-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2024-05-03 데이터 최종 개방 1.1 2023-08-29 원천데이터 및 라벨링데이터 수정 1.0 2023-04-30 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-01 산출물 전체 공개 소개
다양한 감성과 발화스타일을 동시 고려하는 인공지능 기술 개발을 위한 학습용 음성합성 데이터
구축목적
비대면 사회 전환과 기술, 산업 환경 변화에 따라 UI와 상품으로 음성 데이터에 대한 필요성이 증대되고 있음. 그러나 보다 자연스러운 한국어 인공지능을 위한 발화스타일 연구는 부족한 상황. 업계나 학계에서 활용할 수 있는 수준의 품질과 범용성을 갖춘 음성 데이터의 신속한 구축 필요.
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 , 텍스트 데이터 형식 txt. WAV 데이터 출처 자체수집 라벨링 유형 감성음성 라벨링 형식 json 데이터 활용 서비스 로봇, 메타버스, 인공지능 스피커, 키오스크, 가상 아바타 서비스, 게임, 감정 테라피, 재활, 돌봄 서비스 등 더 다양한 서비스에서 TTS 엔진 활용 데이터 구축년도/
데이터 구축량2022년/1,000 시간 -
1. 데이터 구축 규모
1.1 구축 목표 및 결과데이터 구축 규모 번호 발화 스타일 획득 목표 구축 목표 구축 결과 감정별 대본 수 대본 개수 7가지 1200 1000 1012 기쁨 슬픔 분노 무감정 63 1 독백체 200 167 166 3 3 3 2 11 2 대화체 200 167 168.6 3 3 3 2 11 3 구연체 200 167 168.6 3 3 3 2 11 4 중계체 150 124 128.4 선수소개/일반설명/득점상황 9 5 친절체 200 167 167.4 3 2 2 3 10 6 애니체 200 167 173.3 3 3 3 1 10 7 낭독체 50 41 40 - - - 1 1 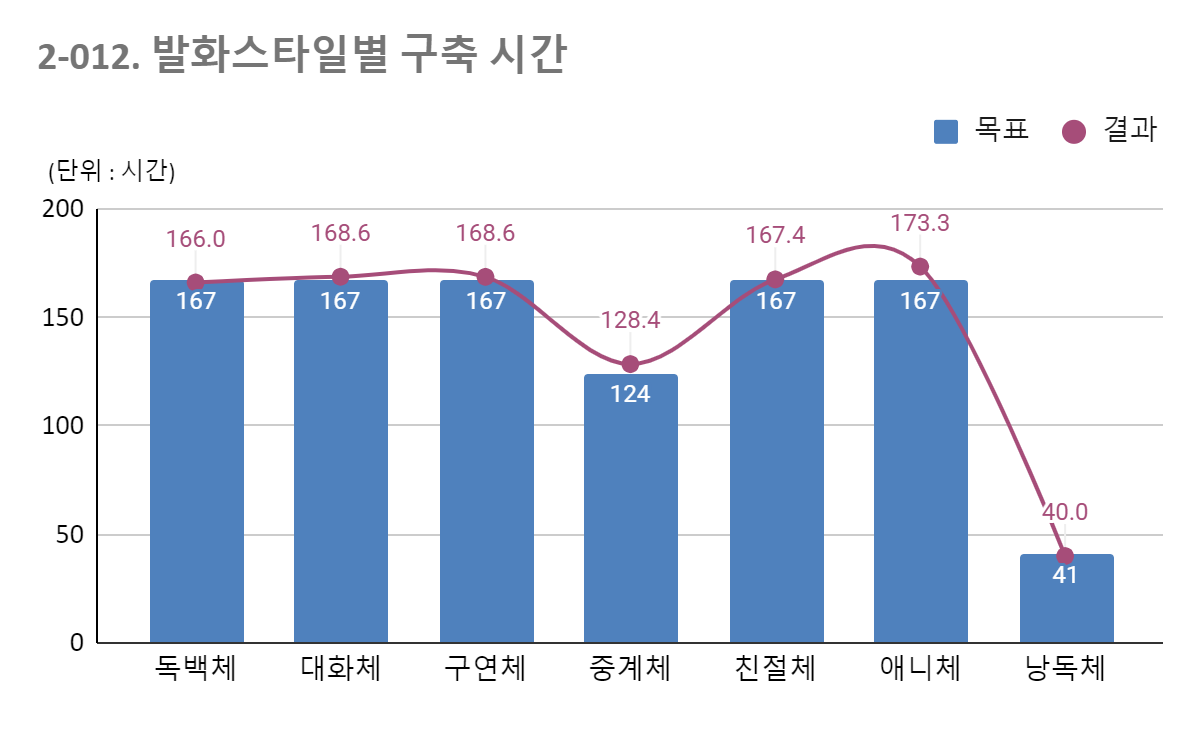
2. 데이터 분포
2.1 스타일에 따른 다양한 대본 소스 및 비율
애니체, 친절체, 중계체 등 발화 스타일 특성에 맞춰 대본 구성함. 독백체, 대화체, 구연체는 작품 시대를 고려하여 대본 제작.데이터 분포 대분류 대본 소스 문장 수 비율(%) 애니체 액션/모험 17,316 18% 추리/판타지 15,709 17% 코믹/명랑 17,470 18% 학원/로맨스 17,170 18% 소스 없음 26,799 28% 합계 94,464 100% 친절체 헬프데스크 9753 10% 전화상담 65,282 66% 매장응대 23942 24% 합계 98,977 100% 중계체 축구 42,432 53% 야구 37,840 47% 합계 80,272 100% 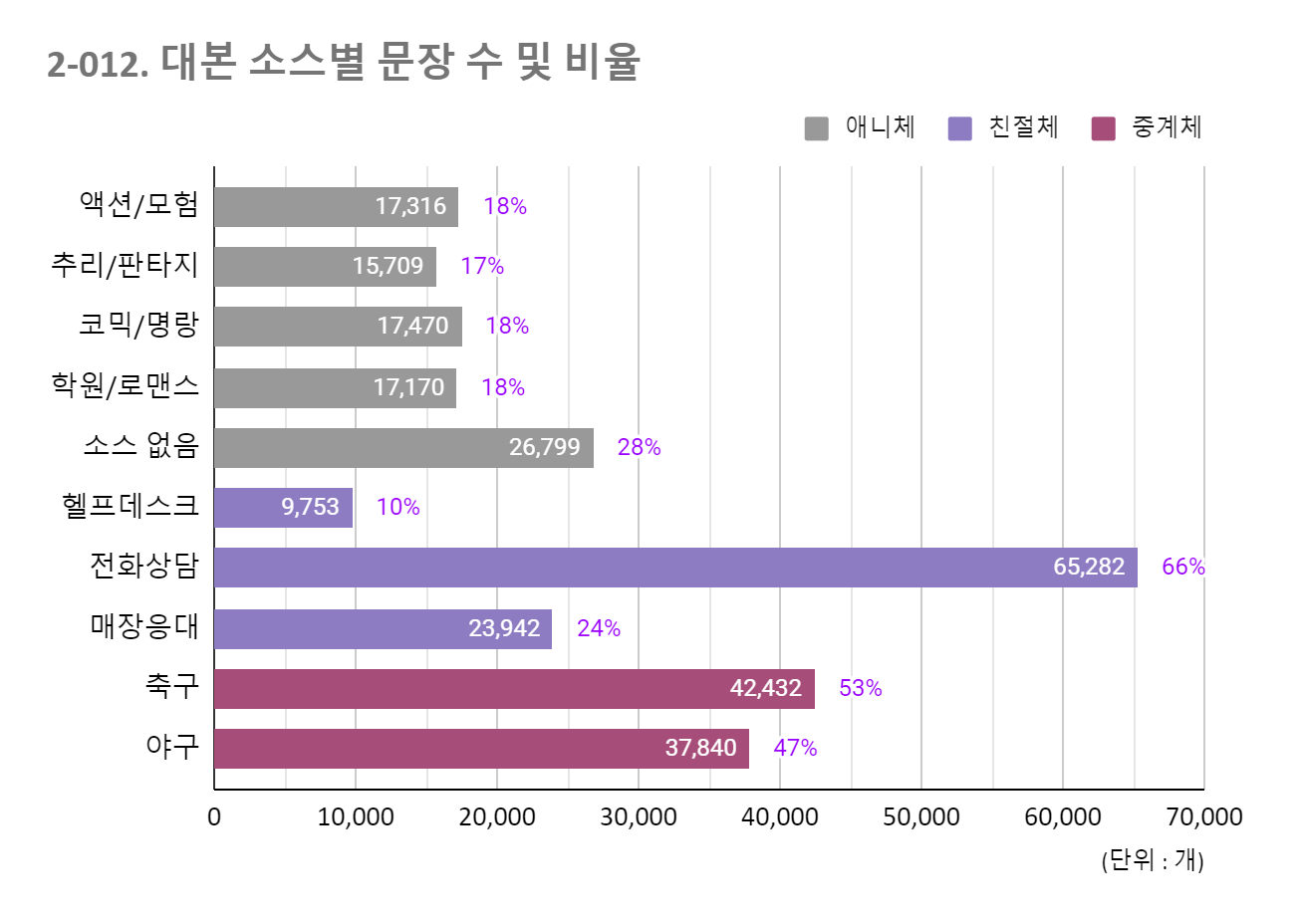
