-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-24 데이터 최종 개방 1.0 2023-06-28 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-11-24 산출물 전체 공개 소개
일반 국민 생활과 밀접한 관련성이 높은 지방자치단체 (창원특례시, 김해시)와 외교 용어가 다수 포함되어있는 외교사료관 공공문서를 수집, 가공하여, 문서에 포함되어있는 다양한 문자 유형(인쇄체, 타자체, 수기 등)의 OCR 문자 인식 기술개발을 위한 인공지능 학습용 데이터셋
구축목적
생성 시점이 오래되어 상태가 좋지 않은 저화질 문서의 문자 및 다양한 형태의 문자체(인쇄체, 타자체, 수기 등)에 대한 OCR 문자인식 기술개발
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 이미지 데이터 형식 JPG 데이터 출처 자체 수집 라벨링 유형 세그멘테이션(이미지) 라벨링 형식 JSON 데이터 활용 서비스 실생활에서 많이 접하나 이해하기 어려운 공공행정용어나 법률용어 등이 포함된 문서 혹은 이미지 내에 존재하는 문자를 인식하고 선택된 문자의 검색 편의성 제공 데이터 구축년도/
데이터 구축량2022년/이미지 기준 615,053장 -
1. 데이터 구축 규모
■공공(원천데이터 이미지 615,053면)원천데이터 이미지 데이터 종류 데이터 형태 원문 규모 데이터 수집방법 데이터형식 공공 이미지 615,053면 원본문서(스캐닝)
디지털파일이미지 : JPG 2. 데이터 분포
■주제 카테고리별 데이터 분포2. 데이터 분포 카테고리 카테고리 코드 데이터셋 구성비 건설 CST 150,963 25% 경제 EN 150,552 25% 농림수산 AF 66,013 10% 문화 CT 63,916 10% 복지 WF 60,714 10% 환경 EV 120,346 20% 외교 DI 2,549 - 계 615,053 100% 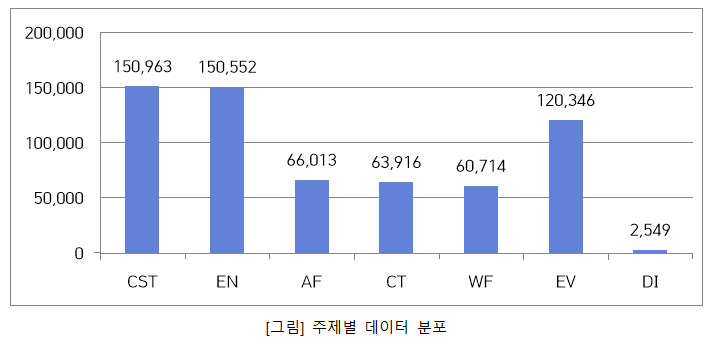
■생산연대 카테고리별 데이터 분포
생산연대 카테고리별 카테고리 카테고리 코드 데이터셋 구성비 1980년대 이전 b1980 63,579 10% 1980년대 1980 119,948 20% 1990년대 1990 240,862 39% 2000년대 2000 126,877 21% 2010년대 이후 2010 63,787 10% 계 615,053 100% 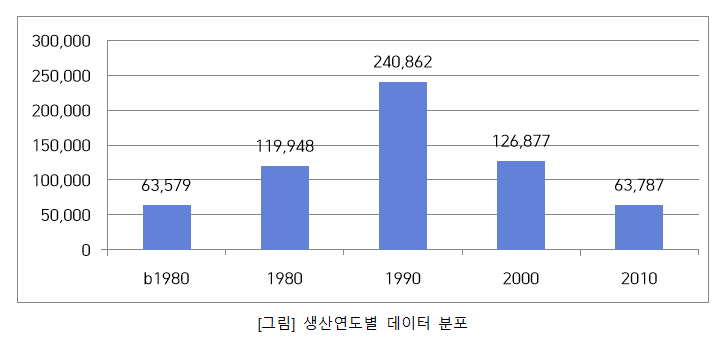
■수집기관별 데이터 분포
수집기관별 데이터 분포 과제명 창원특례시 김해시 외교사료관 계 대규모OCR데이터
(공공)497,383 115,121 2,549 615,053 81% 19% - 100% 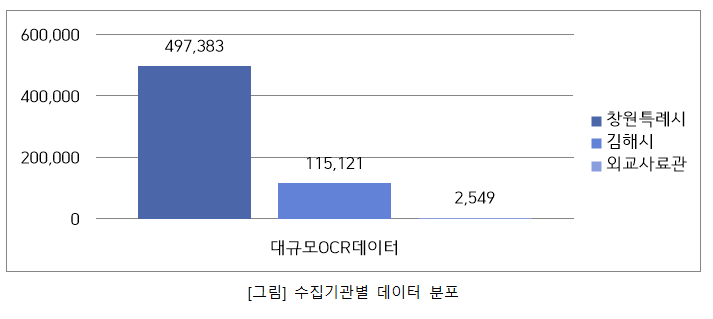
