상표 이미지 및 텍스트
- 분야영상이미지
- 유형 텍스트 , 이미지
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021-06-25 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-12 신규 샘플데이터 개방 소개
상품을 식별하기 위해 사용되는 기호, 도형, 출원번호를 포함한 이미지 및 텍스트 데이터
구축목적
[데이터명1 – 상표 이미지 AI 데이터] - 선등록상표 사전조사를 위한 AI 기반 상표 이미지 검색 모델 학습 데이터셋 - 선등록상표 사전조사를 시행함에 있어 투입되는 인력 및 비용 절감과 기업 간 발생하는 상표권 침해 문제해결에 기여 [데이터명2 – 상표 텍스트 AI 데이터] - 상표 거절 내용 분류기 모형 개발을 위한 상표 텍스트 AI 데이터셋
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 텍스트 , 이미지 데이터 형식 데이터 출처 라벨링 유형 라벨링 형식 데이터 활용 서비스 데이터 구축년도/
데이터 구축량2020년/260.3만 -
구축 내용 및 제공 데이터량
- [데이터명1 – 상표 이미지 AI 데이터]
이미지 데이터 1,176,039건(도형 상표 161,777건, 도형 복합 상표 1,014,262건)을 가공하여, 비엔나 코드 별 라벨링 및 이미지 크롭 데이터 구축
- [데이터명2 – 상표 텍스트 AI 데이터]
의견제출통지서 약 420만 건에 대해, ‘발음유사’, ‘관념’, ‘식별력’ 사유로 거절된 60만 건 이상의 상표 텍스트 AI 데이터 구축
구축 내용 및 제공 데이터량 표 과제명 원천데이터 구축량 AI 학습 데이터 결과 목표 구축 상표 이미지 AI 데이터 1,176,039건 2,600,000건 2,603,273건 목표 달성
(100.1%)상표 텍스트 AI 데이터 4,000,000건 600,000건 839,621건 목표달성
(139.9%)
- [데이터명1 – 상표 이미지 AI 데이터]
-
-
AI 모델 상세 설명서 다운로드
AI 모델 다운로드 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 거절결정 분류 정확도 Image Classification BERT Accuracy 90 % 90.66 % 2 상표 이미지 객체 인식 Object Detection CNN mAP 60 % 70 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021.06.25 데이터 최초 개방 구축 목적
- [데이터명1 – 상표 이미지 AI 데이터]
- 선등록상표 사전조사를 위한 AI 기반 상표 이미지 검색 모델 학습 데이터셋
- 선등록상표 사전조사를 시행함에 있어 투입되는 인력 및 비용 절감과 기업 간 발생하는 상표권 침해 문제해결에 기여
- [데이터명2 – 상표 텍스트 AI 데이터]
- 상표 거절 내용 분류기 모형 개발을 위한 상표 텍스트 AI 데이터셋
활용 분야
- [기업] 상표 이미지 검색을 통한 선행상표 조사 및 상표권 피침해 사례 탐지
- [정부기관] 선행상표 검색 및 상표 분류 효율화 및 상표심사 품질 제고
- [연구기관] AI 모형 개발 시 데이터 정제 시간 및 비용 절감, 객체인식 AI모형 연구 가속화 및 고도화
소개
- [데이터명1 – 상표 이미지 AI 데이터]
● KIPRIS PLUS OPEN API로부터 상표 이미지 데이터(원시데이터) 획득
● 원본 상표 이미지의 비엔나 코드에 해당하는 feature image 크롭 데이터 확보

- [데이터명2– 상표 텍스트 AI 데이터]
● KIPRIS PLUS OPEN API로부터 의견제출통지서 데이터(원시데이터) 획득
● 텍스트 전처리 작업 수행 후, ‘거절결정내용’에 따라 ‘발음 유사’, ‘관념’, ‘식별력’으로 라벨링
구축 내용 및 제공 데이터량
- [데이터명1 – 상표 이미지 AI 데이터]
이미지 데이터 1,176,039건(도형 상표 161,777건, 도형 복합 상표 1,014,262건)을 가공하여, 비엔나 코드 별 라벨링 및 이미지 크롭 데이터 구축
- [데이터명2 – 상표 텍스트 AI 데이터]
의견제출통지서 약 420만 건에 대해, ‘발음유사’, ‘관념’, ‘식별력’ 사유로 거절된 60만 건 이상의 상표 텍스트 AI 데이터 구축
구축 내용 및 제공 데이터량 표 과제명 원천데이터 구축량 AI 학습 데이터 결과 목표 구축 상표 이미지 AI 데이터 1,176,039건 2,600,000건 2,603,273건 목표 달성
(100.1%)상표 텍스트 AI 데이터 4,000,000건 600,000건 839,621건 목표달성
(139.9%)
대표도면

필요성
- 국내외 기업들은 지식재산권 획득 및 보호에 많은 시간과 비용을 투자하고 있으며, 지식재산권에 대한 전략적 접근의 부재는 기업의 경쟁력을 넘어 국가 경쟁력의 약화로 이어질 수 있음.