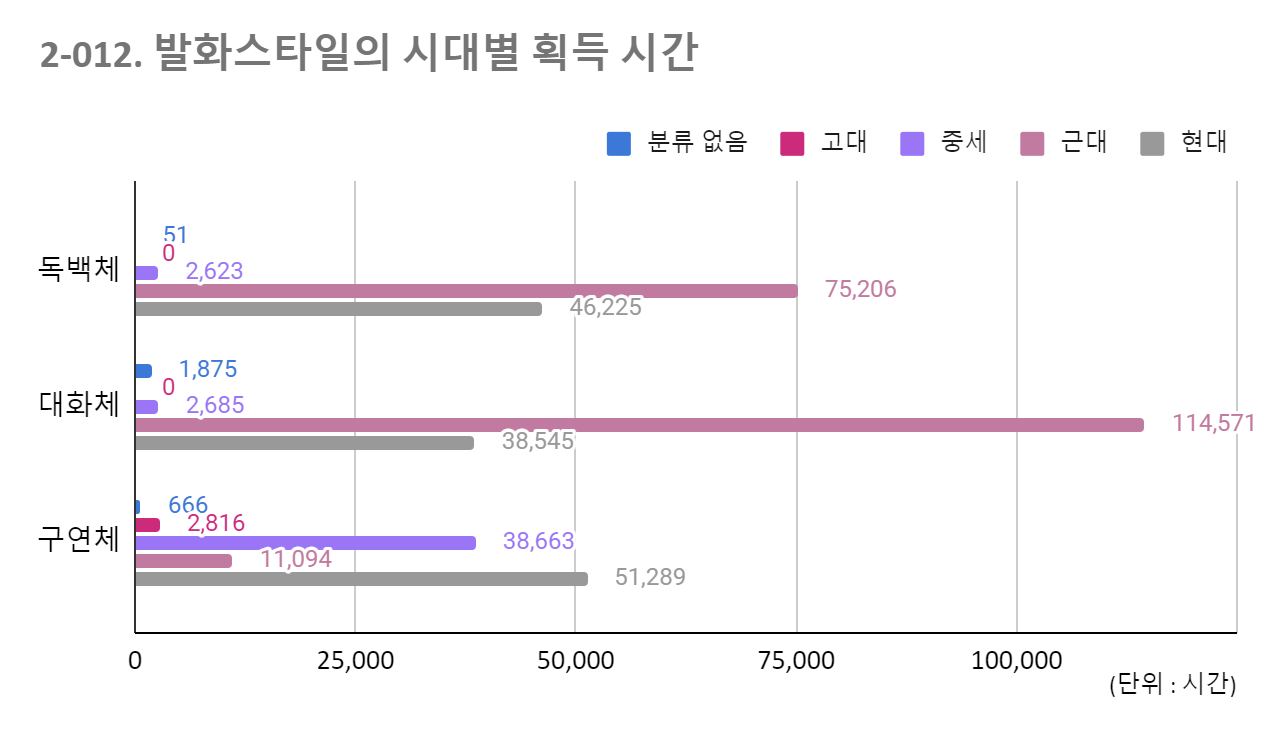
발화스타일의 시대별 획득 시간 대분류 고대 중세 근대 현대 합계 독백체 0 2,674 75,206 46,225 124,105 0.00% 2.15% 60.60% 37.25% 100.00% 대화체 0 2,685 116,581 38,410 157,676 0.00% 1.70% 73.94% 24.36% 100.00% 구연체 2,816 38,663 11,732 51,317 104,528 2.69% 36.99% 11.22% 49.09% 100.00% 합계 2,816 44,022 203,519 135,952 386,309 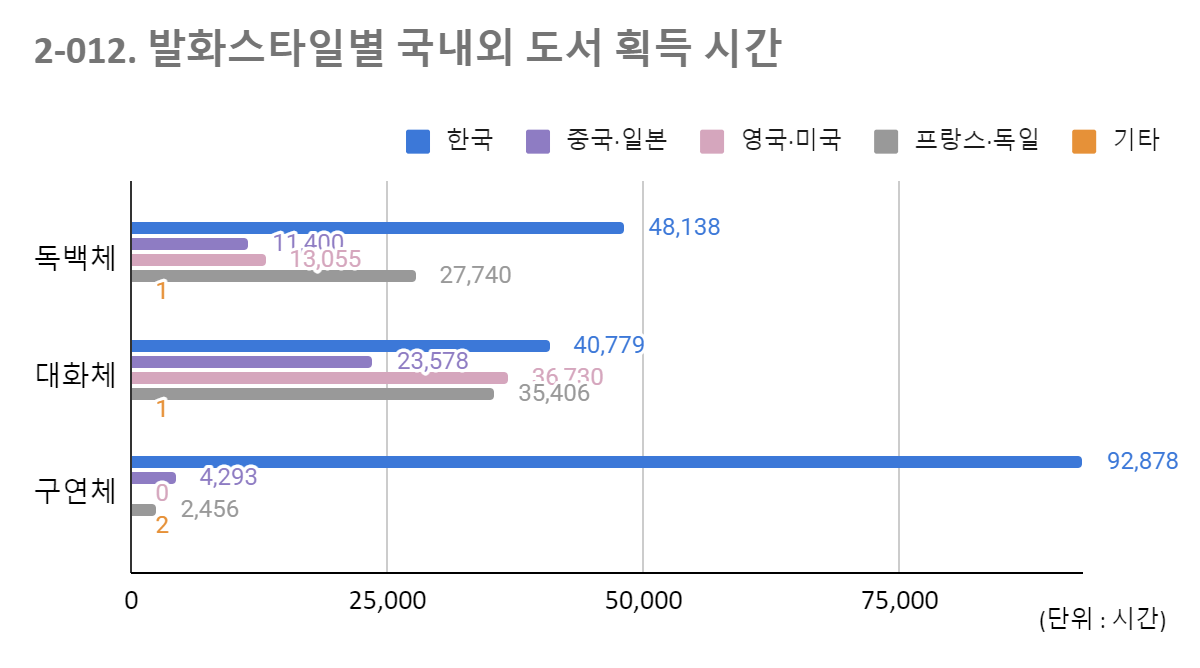
발화스타일별 국내외 도서 획득 시간 이미지 대분류 한국 중국 영국 프랑스 기타 합계 일본 미국 독일 독백체 48,138 11,400 13,055 27,740 1 100,334 47.98% 11.36% 13.01% 27.65% 0.00% 100% 대화체 40779 23578 36730 35406 1 136,494 29.88% 17.27% 26.91% 25.94% 0.00% 100% 구연체 92878 4293 0 2456 2 99,629 93.22% 4.31% 0.00% 2.47% 0.00% 100% 합계 181,795 39,271 49,785 65,602 4 336,457 비율(%) 54.03% 11.67% 14.80% 19.50% 0.00% 100% 2.2 감정별 획득시간
기쁨, 슬픔, 분노, 무감정을 적절히 구성함.2 감정별 획득시간 번호 발화스타일 획득 기쁨 슬픔 분노 무감정 1 독백체 166 40.9 45.2 39.4 40.4 2 대화체 168.6 42.4 46.2 40.1 39.9 3 구연체 168.6 42.5 45.3 39.4 41.3 4 중계체 128.4 0 0 0 128.4 5 친절체 167.4 40.7 43.9 42.5 40.2 6 애니체 173.3 42.1 49.3 40.6 41.2 7 낭독체 40 0 0 0 40 합계(시간) 1012.1 208.6 229.9 202.1 371.4 분포(%) 100.00% 20.60% 22.70% 20.00% 36.70% 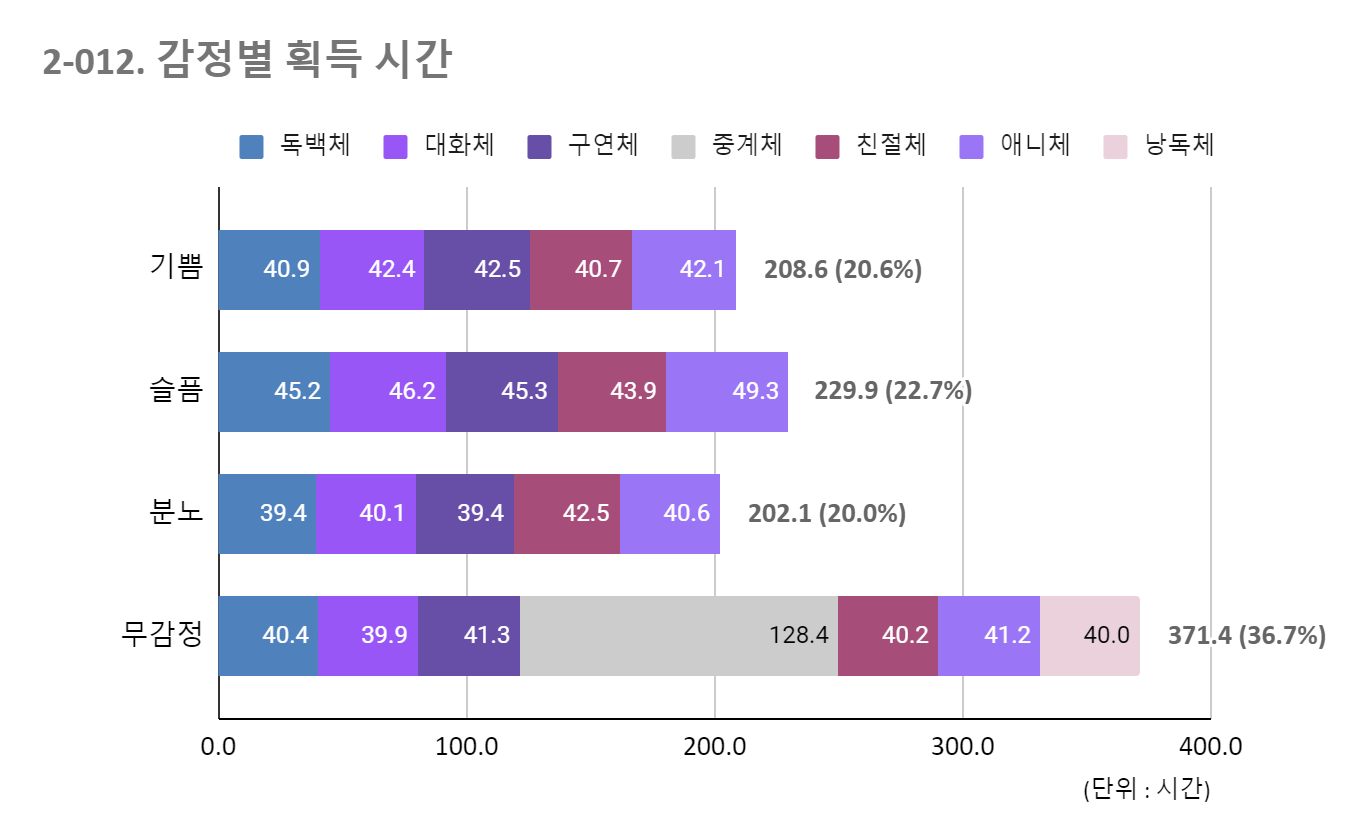