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드■모델학습
모델학습 과제명 구분 Training Validation Test Total 대규모OCR데이터
(공공)할당비율 80% 10% 10% 100% 원천데이터 489,681 64,228 61,144 615,053 라벨링데이터 489,681 64,228 61,144 615,053 [설명]
∎OCR 인공지능(공공)모델 학습용 데이터는 생산연도, 글씨체, 주제, 수집기관별로 구축되어야 하며, 원천데이터 이미지 기준으로 615,053면의 규모가 됨
-구축된 데이터는 훈련용(Training), 검증용(Validation), 시험용(Test)을 80%:10%:10% 비율로 분리하여 학습에 사용하며, 시험용 데이터는 학습이 완료될 때까지 개봉되어서는 안 됨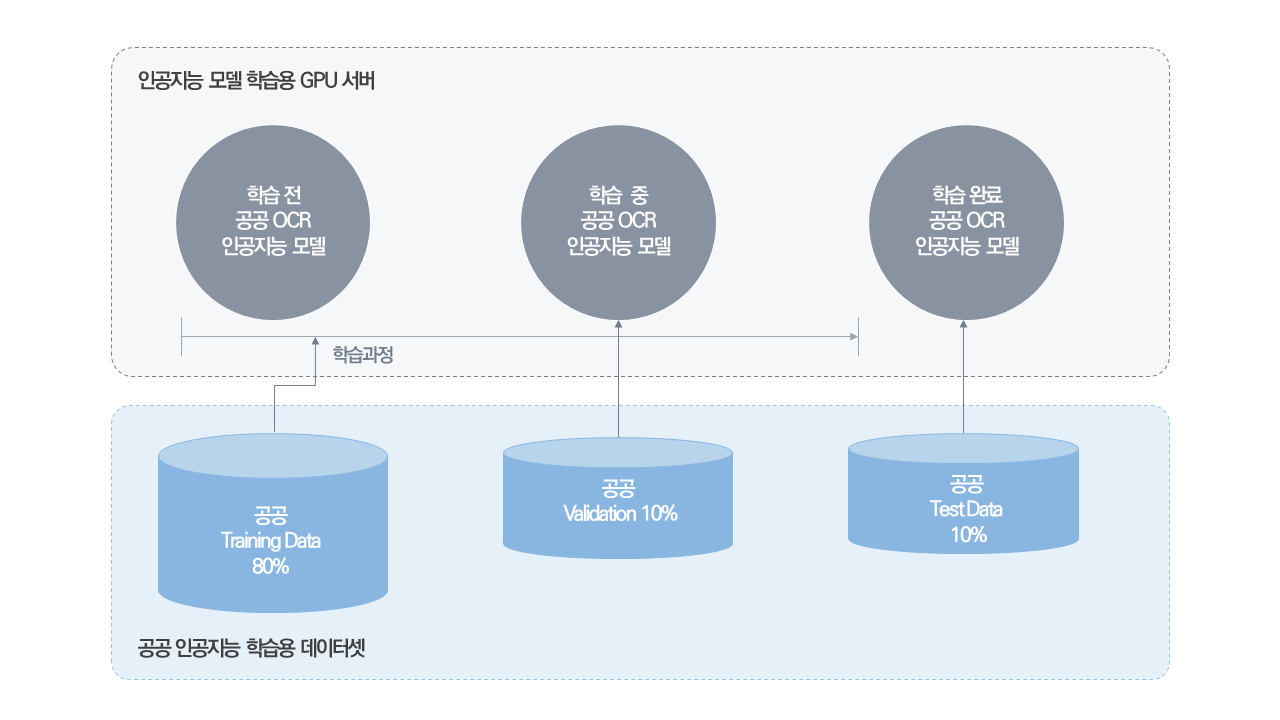
[그림] 공공 인공지능 모델 학습
■서비스 활용 시나리오
∎국민 실생활에 밀접한 공공행정문서 내의 행정용어나 법률용어 문자 인식 검색 서비스 개발
:검색의 편의성 제공
∎다양한 민원형식의 공공행정문서를 주요 키워드로 자동 추출하는 서비스
:공공문서 중요 키워드 자동 추출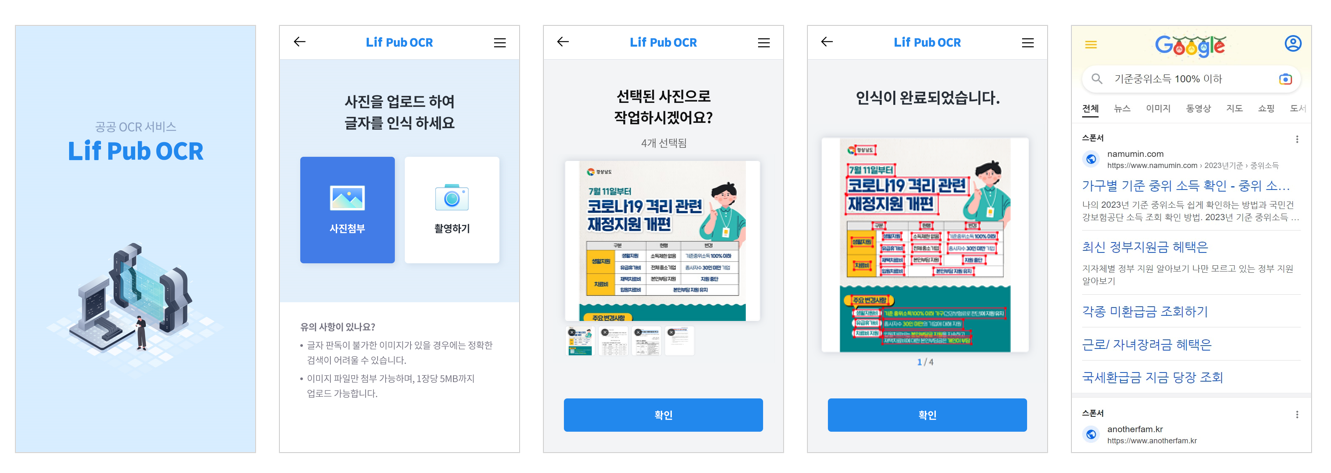 [그림] 활용 서비스 예시
[그림] 활용 서비스 예시 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 문자 인식 성능 Optical Character Recognition CRAFT F1-Score@IoU 0.5 0.8 점 0.8512 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드■데이터 포맷
○원시데이터 특성원시데이터 종류 내용 자료형태 이미지 글자체 인쇄체, 타자체, 수기 등 원본형태 종이, 디지털파일 원본제작유형 종이(원본문서), 디지털파일 원본제작시기 1980년대이전 ~ 2010년대 이후 자료분류 공공문서 파일포맷 JPG 이미지해상도 300dpi(원본문서 스캐닝 이미지) / 72dpi(전자파일 이미지) 이미지색상 컬러 규모 이미지 615,053장 중요성 시대적 흐름에 따라 생산된 다양한 문자형태(인쇄체, 타자체, 수기 등) 및 행정용어에 특화된 문자 인식 AI 모델 개발을 위한 학습용 데이터 법률문제 개인정보, 민감정보 등은 비식별화 처리 후 데이터화 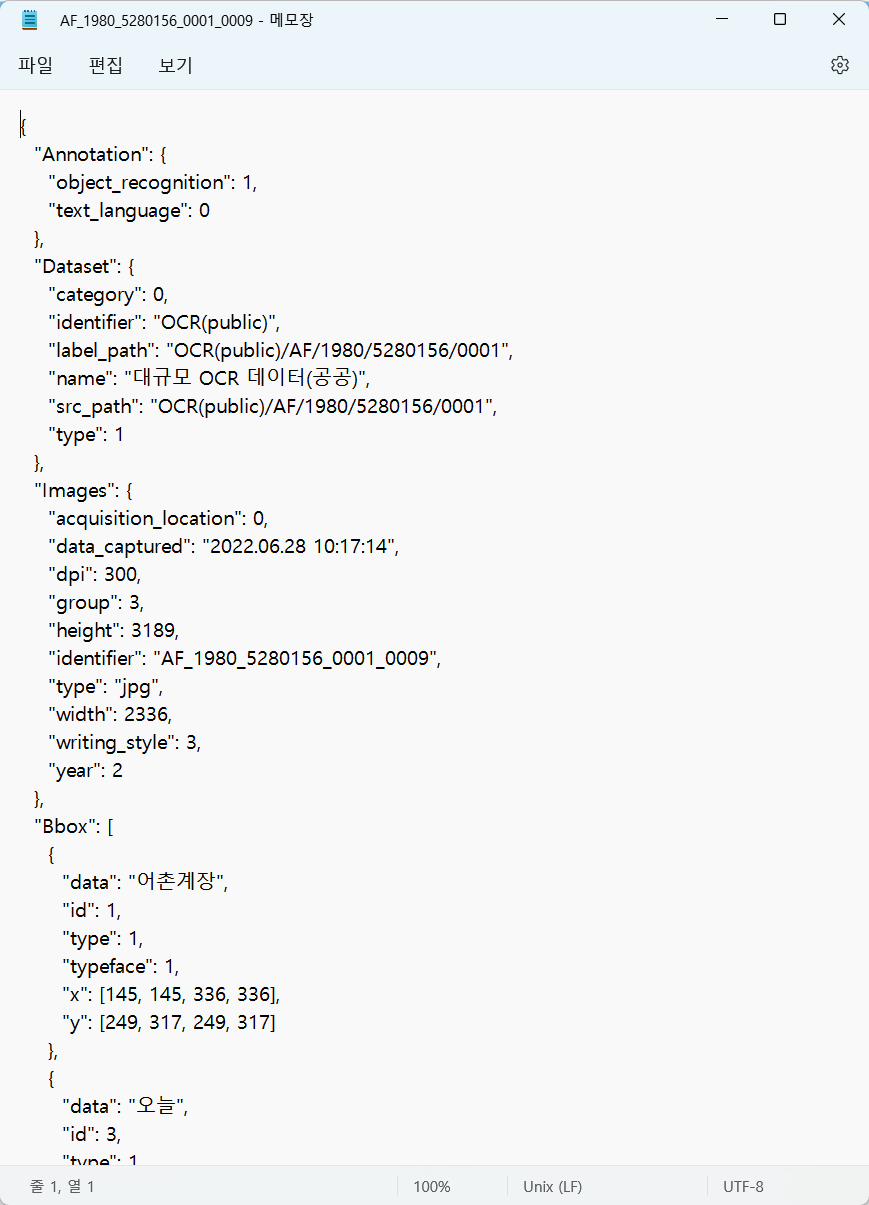
[그림] 공공행정문서 예시 이미지
○JSON 형식
{ "Annotation": {
"object_recognition": 1,
"text_language": 0