- 상표권 침해 사례 조사 결과, 중국에서 우리 기업의 상표를 무단 선점하는 사례가 급증하고 있어 이에 대한 대책이 시급함.
- 한류 영향 등에 따른 국내기업 브랜드 인지도 상승으로 인해 상표 침해가 빈발하고 있으며, 중국 내 우리 기업의 상표권 침해 건수는 총 3,319건, 피해액은 총 338억 원으로 집계됨.
- 현재 국내에서 상용되는 상표 검색 서비스 중 이미지 검색 서비스 기능이 존재하는 검색 서비스는 존재하지 않으며, 이에 따라 기업 및 개인이 선등록상표에 대한 사전조사에 있어 한계점이 존재함.
- 본 사업을 통해 구축한 데이터를 통해, 국내 기업이 상표 출원 전 선등록상표에 대한 사전조사를 수행함에 있어 투입되는 인력 및 비용 절감과 기업 간 발생하는 상표권 침해 문제를 해결하고자 함.
데이터 구조
- [데이터명1 – 상표 이미지 AI 데이터]
1. 데이터 구조
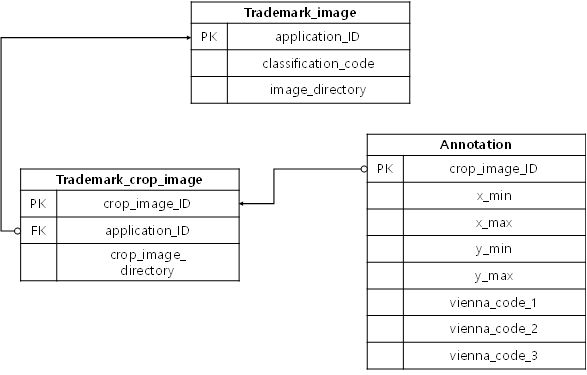
- 2. 데이터 형태 및 규칙
- Trademark_Image데이터 형태 및 규칙-Trademark_Image 구분 형태 규칙 설명 예시 application_ID Integer length: 13 상표의 출원번호 4020190197958 classification_code Integer length: 2 상품분류 35류 image_directory String length: 100 상표 이미지 저장 경로 C:/data/.../img/
4020190197958.jpg
- Trademark_crop_Image
데이터 형태 및 규칙-Trademark_crop_Image 구분 형태 규칙 설명 예시 crop_image_ID Integer length: 15 원천데이터에서 crop된 이미지의 ID 402019019795801 application_ID Integer length: 13 원천 데이터의 출원번호 4020190197958 crop_image_directory String length: 100 crop된 이미지의 저장 경로 C:/data/.../crop_img/
402019019795801.png3. 어노테이션 포맷
어노테이션 포맷 표 구분 형태 규칙 설명 예시 crop_image_ID Int length: 20 원천 데이터에서 crop된 이미지의 ID 402019019795801 x_min float length: 10 원천데이터에서 crop된
영역 중 x축의 최솟값0.12493 x_max float length: 10 원천데이터에서 crop된
영역 중 x축의 최대값0.712923 y_min float length: 10 원천데이터에서 crop된
영역 중 y축의 최솟값0.2483719 y_max float length: 10 원천데이터에서 crop된
영역 중 y축의 최대값0.8293 vienna_code String length: 50 도형 코드 040503/260103/260205 - [데이터명2– 상표 텍스트 AI 데이터]
1. 데이터 구조
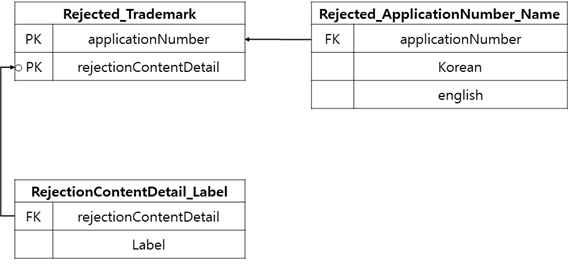
2. 데이터 형태 및 규칙
- Rejected_Trademark
데이터 형태 및 규칙-Rejected_Trademark 구분 형태 규칙 applicationNumber Integer length: 9999 rejectionContentDetail String length: 9999 - Rejected_ApplicationNumber_Name