2.3 다양한 연령층
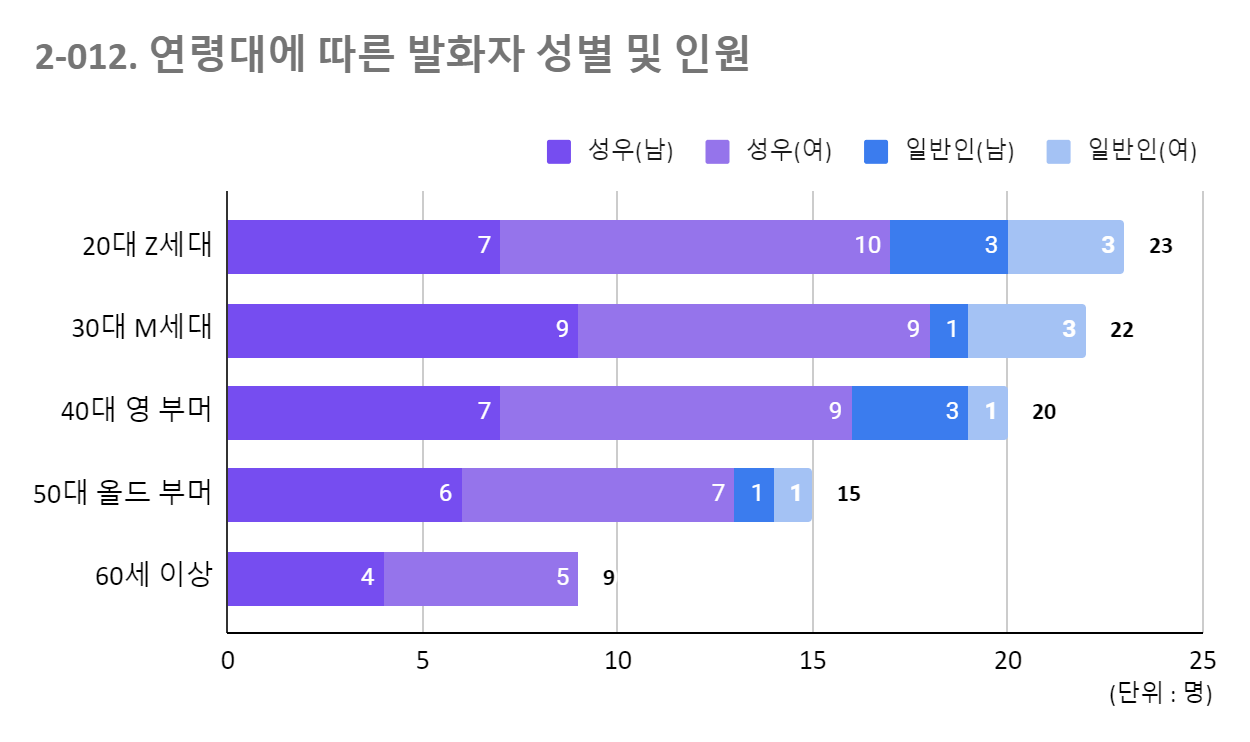
3 다양한 연령층 연령대 목표% 결과% 시간 명수 성우 일반인 남 녀 남 녀 20대 Z세대 25 26 263 23 7 10 3 3 30대 M세대 25 24 241 22 9 9 1 3 40대 영 부머 24 24 240 20 7 9 3 1 50대 올드 부머 16 16 161 15 6 7 1 1 60세 이상 11 11 107 9 4 5 0 0 소계 100 100 1012 89 33 40 8 8 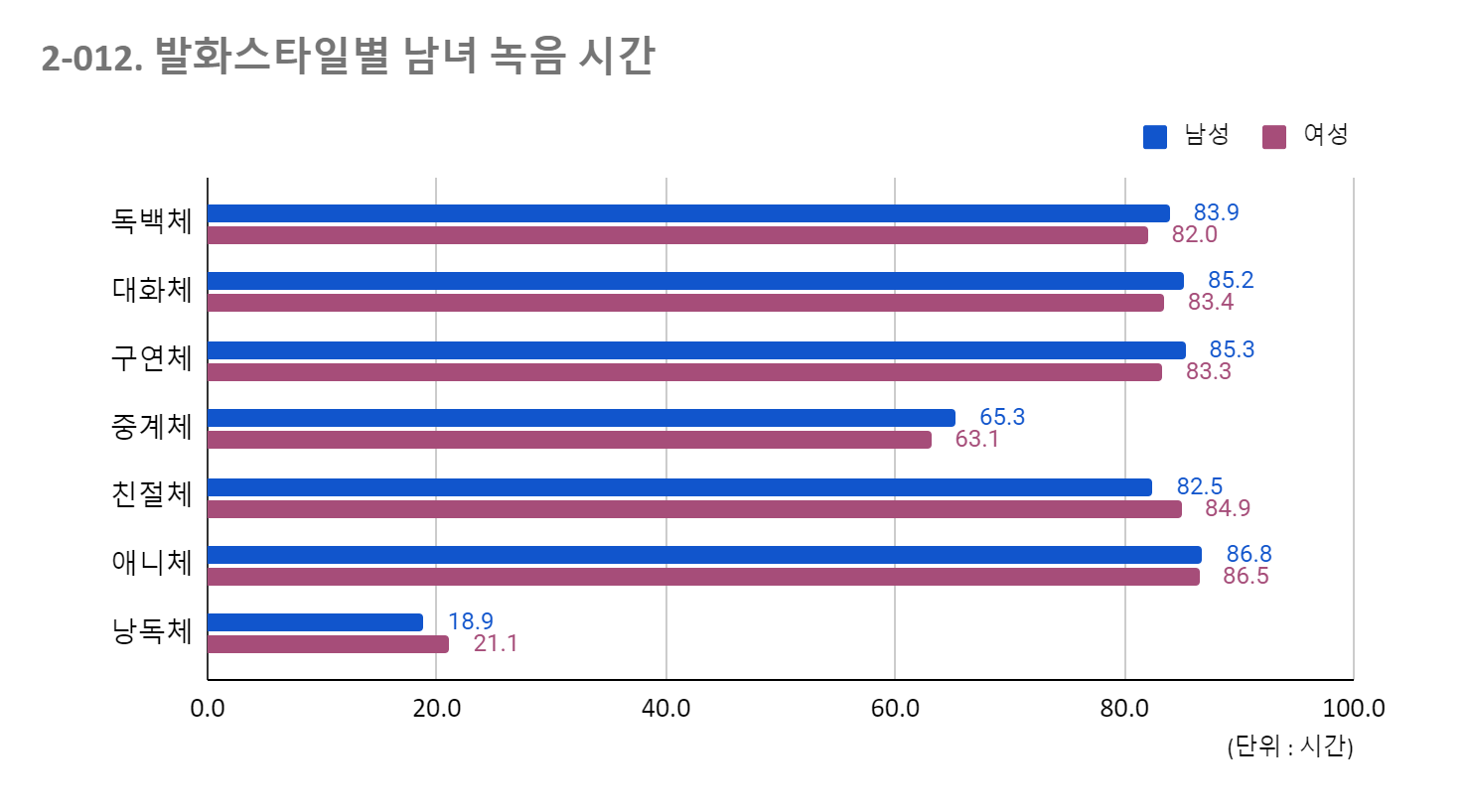
2.4 어절 수 분포
2.4 어절 수 분포 어절 수 개수 분포 1~5 127,447 18.60% 6~10 316,370 46.10% 11~15 193,307 28.10% 16~20 39,145 5.70% 20 이상 10,527 1.50% 합계 686,796 100.00% 평균(어절 수) 9.3 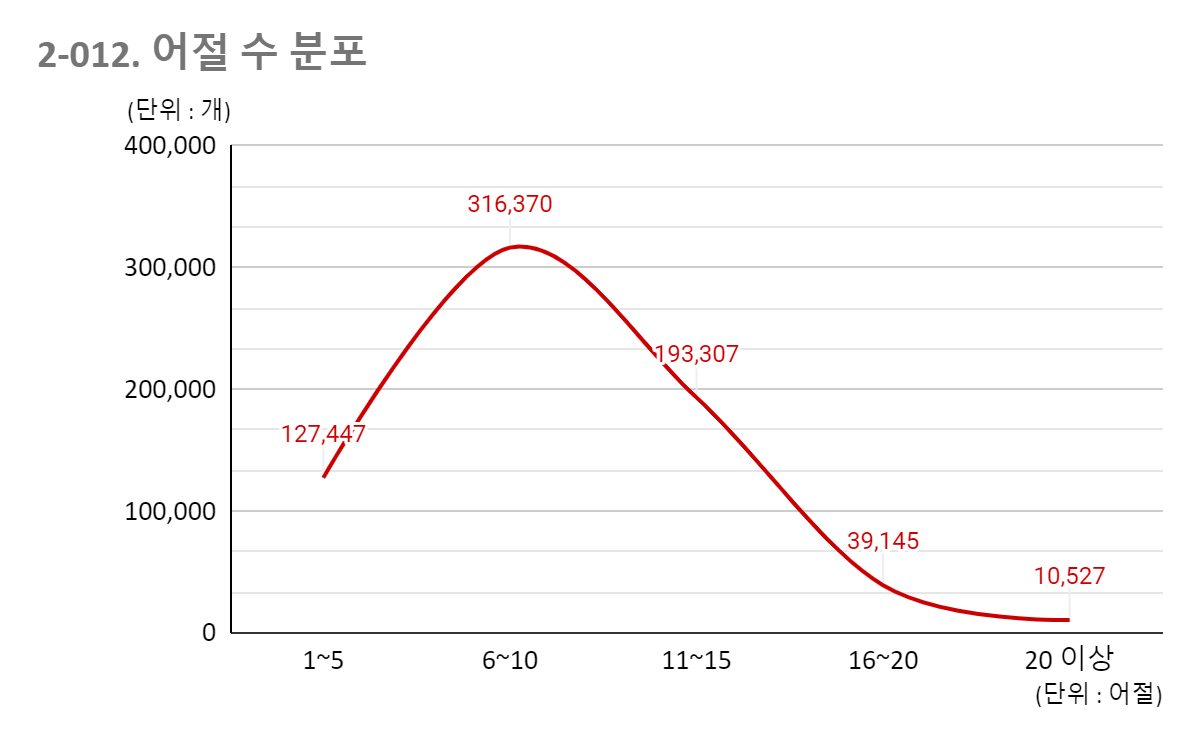
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드● 활용 모델
1. 모델 학습
• 데이터 구축을 통해 생성된 화자 정보와 감정의 종류는 각각 Speaker ID + Emotion ID 조합으로 입력되고, Reference Audio를 Style embedding을 통해 입력.
• Style embedding은 훈련의 사용되는 문장의 음성파일을 Reference audio로 입력하여 audio에 담긴 스타일을 직접 모델에 입력하여 직접적으로 스타일을 학습시키는 역할을 하며 분리된 토큰을 이용하여 스타일의 변화를 줄 수 있음.• 본 과제에서 제안된 모델을 학습하기 위해 공개된 end-to-end 음성학습 툴킷인 ESPnet을 활용하여 TransformerTTS-GST 훈련을 진행함
• 수집된 68만6천건의 텍스트와 음성데이터를 6개의 스타일별(독백체, 대화체, 구연체, 중계체, 친절체, 애니체)로 분류하여, 음성합성 모델 학습활용 모델 학습 검증 시험 개요 - 공개된 end-to-end 음성학습 툴킷인 ESPnet을 활용하여 TransformerTTS-GST 훈련 - 학습 도중 모델 성과 평가 및 비교 - 모델 학습 완료 후 - 모델 테스트 필요 음원 스타일별 8만~15만건의 텍스트와 음성데이터 10%(스타일별 8천건 이상의 텍스트와 음성데이터) 10%(스타일별 8천건 이상의 텍스트와 음성데이터) 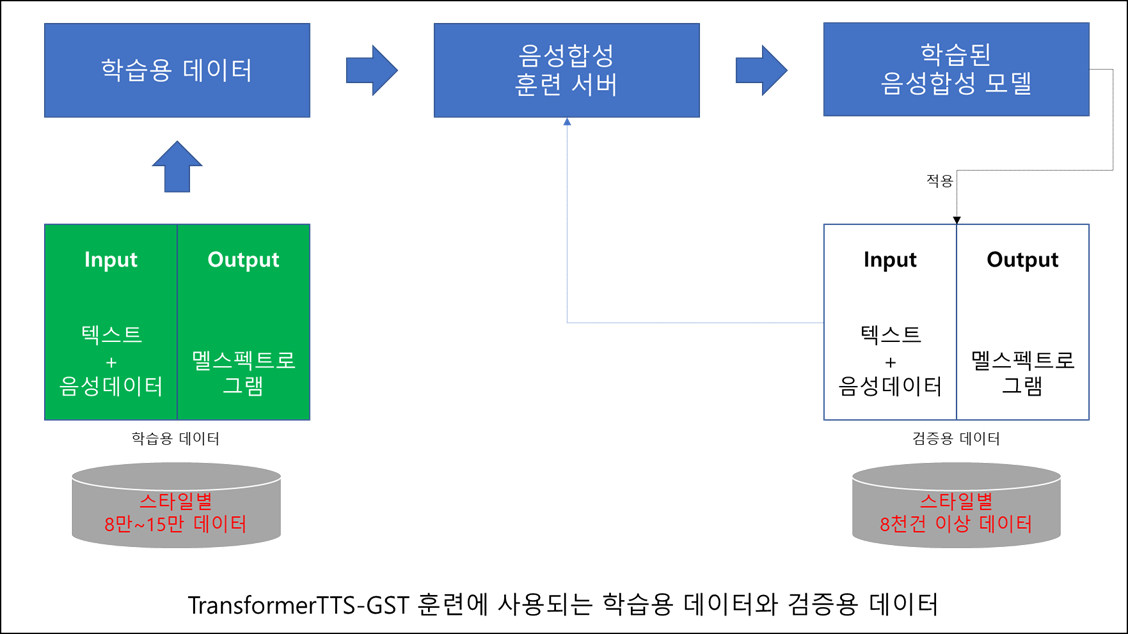