},
"Dataset": {
"category": 0,
"identifier": "OCR(public)",
"label_path": "OCR(public)/AF/1980/5280156/0001",
"name": "대규모 OCR 데이터(공공)",
"src_path": "OCR(public)/AF/1980/5280156/0001",
"type": 1
},
"Images": {
"acquisition_location": 0,
"data_captured": "2022.06.28 10:17:14",
"dpi": 300,
"group": 3,
"height": 3189,
"identifier": "AF_1980_5280156_0001_0009",
"type": "jpg",
"width": 2336,
"writing_style": 3,
"year": 2
},
"Bbox": [
{
"data": "어촌계장",
"id": 1,
"type": 1,
"typeface": 1,
"x": [145, 145, 336, 336],
"y": [249, 317, 249, 317]
},
{
"data": "오늘",
"id": 3,
"type": 1,
"typeface": 1,
"x": [571, 571, 669, 669],
"y": [255, 316, 255, 316]
},
{
"data": "총회가",
"id": 4,
"type": 1,
"typeface": 1,
"x": [706, 706, 850, 850],
"y": [252, 320, 252, 320]
},
{
"data": "분할에",
"id": 5,
"type": 1,
"typeface": 1,
"x": [884, 884, 1032, 1032],
"y": [250, 317, 250, 317]
},
이하생략■데이터 구성
데이터 구성 Key Description type Child Type Dataset.identifier 데이터셋 식별자 string Dataset.name 데이터셋 이름 string Dataset.src_path 데이터셋 폴더 위치 string Dataset.label_path 데이터셋 레이블 폴더 위치 string Dataset.category 데이터셋 카테고리 number Dataset.type 데이터셋 타입 number Images.identifier 이미지 식별자(파일명) string Images.group 그룹 number Images.year 생산연도 number Images.type 이미지 파일 확장자 string Images.width 이미지 가로 크기(픽셀) number Images.height 이미지 세로 크기(픽셀) number Images.dpi 이미지 해상도 number Images.acquisition_location 