데이터 형태 및 규칙-Rejected_ApplicationiNumber_Name 구분 형태 규칙 applicationNumber Integer length: 9999 korean String length: 9999 english String length: 9999 - RejectedContentDetail_Label
데이터 형태 및 규칙-RejectedContentDetail_Label 구분 형태 규칙 rejectionContentDetail Integer length: 9999 Label String length: 9999 3. 라벨링 작업결과물 예시
라벨링 작업결과물 예시 applicationNumber rejectionContentDetail label 4020180001431 이 출원상표는 아래와 같이 타인의 선등록 상표와 표장 및 지정상품이 동일 유사한 상표이므로
상표법 제34조 제1항 제7조에 해당하여 등록을 받을 수 없습니다.
다만, 선등록 상표의 지정상품과 동일 유사한 아래 지정상품을 삭제하는 보정을 하거나
상표법 제45조의 규정에 따라 분할하여 출원하는 경우에는 그러하지 아니합니다.발음유사 4020180003355 이 출원상표는 아래에 제시된 인용상표와 관념이 동일하여 표장 전체적으로 유사하고,
지정상품도 유사하므로 상표법 제34조 제1항 제7조에 따라 등록을 받을 수 없습니다.
다만, 아래에 제시된 관련 지정상품을 삭제하는 보정을 하거나
상표법 제45조의 규정에 따라 분할하여 출원하는 경우에는 그러하지 아니합니다.관념 4020100008753 본원상표 "TheGreat"의 "The"는 정관사로 식별력이 없으며, "Great"는 "큰, 위대한, 탁월한"이라는
의미로 품질의 우수성을 나타내는 식별력 없는 단어로 전체적으로도 식별력 없는
2개의 단어의 단순 결합한 것에 불과함으로 이를 지정상품에 사용하는 경우,
수요자가 누구의 업무와 관련된 상품을 표시하는 상표인지를 식별할 수 없으므로
상표법 제6조 제1항 제7호에 해당하여 상표등록을 받을 수 없습니다.식별력 - [데이터명1 – 상표 이미지 AI 데이터]
-
데이터셋 구축 담당자
수행기관(주관) : 인사이터
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 남성전 1833-5676 [email protected] · 데이터 구축 총괄 · 데이터 가공인력 교육 및 관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 (주)마크클라우드 · 가공 데이터 검수
· 상표 이미지 및 텍스트 검색 시범 서비스 개발(주)아이웹 · 시범 서비스 웹페이지 개발
· 어노테이션 툴 검수광운대 산학협력단 · 원시 데이터 수집 및 정제
· AI 학습용 데이터 설계, 응용서비스 설계한국지식재산연구원 · AI 학습용 데이터 활용 모델 응용서비스 설계
· 서비스 고도화 방안 설계데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 홍성균(인사이터) 1833-5676 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.