 6×2048
- No. attention heads×dim : 4×256/8×512
- Optimizer : Noam
- CTC weight : 0.3
- Epochs : 100/120
- Early stop : 0
- Drop out : 0.1
- Gradient clipping : 5
- Warmup-steps : 25000
- (다) AE-CNN 구조 :
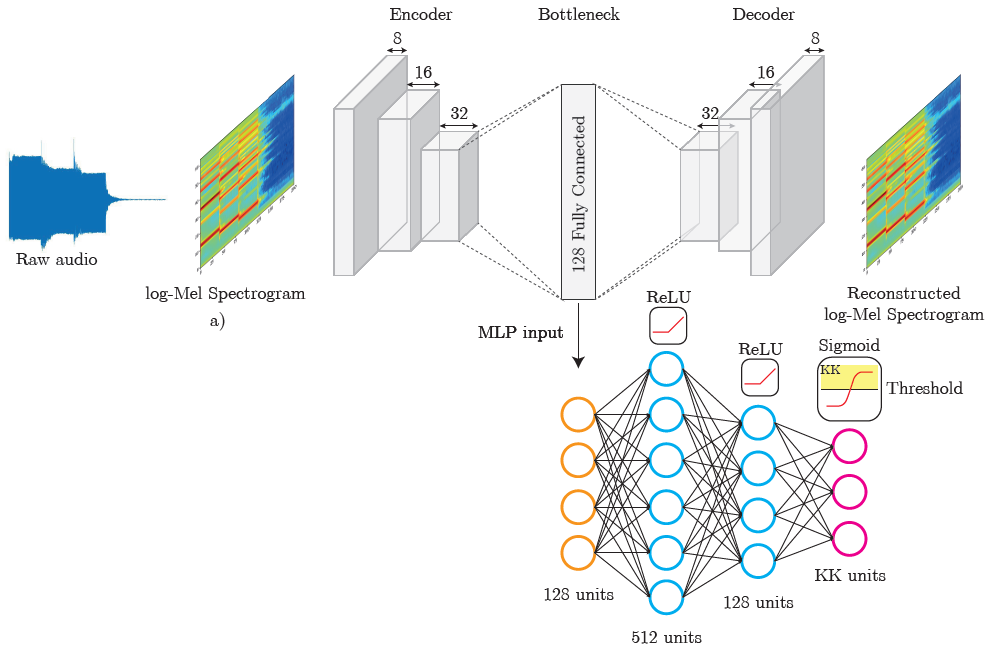
* (bench mark한 논문 : Sensors 2020, 20, 3741. https://doi.org/10.3390/s20133741) - Encoder and decoder Types : Convolutional
- No. encoder layers×dim : 3×128/4×256/8×512
- No. decoder layers×dim : 3×128/4×256/8×512
- Optimizer : Adam
- Epochs : 100
- Drop out : 0.1
- 성능 분석 : 테스트용 구음장애 데이터를 이용하여 성능 분석
- 본 데이터를 활용한 AI 분류 모델 지표의 경우 아래와 같음.
본 데이터를 활용한 AI 분류 모델 지표의 경우 아래와 같음. 질병분류모델 sensitivity specificity precision accuracy F1-score 언어청각(Disease 1) 99.32224 99.57025 99.2 99.48365 99.26108 후두 (Disease 2) 98.7961 94.28478 99.10823 98.18885 98.95192 뇌기능 (Disease 3) 99.78282 96.56438 99.65093 99.48562 99.71683 - 본 과제에서 구축하는 데이터에 대한 대표성 및 다양성 분석, 고찰 및 문제점 보완
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 장애분류 학습모델 Audio Classification KALDI/KoSpeech/ESPnet 플랫폼 상의 알고리즘 기반하여 새로이 구현 Accuracy 70 % 98.99 % 2 음성인식 Speech Recognition KALDI/KoSpeech/ESPnet 플랫폼 상의 알고리즘 기반하여 새로이 구현 CER 30 % 23.32 % 3 장애분류 학습모델 Audio Classification KALDI/KoSpeech/ESPnet 플랫폼 상의 알고리즘 기반하여 새로이 구현 F1-Score 0.7 점 0.9935 점 4 장애분류 학습모델 Audio Classification KALDI/KoSpeech/ESPnet 플랫폼 상의 알고리즘 기반하여 새로이 구현 Precision 70 % 99.56 % 5 장애분류 학습모델 Audio Classification KALDI/KoSpeech/ESPnet 플랫폼 상의 알고리즘 기반하여 새로이 구현 Recall 70 % 99.15 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드대분류 속성 표기 의미 타입 필수여부 예시 기본 정보 (Meta Info) meta.Language 언어 string Y "KOR" 기본 정보 (Meta Info) meta.Version 버전 string Y "1.0v" 기본 정보 (Meta Info) meta.RecordDate 녹음날짜 string Y “2021-05-21” 기본 정보 (Meta Info) meta.FillingDate 수정날짜 string “2021-05-22” 기본 정보 (Meta Info) meta.RecordHistory 수정기록 string Y “2021-05-22” 기본 정보 (Meta Info) meta.Distributer 수행기관 string Y “한림대학교 평촌병원” 기본 정보 (Meta Info) meta.FileName 음원파일이름 string Y “ID0001.mp3” 기본 정보 (Meta Info) meta.SampRate 음원의 SamplingRate number Y 44100(Hz) 기본 정보 (Meta Info) meta.Frequency 주파수 number Y 16bps 기본 정보 (Meta Info) meta.StartPos 말소리 시작지점 