-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-06 데이터 최종 개방 1.0 2023-04-30 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-04-23 데이터설명서, 담당자 이메일 변경 2023-12-06 산출물 전체 공개 소개
자연어처리(NLP) 및 딥러닝 기술을 기반으로, 낚시성 기사로 인해 발생하는 시간과 비용 낭비, 사실 왜곡 등의 사회적 문제를 해결하기 위한 인공지능 학습용 데이터(‘제목과 본문의 불일치 기사’와 ‘본문의 도메인 일관성 부족 기사’로 데이터셋 구성)
구축목적
낚시성 기사는 저널리즘의 품질을 현저하게 떨어뜨리고, 시간과 비용 낭비, 사실 왜곡 등의 사회적 문제 발생시키고 있으며, 이를 해결하기 위해 학습용 데이터셋과 자연어 처리(NLP) 및 딥러닝 기술을 기반으로 학습모델을 개발하여 공개함으로써 관련 분야에서 뉴스 신뢰도 향상 및 활용 가능한 다양한 서비스 및 도구 양산에 활용
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 신문기사 라벨링 유형 낚시성 기사 제목 및 본문 문장 작성 라벨링 형식 JSON 데이터 활용 서비스 낚시성 기사 정보 제공 서비스, 낚시성 기사 필터링 서비스 데이터 구축년도/
데이터 구축량2022년/733,427 -
데이터 통계
데이터 구축 규모
데이터 구축 규모 종류 형태 구분 포맷 세부 구축 규모(건) 신문기사 텍스트 원천데이터 JSON 1세부 364,333 2세부 369,094 합계 733,427 라벨링데이터 JSON 1세부 364,333 2세부 369,094 합계 733,427 데이터 분포
▶ 데이터셋 구성
데이터셋 구성 구분 가공유형 기사 카테고리 건수 비율 Part1(1세부)
제목과 본문의 불일치 기사Clickbait_Auto
(낚시성기사_자동생성)EC(경제) 17,991 5% ET(연예) 16,376 4% GB(세계) 20,355 6% IS(IT&과학) 18,511 5% LC(생활&문화) 13,518 4% PO(정치) 18,308 5% SO(사회) 27,459 8% Clickbait_Direct
(낚시성기사_직접생성)EC(경제) 8,759 2% ET(연예) 6,773 2% GB(세계) 8,926 2% IS(IT&과학) 6,878 2% LC(생활&문화) 4,345 1% PO(정치) 5,713 2% SO(사회) 8,737 2% NonClickbait_Auto
(非낚시성기사_자동생성)EC(경제) 25,830 7% ET(연예) 21,877 6% GB(세계) 26,940 7% IS(IT&과학) 24,978 7% LC(생활&문화) 21,688 6% PO(정치) 25,202 7% SO(사회) 35,169 10% 소계 364,333 100% Part2(2세부)
본문의 도메인 일관성 부족 기사Clickbait_Auto
(낚시성기사_자동생성)EC(경제) 19,089 5% ET(연예) 17,622 5% GB(세계) 22,074 6% IS(IT&과학) 19,094 5% LC(생활&문화) 13,283 4% PO(정치) 18,503 5% SO(사회) 27,606 7% Clickbait_Direct
(낚시성기사_직접생성)EC(경제) 6,429 2% ET(연예) 5,827 2% GB(세계) 8,371 2% IS(IT&과학) 6,886 2% LC(생활&문화) 4,695 1% PO(정치) 6,976 2% SO(사회) 10,955 3% NonClickbait_Auto
(非낚시성기사_자동생성)EC(경제) 25,835 7% ET(연예) 21,936 6% GB(세계) 26,727 7% IS(IT&과학) 24,874 7% LC(생활&문화) 21,886 6% PO(정치) 25,072 7% SO(사회) 35,354 10% 소 계 369,094 100% 합 계 733,427 100% ▶가공방법별 분포