2. 서비스 활용 시나리오
• 고품질 데이터 공개로 업계와 학계의 연구와 상품화에 이바지. 로봇, 인공지능 스피커, 키오스크, 가상 아바타 서비스, 게임, 감정 테라피, 재활, 돌봄 서비스 등 더 다양한 서비스에서 TTS 활용 가능
• 고품질 TTS 보급으로 고품질 콘텐츠 제작 활성화 기여
• 고품질 TTS 보급으로 소상공인을 위한 디지털 서비스 지원 확대 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 음성합성 Speech Synthesis Transformer-GST MOS 3.6 점 3.74 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드음성 및 음성에 대한 스타일 태깅 어노테이션을 포함한 JSON 라벨링 및 메타 데이터
스타일 음성: WAV
음성 전사 및 스타일 태깅, 메타 데이터: JSON
스타일 태깅 정의: JSON
● 데이터셋 메타데이터셋 메타 No. 속성 명 항목 설명 타입 필수 작성예시 1 Dataset.id 데이터셋 식별자 string Y M-A301-P01-C-001 2 Dataset.src_type 녹음 상황 유형 string Y 작품 3 Dataset.import 작품(존재할 경우) 정보 객체 N 아래 참조 4 Dataset.script 대본 정보 객체 Y 아래 참조 5 Dataset.sentences 파트 내 문장 정보 객체의 배열 Y 아래 참조 6 Dataset.voice 음성파일 정보 객체 Y 아래 참조 7 Dataset.reciter 낭송자 정보 객체 Y 아래 참조 8 Dataset.studio 녹음환경 정보 객체 Y 아래 참조 작품(존재할 경우)에 대한 정보: import로 표기
작품(존재할 경우)에 대한 정보 No. 속성 명 항목 설명 타입 필수 작성예시 1 import.id 출처 작품 식별자 string Y M0007 2 import.book_title 출처 도서명 string Y 결혼 / 염라대왕 자오 / 오규교(終身大事 / 趙閻王 / 五奎橋) 3 import.title 출처 제목 string N 염라대왕 자오(趙閻王) 4 import.author 출처 저자 string Y 후스(胡適) / 훙선(洪深) 5 import.translator 출처 번역자 string Y 조득창 6 import.publish_year 출판 연도 number Y 2019 7 import.country 출처의 국가 string Y 중국 8 import.times_bg 시대적 배경 string Y 근대 대본에 대한 정보: script로 표기