number Y 10(ms) 기본 정보 (Meta Info) meta.EndPos 말소리 종료지점 number Y 4000(ms) 기본 정보 (Meta Info) meta.PlayTime 총 재생 시간 number Y 5000(ms) 기본 정보 (Meta Info) meta.DataSize 음원 데이터 크기 number 5.2(Mbyte) 기본 정보 (Meta Info) meta.RecordingEnv 녹음 환경 string Y "Chamber" 기본 정보 (Meta Info) meta.NoiseEnv 노이즈 환경 string Y "N/A" 기본 정보 (Meta Info) meta.RecordDevice 녹음 장치 string Y "MIC" 기본 정보 (Meta Info) meta.FileCategory 파일 종류 string "Audio" 기본 정보 (Meta Info) meta.DirectoryPath 파일 위치 string “./Auditory/Train/” 기본 정보 (Meta Info) meta.FileFormat 파일 포맷 string Y "PCM" 기본 정보 (Meta Info) meta.NumberOfRepeat 반복 차수 string "3" 기본 정보 (Meta Info) meta.Distance 녹음 거리 string "50" 기본 정보 (Meta Info) meta.QualityStatus 품질 상태 string "Available" 환자 정보 (Patient Info) patient.SpeakerName 환자 이름 string "HJH" 환자 정보 (Patient Info) patient.Gender 성별 enum Y 0 : 남, 1 : 여 환자 정보 (Patient Info) patient.Age 나이 number Y 27 환자 정보 (Patient Info) patient.Geo 거주지 string Y “안양시” 질병 정보 (Disease Info) Disease.Disease 질병 타입 enum Y 0 : 뇌졸중, 1 : 퇴행성 뇌질환, 2 : 말초성 뇌신경장애, 3 : 기타/복합 질병 정보 (Disease Info) Disease.Subcategory1 뇌질환 카테고리 enum 0 : 경도 등급, 1 : 중등도 등급, 2 : 고도 등급 질병 정보 (Disease Info) Disease.GradeCategory1 뇌질환 장애 등급 카테고리 enum 0 : 언어, 1 : 청각, 2 : 기타/복합 질병 정보 (Disease Info) Disease.Subcategory2 언어·청각 카테고리 enum 0 : 경도 등급, 1 : 중등도 등급, 2 : 고도 등급 질병 정보 (Disease Info) Disease.GradeCategory2 언어·청각 장애 등급 카테고리 enum 0 : 기능성, 1 : 후두, 2 : 구강, 3 : 기타/복합 질병 정보 (Disease Info) Disease.Subcategory3 후두 카테고리 enum 0 : 경도 등급, 1 : 중등도 등급, 2 : 고도 등급 질병 정보 (Disease Info) Disease.GradeCategory3 후두 장애 등급 카테고리 enum 0 : 경도 등급, 1 : 중등도 등급, 2 : 고도 등급 검사 정보 (Test Info) Test.TestMethod 검사 방법 enum Y 0 : 단어, 1 : 문장, 2 : 문단, 3 : 준자유발화, 4 : 자유발화 검사 정보 (Test Info) Test.Transcript 발화 텍스트 string Y “크리스마스는 0월 0일입니다.” 
-
데이터셋 구축 담당자
수행기관(주관) : 한림대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 이동진 02-6960-1270 [email protected] · 뇌신경장애 데이터 수집 · 후두장애 데이터 수집 · 인공지능 학습모델 수행기관(참여)
수행기관(참여) 기관명 담당업무 파인이노베이션 · 전사 한림국제대학원대학교 · 언어 및 청각장애 데이터 수집 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이동진 02-6960-1270 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.