가공방법별 분포 세부 용도 가공방법 건수 비율 1세부 낚시성 자동생성 132,518 36% 직접생성 50,131 14% 非낚시성 자동생성 181,684 50% 합 계 364,333 100% 2세부 낚시성 자동생성 137,271 37% 직접생성 50,139 14% 非낚시성 자동생성 181,684 49% 합 계 369,094 100% 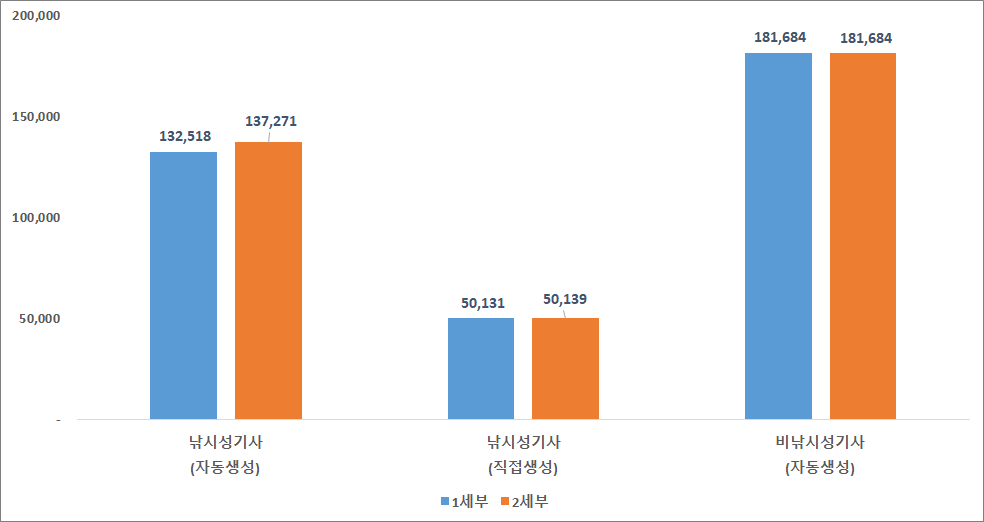
▶기사 카테고리별 분포
기사 카테고리별 분포 기사 카테고리 1세부 2세부 합계 비율 건수 비율 건수 비율 EC(경제) 52,580 14.40% 51,353 13.90% 103,933 14.20% ET(연예) 45,026 12.40% 45,385 12.30% 90,411 12.30% GB(세계) 56,221 15.40% 57,172 15.50% 113,393 15.50% IS(IT&과학) 50,367 13.80% 50,854 13.80% 101,221 13.80% LC(생활&문화) 39,551 10.90% 39,864 10.80% 79,415 10.80% PO(정치) 49,223 13.50% 50,551 13.70% 99,774 13.60% SO(사회) 71,365 19.60% 73,915 20.00% 145,280 19.80% 합 계 364,333 100% 369,094 100% 733,427 100% 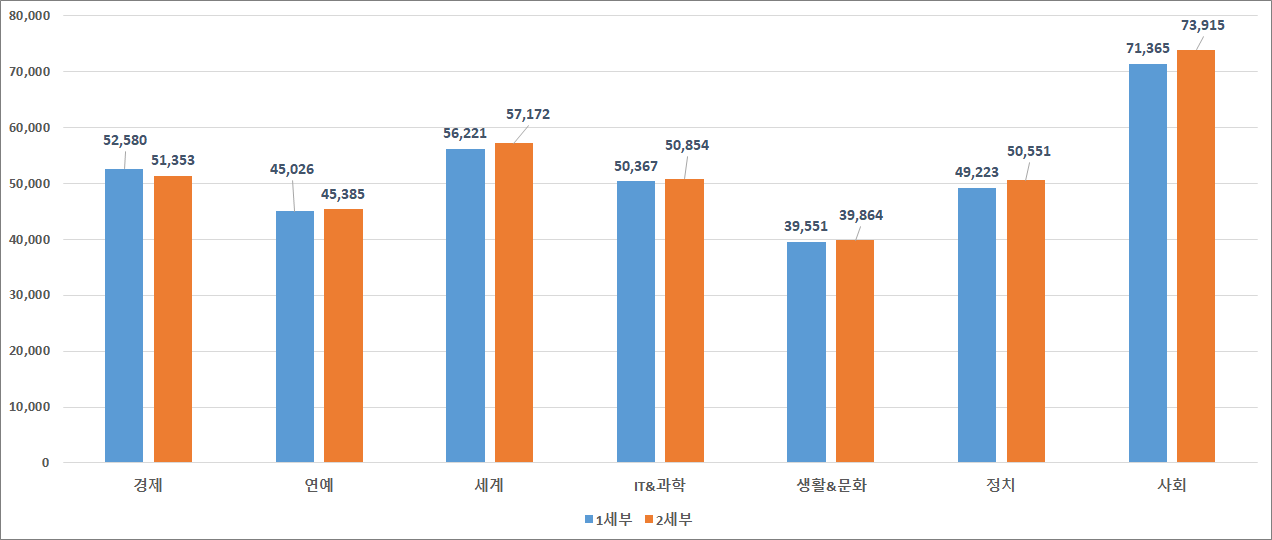
▶직접생성 가공패턴유형별 분포
직접생성 가공패턴유형별 분포 세부 가공패턴유형 건수 비율 1세부 (11) 의문 유발형(부호) 18,540 37.00% (12) 의문 유바령(은닉) 14,616 29.20% (13) 선정표현 사용형 4,418 8.80% (14) 속어/줄임말 사용형 4,669 9.30% (15) 사실 과대 표현형 5,280 10.50% (16) 의도적 주어 왜곡형 2,608 5.20% 합 계 50,131 100% 2세부 (21) 상품 판매정보 노출 광고형 11,433 22.80% (22) 부동산 판매정보 노출 광고형 6,084 12.10% (23) 서비스 판매정보 노출 광고형 12,235 24.40% (24) 의도적 상황 왜곡/전환형 20,387 40.70% 합 계 50,139 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드낚시성 기사 분류모델 : HAND(Hierarchical Attention Networks for Document Classification)
1. 모델 개요
• HAND 모델은 Word Attention Layer와 Sentence Attention Layer로 구성된 두 단계의 Hierarchical Attention 구조를 통해 서로 연속된 두 문장의 일관성을 파악하기 위한 용도로 활용
• 본 과제에서는 HAND 모델을 이용하여 뉴스 기사의 제목과 본문의 일관성 여부를 파악하는 것을 목표로 함2. 모델 구조
• HAND 모델의 구조는 크게 단어 수준의 Hidden Representation을 구하는 부분과 문장 수준의 Hidden Representation을 구하는 부분으로 나누어 볼 수 있음
• 가장 먼저 Word Encoder를 통해 문장별 단어 임베딩()을 입력으로 받은 후, GRU Layer와 Attention을 수행하여 단어별 Hidden Representation을 구함
• 이후 문장별로 각 문장에 속한 단어의 Hidden Representation을 가중합하여 Sentence Vector()를 구성
• Sentence Vector를 Sentence Encoder에서 Attention 과정을 거쳐 Hidden Representation을 구함