대본에 대한 정보 No. 속성 명 항목 설명 타입 필수 작성예시 1 script.id 대본 식별자 string Y M-A301 2 script.part_no 대본 파트 번호 string Y 1 3 script.origin 대본 파트의 원문 string 배열 N ["다리 동쪽의 400여 마지기 논은 나 혼자서 경작한 게 아닌데...", ..] 4 script.normalized 대본 파트의 TN 처리 결과 string 배열 Y ["다리 동쪽의 사백 여 마지기 논은 나 혼자서 경작한 게 아닌데...", ..] 5 script.chars_count 대본 글자 수 number Y 1333 6 script.tokens_count 대본 어절 수 number Y 468 파트 내 문장들에 대한 정보: sentences로 표기
파트 내 문장들에 대한 정보 No. 속성 명 항목 설명 타입 필수 작성예시 1 sentences[].id 문장 식별자 string Y M-A3-C-001-0001 2 sentences[].origin_text 문장 원문 string Y 기다리라고 하다니, 이건 기다리는 게 아니란 말인가! 3 sentences[].voice_piece 음성파일 정보 객체 N 03월 01일 sentences[].voice_piece.filename 음성파일 이름 string Y M-A3-C-001-0001.wav 03월 02일 sentences[].voice_piece.tr 철자 전사 string Y 기다리라고 하다니, 이건 기다리는 게 아니란 말인가! 03월 03일 sentences[].voice_piece.ptr 발음 전사 string Y 기다리라고 하다니 / 이건 기다리는 게 아니란 말인가! 03월 04일 sentences[].voice_piece.duration 음성 구간길이 number Y 3.07999992 문장의 시작과 끝 03월 05일 sentences[].voice_piece.file_duration 음성파일 구간길이 number Y 3.57999992 sentences[].voice_piece.duration 앞뒤로 묵음 추가된 음원의 길이 4 sentences[].style 스타일 정보 객체 Y 04월 01일 sentences[].style.style 스타일 string Y 독백체 04월 02일 sentences[].style.emotion 감정 string Y 분노 04월 03일 sentences[].style.intensity 감정의 