수집장소 number Images.data_captured 이미지 생성 일자 string Annotation.object_recognition 개체 인식 number Annotation.text_language 라벨링 텍스트 언어 number Bbox[].data 바운딩박스 내 텍스트 string Bbox[].id 바운딩박스 식별자 string Bbox[].type 라벨링 텍스트 타입 number Bbox[].typeface 라벨링 텍스트 유형 number Bbox[].x[] 바운딩박스 x 좌표 리스트 number Bbox[].y[] 바운딩박스 y 좌표 리스트 number images.writing_style 이미지 문자 형태 number ■어노테이션 포맷
어노테이션 포맷 속성명 항목 Type 필수여부 비고 Dataset 데이터셋(공통메타) Dataset.identifier 데이터셋 식별자 string 필수 Dataset.name 데이터셋 이름 string 필수 Dataset.src_path 데이터셋 폴더 위치 string 필수 Dataset.label_path 데이터셋 레이블 폴더 위치 string 필수 Dataset.category 데이터셋 카테고리 number 필수 Dataset.type 데이터셋 타입 number 필수 Image 이미지 Images.identifier 이미지 식별자(파일명) string 필수 Images.group 그룹 number 필수 Images.year 생산연도 number 필수 Images.type 이미지 파일 확장자 string 필수 Images.width 이미지 가로 크기(픽셀) number 필수 Images.height 이미지 세로 크기(픽셀) number 필수 Images.dpi 이미지 해상도 number 필수 images.writing_style 이미지 문자 형태 number 선택 Images.acquisition_location 수집장소 number 필수 Images.data_captured 이미지 생성 일자 string 필수 Annotation 어노테이션 방식 Annotation.object_recognition 개체 인식 number 필수 Annotation.text_language 라벨링 텍스트 언어 number 필수 Bbox 바운딩박스 어노테이션 구조 Bbox[].data 바운딩박스 내 텍스트 string 필수 Bbox[].id 바운딩박스 식별자 string 필수 Bbox[].type 라벨링 텍스트 타입 number 필수 Bbox[].typeface 라벨링 텍스트 유형 number 필수 Bbox[].x[] 바운딩박스 x 좌표 리스트 number 필수 Bbox[].y[] 바운딩박스 y 좌표 리스트 number 필수 ■실제 예시