• 최종 Hidden Representation을 일치/불일치로 판별 할 수 있도록 Fully Connected Layer를 통해 계산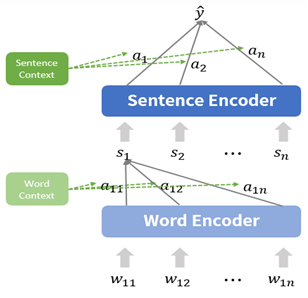
[그림] 낚시성 기사 분류를 위한 HAND 모델 구조
3. 입력 형태
• Shape : (Batch Size, Sentence Length, Word Length)
- Batch Size : Batch 내 샘플 개수 (Default = 256)
- Sentence Length : 하나의 샘플을 구성할 최대 문장 개수 (Default = 16)
- Word Length : 하나의 문장을 구성할 최대 단어 개수 (Default = 64)4. 출력 형태
• Shape : (Batch Size, Number of Classes)
• Number of Classes = 2 (정상/낚시)
주제분리탐지 모델 : BERT(Bidirectional Encoder Representations from Transformers)1. 모델 개요
• BERT를 이용한 주제 분리는 서로 연속된 두 문장의 연관성을 파악하고, 연관성의 유무에 따라 문장을 구분하는 것이 목표인 방법론
• 본 과제에서는 BERT를 이용한 주제 분리 방법을 이용하여 뉴스 기사의 본문 일관성 여부를 파악하는 것을 목표로 함
2. 모델 구조• [CLS] token과 두 개의 문장(, )을 구분하는 [SEP] token으로 입력 데이터를 구성
• Self-Attention Layer로 구성된 BERT Encoder를 통해 두 문장 간 문맥을 반영하는 Hidden Representation 계산
• Encoder의 출력 값인 [CLS] token의 Hidden Representation()을 일관성 여부로 나타내도록 Fully Connected Layer(Classifier)을 통해 계산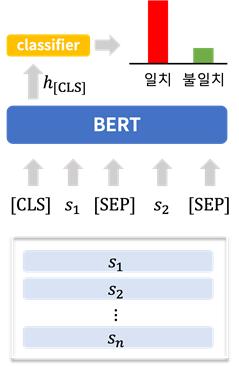
[그림] 주제분리탐지 모델을 위한 BERT 모델 구조
3. 입력 형태
• Shape : (batch size, max input length)
- Batch Size : Batch 내 샘플 개수 (Default = 8)
- Max Input Length : token의 최대 개수 (Default = 512)
- 입력값 구성 요소
source_ids : 각 token의 인코딩 id
segment_ids : 두 문장을 구분하는 id
mask_ids : padding이 된 부분과 실제 tokenb.을 구분해주는 id4. 출력 형태
• Shape : (Batch Size, Number of Classes)
• Number of Classes = 2 (일치/불일치)
모델 평가 결과모델 평가 결과 평가대상 평가지표 품질목표 평가결과 낚시성 기사 분류 모델(HAND) 성능 Accuracy 60% 87.10% 본문 주제분리탐지 모델(BERT) 성능 Accuracy 55% 83.88% F1-Score 55% 90.80% 서비스 활용 시나리오
• 언론 심의기관이 뉴스기사에 대한 심의 시 사전심의 도구로 활용하여 심의대상 선별
• 뉴스를 기반으로 하는 다양한 플랫폼 사업자/포탈에서 뉴스기사에 대한 자율규제 도구로 활용하여, 제공 뉴스에 대한 필터링 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 낚시성 기사 분류 모델(HAND) 성능 Text Classification HAND, BTS Accuracy 60 % 87.1 % 2 본문 주제 분리 탐지 모델(BERT) 성능 Text Classification HAND, BTS Accuracy 55 % 83.88 % 3 본문 주제 분리 탐지 모델(BERT) 성능 Text Classification HAND, BTS F1-Score 점 0.908 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷
원문데이터 구성 : 제목과 본문의 불일치 기사(1세부)
원문데이터 구성 구분 항목 항목명 항목 예시 원천 newsID 기사ID GB_M11_181695 newsCategory 기사카테고리 세계 newsSubcategory 기사하위카테고리 미국ㆍ캐나다 newsTitle 기사제목 도지코인도 5% 상승한 26센트에 거래돼(상보) newsSubTitle 기사부제목 newsContent 기사본문 최근 연일 하락했던 도지코인도 5% 반등에 성공했다.(중략) partNum 세부번호 P1 useType 용도유형 0 (← 낚시성) processType 처리유형 D (← 직접생성) processPattern 처리패턴 12 (← 의문유발형(은닉)) processLevel 처리수준(난이도) 하 sentenceCount 문장수 6 문장 sentenceNo 문장번호 1 sentenceContent 문장내용 최근 연일 하락했던 도지코인도 ... sentenceSize 문장길이 29 라벨링 newTitle 기사새제목 최근 연일 하락했던 이것도 5% 반등에 성공 cickbaitClass 낚시기사분류 0 (← 낚시) 문장 sentenceNo 문장번호 1 referSenteceyn 참조문장여부 Y JSON 형식 : 제목과 본문의 불일치 기사(1세부)
JSON 형식 {
"sourceDataInfo": {
"newsID": "GB_M11_181695",
"newsCategory": "세계",
"newsSubcategory": "미국ㆍ캐나다",
"newsTitle": "도지코인도 5% 상승한 26센트에 거래돼(상보)",
"newsSubTitle": "",
"newsContent": "최근 연일 하락했던 도지코인도 5% 반등에 성공했다.\n도지코인은 27일 오전 6시10분 현재(한국시간 기준) 코인마켓캡에서 24시간 전보다 5.05% 상승한 26.38센트를 기록하고 있다.\n도지코인은 수시간 전 33센트까지 오르기도 했다.\n도지코인이 상승한 것은 저가 매수세가 유입됐기 때문으로 보인다.\n도지코인은 4월 20일 '도지데이'를 앞두고 43센트까지 오르는 등 랠리를 펼치다 도지데이 이후 5일 연속 급락했었다.\n한편 같은 시각 한국의 거래사이트인 업비트에서 도지코인은 24시간 전보다 1.29% 상승한 313원에 거래되고 있다.",
"partNum": "P1",
"useType": 0,
"processType": "D",
"processPattern": "12",
"processLevel": "하",
"sentenceCount": 6,
"sentenceInfo": [
{
"sentenceNo": 1,
"sentenceContent": "최근 연일 하락했던 도지코인도 5% 반등에 성공했다.",
"sentenceSize": 29
},
{
"sentenceNo": 2,
"sentenceContent": "도지코인은 27일 오전 6시10분 현재(한국시간 기준) 코인마켓캡에서 24시간 전보다 5.05% 상승한 26.38센트를 기록하고 있다.",
"sentenceSize": 75
},
{
"sentenceNo": 3,
"sentenceContent": "도지코인은 수시간 전 33센트까지 오르기도 했다.",
"sentenceSize": 27
},
{
"sentenceNo": 4,
"sentenceContent": "도지코인이 상승한 것은 저가 매수세가 유입됐기 때문으로 보인다.",
"sentenceSize": 35
},
{
"sentenceNo": 5,
"sentenceContent": "도지코인은 4월 20일 '도지데이'를 앞두고 43센트까지 오르는 등 랠리를 펼치다 도지데이 이후 5일 연속 급락했었다.",