강도 number Y 2 04월 04일 sentences[].style.sub_style 스타일 추가 정보 string N (중계, 대화, 친절, 애니체에서 사용) 5 sentences[].votes 투표 정보 객체 배열 Y 05월 01일 sentences[].votes[].liker_scale 투표 결과 number Y 5 1: 매우 부적합 2: 부적합 3: 보통 4: 적합 5:매우 적합 05월 02일 sentences[].votes[].voter 투표자 객체 Y 05월 03일 sentences[].votes[].gender 투표자 성별 string Y FEMALE 05월 04일 sentences[].votes[].age 투표자 연령대 number Y 40 파트 음성파일에 대한 정보: voice로 표기
파트 음성파일에 대한 정보 No. 속성 명 항목 설명 타입 필수 작성예시 1 voice.filename 파트 음성파일 이름 string Y /data2/gst-voice/splitted/M/001/M-A301-P01-C-001.wav 2 voice.sample_rate 샘플 레이트 number Y 44100 3 voice.recorded_at 녹음 일시 timestamp Y 2022-09-06 0:45 4 voice.duration 녹음 길이 number Y 373.68 낭송자에 대한 정보: reciter로 표기
낭송자에 대한 정보 No. 속성 명 항목 설명 타입 필수 작성예시 1 reciter.id 낭송자 고유번호 number Y 1 2 reciter.gender 샘플 레이트 string Y MALE 3 reciter.age 녹음 일시 number Y 20 녹음환경에 대한 정보: studio로 표기
녹음환경에 대한 정보 No. 속성 명 항목 설명 타입 필수 작성예시 1 studio.id 녹음환경 고유 구분자 string Y C 2 studio.name 녹음환경 이름 string Y 스튜디오3 3 studio.mic 녹음에 사용된 마이크 기기 정보 string Y AKG C-414 XL ll, XLS 4 studio.micpre 녹음에 사용된 Micpre-amplifier 기기 정보 string Y Discrete 8 Synergy Core ● 원천데이터(대본 샘플)
M-S101
▶ 스타일 : 독백체
▶ 감정 : 슬픔
▶ 강도 : 약함
▶ 파트 번호 : 1, 2, 3원천데이터 예시 데이터 항목 json 형식 텍스트 독백체
분노
약함
1
M0006
최정혜
2022-06-28
이건 결혼할 때
가장 꺼리는 사주팔자인데.