{ "Annotation": {
"object_recognition": 1,
"text_language": 0
},
"Dataset": {
"category": 0,
"identifier": "OCR(public)",
"label_path": "OCR(public)/AF/1980/5280156/0001",
"name": "대규모 OCR 데이터(공공)",
"src_path": "OCR(public)/AF/1980/5280156/0001",
"type": 1
},
"Images": {
"acquisition_location": 0,
"data_captured": "2022.06.28 10:17:14",
"dpi": 300,
"group": 3,
"height": 3189,
"identifier": "AF_1980_5280156_0001_0009",
"type": "jpg",
"width": 2336,
"writing_style": 3,
"year": 2
},
"Bbox": [
{
"data": "어촌계장",
"id": 1,
"type": 1,
"typeface": 1,
"x": [145, 145, 336, 336],
"y": [249, 317, 249, 317]
},
{
"data": "오늘",
"id": 3,
"type": 1,
"typeface": 1,
"x": [571, 571, 669, 669],
"y": [255, 316, 255, 316]
},
{
"data": "총회가","id": 4,
"type": 1,
"typeface": 1,
"x": [706, 706, 850, 850],
"y": [252, 320, 252, 320]
},
{
"data": "분할에",
"id": 5,
"type": 1,
"typeface": 1,
"x": [884, 884, 1032, 1032],
"y": [250, 317, 250, 317]
},
이하생략 -
데이터셋 구축 담당자
수행기관(주관) : ㈜엔에이치엔다이퀘스트
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김경선 02-3470-4306 [email protected] 과제 총괄관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜쇼우테크 데이터셋 구축 총괄관리, 데이터 수집 및 정제, 데이터 1차 검수/교정, 데이터 2차 검수/ 교정, 데이터 최종 품질 검수, 활용서비스 개발 ㈜코이션 데이터 가공 앙코르브라보노(협) 데이터 3차 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김경선 02-3470-4306 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.