"sentenceSize": 66
},
{
"sentenceNo": 6,
"sentenceContent": "한편 같은 시각 한국의 거래사이트인 업비트에서 도지코인은 24시간 전보다 1.29% 상승한 313원에 거래되고 있다.",
"sentenceSize": 65
}
]
},
"labeledDataInfo": {
"newTitle": "최근 연일 하락했던 이것도 5% 반등에 성공",
"clickbaitClass": 0,
"referSentenceInfo": [
{
"sentenceNo": 1,
"referSentenceyn": "Y"
},
{
"sentenceNo": 2,
"referSentenceyn": "N"
},
{
"sentenceNo": 3,
"referSentenceyn": "N"
},
{
"sentenceNo": 4,
"referSentenceyn": "N"
},
{
"sentenceNo": 5,
"referSentenceyn": "N"
},
{
"sentenceNo": 6,
"referSentenceyn": "N"
}
]
}
}어노테이션 포맷 : 제목과 본문의 불일치 기사(1세부)
어노테이션 포맷 구분 항목 항목명 타입 필수 1 sourceDataInfo 원천데이터정보 JsonObject 1 newsID 기사ID String Y 2 newsCategory 기사카테고리 String Y 3 newsSubcategory 기사하위카테고리 String N 4 newsTitle 기사제목 String Y 5 newsSubTitle 기사부제목 String N 6 newsContent 기사본문 String Y 7 partNum 세부번호 String Y 8 useType 용도유형 Number Y 9 processType 처리유형 String Y 10 processPattern 처리패턴 String Y 11 processLevel 처리수준(난이도) String Y 12 sentenceCount 문장수 String Y 13 sentenceInfo 문장정보 Array Y 1 sentenceNo 문장번호 Number Y 2 sentenceContent 문장내용 String Y 3 sentenceSize 문장길이 Number Y 2 labeledDataInfo 라벨링데이터정보 JsonObject 1 newTitle 새제목 String Y 2 clickbaitClass 낚시기사분류 Number Y 3 referSentenceInfo 참조문장정보 Array Y 1 sentenceNo 문장번호 Number Y 2 referSenteceyn 참조문장여부 String Y 원문데이터 구성 : 본문의 도메인 일관성 부족 기사(2세부)
원문데이터 구성 구분 항목 항목명 항목 예시 원천 newsID 기사ID GB_M11_642158 newsCategory 기사카테고리 세계 newsSubcategory 기사하위카테고리 국제경제 newsTitle 기사제목 신종 코로나 악재, 중국 본토 증시 9%대 폭락 newsSubTitle 기사부제목 newsContent 기사본문 중국 본토 증시가 9%대 폭락세로 개장했다.(중략) partNum 세부번호 P2 (← 2세부) useType 용도유형 0 (← 낚시성) processType 처리유형 D (← 직접생성) processPattern 처리패턴 22 (← 부동산 판매정보 노출 광고형) processLevel 처리수준 중 (← 난이도) sentenceCount 문장수 6 processSentencenum 처리문장수 2 (← 가공문장수) 문장 sentenceNo 문장번호 1 sentenceContent 문장내용 중국 본토 증시가 9%대 폭락세로 개장했다. sentenceSize 문장길이 24 라벨링 문장 sentenceNo 문장번호 1 sentenceContent 문장내용 중국 본토 증시가 9%대 폭락세로 개장했다. subjectConsistencyYn 주제일관성여부 Y clickbaitClass 낚시기사분류 0 JSON 형식 : 본문의 도메인 일관성 부족 기사(2세부)