뱀띠와 범띠가 서로 상극이고, 또한 해일과 신시가 돼지와 원숭이의 상극과 같으니, 이건 크게 꺼리는 사주다.스타일
{
"id": "M-S101-P01-A-039",
"src_type": "작품",
"import": {
"id": "M0006",
"book_title": "결혼 / 염라대왕 자오 / 오규교(終身大事 / 趙閻王 / 五奎橋)",
"title": "결혼(終身大事)",
"author": "후스(胡適) / 훙선(洪深)"
"translator": "조득창",
"publish_year": 2019,
"country": "중국",
"times_bg": "근대"
},
"script": {
"id": "M-S101",
"part_no": 1,
"origin": [
"이건 결혼할 때 가장 꺼리는 사주팔자인데.",
"뱀띠와 범띠가 서로 상극이고, 또한 해일과 신시가 돼지와 원숭이의 상극과 같으니, 이건 크게 꺼리는 사주다.", … ],
"normalized": [
"이건 결혼할 때 가장 꺼리는 사주팔자인데.",
"뱀띠와 범띠가 서로 상극이고, 또한 해일과 신시가 돼지와 원숭이의 상극과 같으니, 이건 크게 꺼리는 사주다.", … ],
"chars_count": 1338,
"tokens_count": 490
},
"sentences": [
{
"id": "M-S1-A-039-0001",
"origin_text": "이건 결혼할 때 가장 꺼리는 사주팔자인데.",
"voice_piece": {
"filename": "M-S1-A-039-0001.wav",
"tr": "이건 결혼할 때 가장 꺼리는 사주팔자인데.",
"ptr": "이건 / 결혼할 때 가장 꺼리는 사주팔자인데.",
"duration": 4.330000162124634,
"file_duration": 4.830000162124634
},
"style": {
"style": "독백체",
"emotion": "슬픔",
"intensity": 1,
"sub_style": "넋두리"
},
"votes": [
{
"likert_scale": 5,
"voter": {
"gender": "MALE",
"age": 20
}
},
{
"likert_scale": 5,
"voter": {
"gender": "MALE",
"age": 40
}
},
{
{ "likert_scale": 5,
"voter": {
"gender": "FEMALE",
"age": 60
}
}
]
},
{
"id": "M-S1-A-039-0002",
"origin_text": "뱀띠와 범띠가 서로 상극이고, 또한 해일과 신시가 돼지와 원숭이의 상극과 같으니, 이건 크게 꺼리는 사주다.",
"voice_piece": {
"filename": "M-S1-A-039-0002.wav",
"tr": "뱀띠와 범띠가 서로 상극이고, 또한 해일과 신시가 돼지와 원숭이의 상극과 같으니, 이건 크게 꺼리는 사주다.",
"ptr": "뱀띠와 범띠가 서로 상극이고 / 또한 / 해일과 신시가 / 돼지와 원숭이의 상극과 같으니 / 이건 / 크게 꺼리는 사주다.",
"duration": 11.779999732971191,
"file_duration": 12.279999732971191
},
"style": {
"style": "독백체",
"emotion": "슬픔",
"intensity": 1,
"sub_style": "넋두리"
},
"votes": [
{
"likert_scale": 5,
"voter": {
"gender": "MALE",
"age": 20
}
},
{
"likert_scale": 5,
"voter": {
"gender": "MALE",
"age": 40
}
},
{
"likert_scale": 5,
"voter": {
"gender": "FEMALE",
"age": 60
}
}
]
}, … ],
"voice": {
"filename": "/data2/gst-voice/splitted/M/039/M-S101-P01-A-039.wav",감정 강도 파트 번호 작품 번호 낭송자 이름 녹음일 낭송 스크립트 음성 M-S101-P01-A-039.wav 음성파일 정보 데이터 구분 구분 획득(수집) 단계 정제 단계 가공(라벨링) 단계 데이터 구분 원시데이터 원천데이터 최종데이터 데이터 형태 CSV, WAV JSON, WAV JSON, WAV 데이터 포맷 ○ 150문장씩 읽은 20분 안팎의 wav 파일
○ WAV 파일 기준Peak level : -1dB 이하
Noise Floor : -60dB 이하