JSON 형식 {
"sourceDataInfo": {
"newsID": "GB_M11_642158",
"newsCategory": "세계",
"newsSubcategory": "국제경제",
"newsTitle": "신종 코로나 악재, 중국 본토 증시 9%대 폭락",
"newsSubTitle": "",
"newsContent": "중국 본토 증시가 9%대 폭락세로 개장했다.\n3일 개장 직후 상하이 종합지수는 8.6% 급락했고 선전종합지수는 8.8% 미끄러졌다.\n선전성분지수는 9% 폭락했다.\n중국 본토 증시는 지난달 23일 이후 휴장했다가 거의 열흘 만에 거래를 재개했다.\n원래 지난달 31일 개장할 예정이었으나 신종 코로나 확산을 막기 위해 정부가 연휴를 연장하면서 개장일은 3일로 미뤄졌다.\n도쿄 증시의 닛케이 225지수는 1.6%대, 한국의 코스피 역시 1.5% 낙폭을 보이고 있다.",
"partNum": "P2",
"useType": 0,
"processType": "D",
"processPattern": "22",
"processLevel": "중",
"sentenceCount": 6,
"processSentencenum": 2,
"sentenceInfo": [
{
"sentenceNo": 1,
"sentenceContent": "중국 본토 증시가 9%대 폭락세로 개장했다.",
"sentenceSize": 24
},
{
"sentenceNo": 2,
"sentenceContent": "3일 개장 직후 상하이 종합지수는 8.6% 급락했고 선전종합지수는 8.8% 미끄러졌다.",
"sentenceSize": 48
},
{
"sentenceNo": 3,
"sentenceContent": "선전성분지수는 9% 폭락했다.",
"sentenceSize": 16
},
{
"sentenceNo": 4,
"sentenceContent": "중국 본토 증시는 지난달 23일 이후 휴장했다가 거의 열흘 만에 거래를 재개했다.",
"sentenceSize": 45
},
{
"sentenceNo": 5,
"sentenceContent": "원래 지난달 31일 개장할 예정이었으나 신종 코로나 확산을 막기 위해 정부가 연휴를 연장하면서 개장일은 3일로 미뤄졌다.",
"sentenceSize": 67
},
{
"sentenceNo": 6,
"sentenceContent": "도쿄 증시의 닛케이 225지수는 1.6%대, 한국의 코스피 역시 1.5% 낙폭을 보이고 있다.",
"sentenceSize": 52
}
]
},
"labeledDataInfo": {
"processSentenceInfo": [
{
"sentenceNo": 1,
"sentenceContent": "중국 본토 증시가 9%대 폭락세로 개장했다.",
"subjectConsistencyYn": "Y"
},
{
"sentenceNo": 2,
"sentenceContent": "3일 개장 직후 상하이 종합지수는 8.6% 급락했고 선전종합지수는 8.8% 미끄러졌다.",
"subjectConsistencyYn": "Y"
},
{
"sentenceNo": 3,
"sentenceContent": "선전성분지수는 9% 폭락했다.",
"subjectConsistencyYn": "Y"
},
{
"sentenceNo": 4,
"sentenceContent": "중국 본토 증시는 지난달 23일 이후 휴장했다가 거의 열흘 만에 거래를 재개했다.",
"subjectConsistencyYn": "Y"
},
{
"sentenceNo": 5,
"sentenceContent": "원래 지난달 31일 개장할 예정이었으나 신종 코로나 확산을 막기 위해 정부가 연휴를 연장하면서 개장일은 3일로 미뤄졌다.",
"subjectConsistencyYn": "Y"
},
{
"sentenceNo": 6,
"sentenceContent": "도쿄 증시의 닛케이 225지수는 1.6%대, 한국의 코스피 역시 1.5% 낙폭을 보이고 있다.",
"subjectConsistencyYn": "Y"
},
{
"sentenceNo": 7,
"sentenceContent": "중국 본토 증시가 폭락세로 가고 있다는 소식이 전해진 가운데, 우리나라 여행지 중 중국인들이 가장 좋아하는 곳으로 알려진 제주도에, 그린건설이 건설 중인 `하늘타운하우스`의 분양 소식이 전해졌다. ",
"subjectConsistencyYn": "N"
},
{
"sentenceNo": 8,
"sentenceContent": "하늘타운하우스는 총 52세대만 분양하는 고급타운하우스로 전 세대에서 바다 전망을 볼 수 있으며, 단독 세대로 분리되어 있어 사생활 보호가 가능한 주택이라, 벌써 사람들의 문의가 빗발치고 있어 관심이 있는 분이라면 하늘타운하우스 분양 사무실로 분양 문의를 서두르는 것이 좋다.",
"subjectConsistencyYn": "N"
}
],
"clickbaitClass": 0
}
}어노테이션 포맷 : 본문의 도메인 일관성 부족 기사(2세부)
어노테이션 포맷 구분 항목 항목명 타입 필수 1 sourceDataInfo 원천데이터정보 JsonObject 1 newsID 기사ID String Y 2 newsCategory 기사카테고리 String Y 3 newsSubcategory 기사하위카테고리 String N 4 newsTitle 기사제목 String Y 5 newsSubTitle 기사부제목 String N 6 newsContent 기사본문 String Y 7 partNum 세부번호 String Y 8 useType 용도유형 Number Y 9 processType 처리유형 String Y 10 processPattern 처리패턴 String Y 11 processLevel 처리수준(난이도) String Y 12 sentenceCount 문장수 String Y 13 processSentencenum 처리문장수 Number Y 14 sentenceInfo 문장정보 Array Y 1 sentenceNo 문장번호 Number Y 2 sentenceContent 문장내용 String Y 3 sentenceSize 문장길이 Number Y 2 labeledDataInfo 라벨링데이터정보 JsonObject 1 processSentenceInfo 처리문장정보 Array Y 1 sentenceNo 문장번호 Number Y 2 sentenceContent 문장내용 String Y 3 subjectConsistencyYn 주제일치여부 String Y 2 clickbaitClass 낚시기사분류 Number Y -
데이터셋 구축 담당자
수행기관(주관) : 비플라이소프트㈜
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 양대헌 070-4490-7061 [email protected] 데이터 수집, 정제, 검수, AI 모델 개발 수행기관(참여)
수행기관(참여) 기관명 담당업무 서울시스템㈜ 데이터 정제 ㈜미디어그룹사람과숲 저작도구/뷰어, 1세부 데이터 가공/가공검수 ㈜솔트룩스 2세부 데이터 가공/가공검수 ㈜오피니언라이브 데이터 품질 관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 양대헌 070-4490-7061 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.