음질 : 44.1kHz
채널 : Mono○ 50문장 단위 WAV 파일○ WAV 파일 기준: 수집 단계와 동일 ○ 1문장 단위 WAV 파일, 문장 앞뒤로 묵음 0.25초씩 추가
○ WAV 파일 기준: 수집 단계와 동일● 어노테이션 포맷
어노테이션 포맷 No. 속성 명 항목 설명 타입 필수 작성예시 1 sentences[].id 문장 식별자 string Y M-A3-C-001-0001 2 sentences[].origin_text 문장 원문 string Y 기다리라고 하다니, 이건 기다리는 게 아니란 말인가! 3 sentences[].voice_piece 음성파일 정보 객체 N 03월 01일 sentences[].voice_piece.filename 음성파일 이름 string Y M-A3-C-001-0001.wav 03월 02일 sentences[].voice_piece.tr 철자 전사 string Y 기다리라고 하다니, 이건 기다리는 게 아니란 말인가! 03월 03일 sentences[].voice_piece.ptr 발음 전사 string Y 기다리라고 하다니 / 이건 기다리는 게 아니란 말인가! 03월 04일 sentences[].voice_piece.duration 음성 구간길이 number Y 3.07999992 문장의 시작과 끝 03월 05일 sentences[].voice_piece.file_duration 음성파일 구간길이 number Y 3.57999992 sentences[].voice_piece.duration 앞뒤로 묵음 추가된 음원의 길이 4 sentences[].style 스타일 정보 객체 Y 04월 01일 sentences[].style.style 스타일 string Y 독백체 04월 02일 sentences[].style.emotion 감정 string Y 분노 04월 03일 sentences[].style.intensity 감정의 강도 number Y 2 04월 04일 sentences[].style.sub_style 스타일 추가 정보 string N (중계, 대화, 친절, 애니체에서 사용) 5 sentences[].votes 투표 정보 객체 배열 Y 05월 01일 sentences[].votes[].liker_scale 투표 결과 number Y 5 1: 매우 부적합 2: 부적합 3: 보통 4: 적합 5:매우 적합 05월 02일 sentences[].votes[].voter 투표자 객체 Y 05월 03일 sentences[].votes[].gender 투표자 성별 string Y FEMALE 05월 04일 sentences[].votes[].age 투표자 연령대 number Y 40 ● 데이터 구성

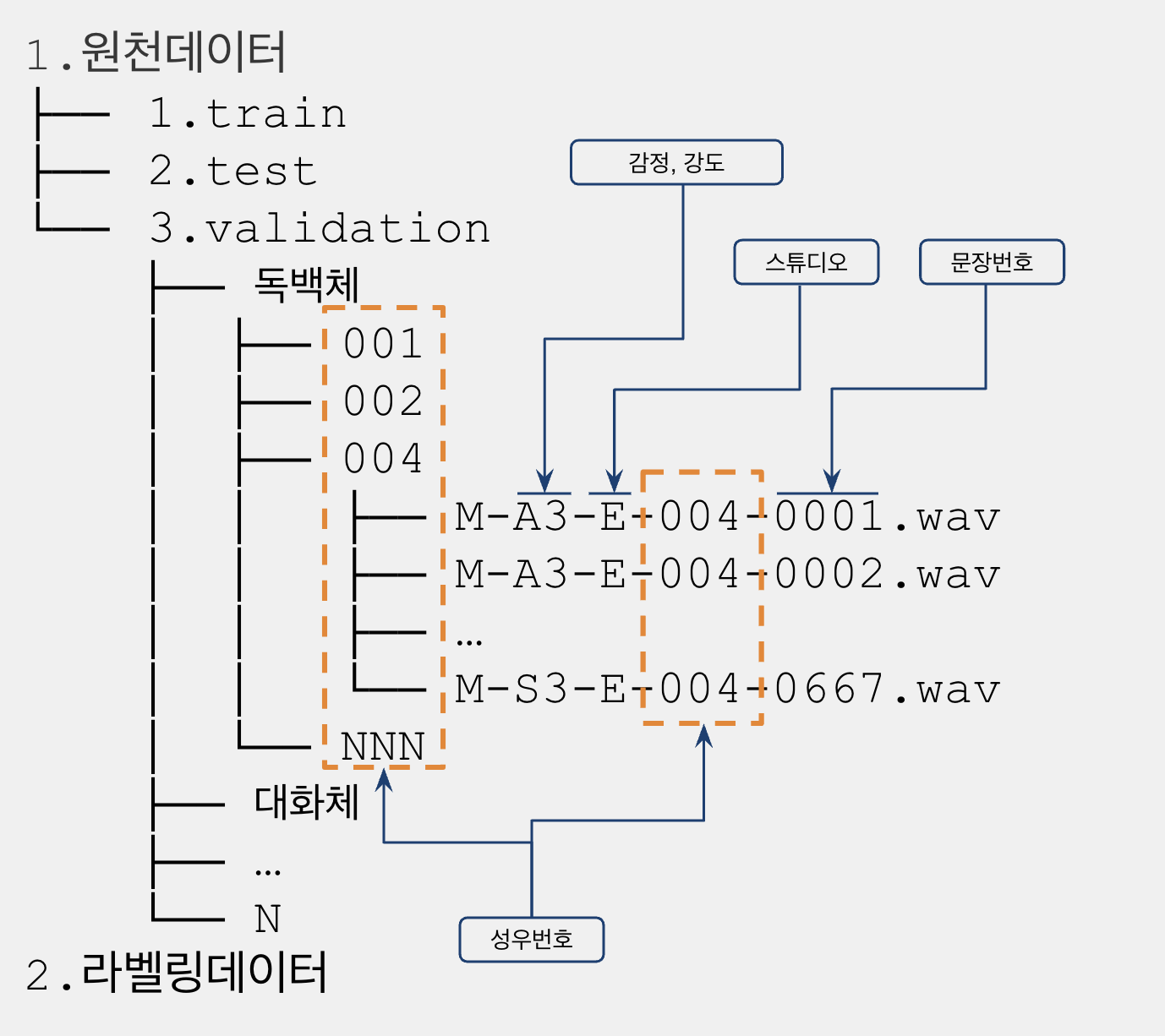
어노테이션 포맷 No Field Name Length Meaning a style 3 독백체(M), 대화체(D), 구연체(F), 애니체(A), 친절체(K), 중계체(S), 낭독체(N) b reciter 3 001 ~ 159 num file name 7 K-A3-F-003-0001.wav -
데이터셋 구축 담당자
수행기관(주관) : 커뮤니케이션북스(주)
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 엄진섭 02-3700-1250 [email protected] 사업총괄관리 -일정관리, 사업관리 -저작권 확보, 텍스트 선정 -음원 획득 -낭독자 섭외, 녹음, 음원 제작 -홍보 이벤트 -데이터경진대회 진행 수행기관(참여)
수행기관(참여) 기관명 담당업무 (주)나라지식정보 -가공, 검사
-크라우드 워커 관리
-품질관리(주)셀바스에이아이 -녹음대본 최종 선정
: 원천데이터로부터 스타일 및 감정별 최종 녹음 대본 선정
-음성합성용 데이터 구축 가이드
: 음성합성 학습을 위한 데이터 형식 가이드
-인공지능 모델링
: 구축된 데이터를 활용한 인공지능 모델 학습 및 검증(주)바이칼에이아이 -정제단계 (baikal VOIX 개발 및 공급)
-스타일 대본을 참고하여 원시 음성을 문장 및 파트 단위로 분리
-가공단계 도구제공 (AI달고나)
-가공단계 도구에서 사용할 수 있는 데이터 업로드
-인공지능 모델링을 위한 데이터 구축데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 엄진섭 02-3700-1250 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.