자연어 기반 질의(NL2SQL) 검색 생성 데이터
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2024-02-29 데이터 수정 1.1 2023-12-27 데이터 최종 개방 1.0 2023-04-30 데이터 개방(Beta Verison) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-02-29 샘플데이터 수정 2023-12-27 산출물 전체 공개 2023-05-03 데이터 개요/세부데이터/데이터통계/활용AI모델 및 코드 내용 수정 소개
데이터베이스에 대해 데이터를 검색하는 자연어 질문과 그와 의미가 동일한 SQL 질의의 쌍으로 구성된 데이터셋으로, 공공기관 데이터 플랫폼에서 수집한 데이터베이스를 활용하여 다양한 분야의 자연어 질문을 SQL 질의로 변환할 수 있는 NL2SQL 모델 개발을 위한 데이터셋을 제공
구축목적
데이터베이스에 대한 자연어 질문을 SQL 질의로 변환하는 NL2SQL 모델 개발에 활용
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt (SQLite, SQL, JSON) 데이터 출처 자체 수집 (서울시와 기타 공공기관이 서울시 열린데이터광장, 공공데이터포털를 통해 제공하는 각종 행정분야의 정형 텍스트 데이터 및 테이블 데이터) 라벨링 유형 질의응답 (자연어) 라벨링 형식 JSON 데이터 활용 서비스 시맨틱 파싱(Semantic parsing) 데이터 구축년도/
데이터 구축량2022년/라벨링 데이터 111,152건 -
1. 데이터 구축 규모
<분할 데이터셋의 데이터 구축 규모>
데이터 구축 규모 구분 분할 비율 원천데이터 (단위: 건) 라벨링 데이터 (단위: 건) 데이터베이스 파일 (SQLite) 데이터베이스 생성 질의(SQL) 데이터베이스 어노테이션 Training 80.00% 5,121 5,121 5,121 88,946 Validation 9.90% 640 640 640 11,026 Test 10.10% 640 640 640 11,180 계 100% 6,401 6,401 6,401 111,152 ■ 전체 컬럼이 50개 이하, 레코드 수가 50개 이상인 데이터베이스(SQLite, SQL) 6,401건과 각 데이터베이스에 대한 데이터베이스 어노테이션(JSON) 구축
■ 각 데이터베이스에 대해 자연어 발화-SQL질의 쌍을 제작하여 총 111,152건의 라벨링 데이터(JSON) 구축2. 데이터 분포
2-1 데이터 카테고리 분포데이터 카테고리 분포 카테고리 개수(건) 구성률 산업/경제 24,648 22.18% 보건 23,694 21.32% 환경 21,441 19.29% 문화/관광 14,682 13.21% 일반행정 11,091 9.98% 교육 6,530 5.87% 교통 5,185 4.66% 복지 3,881 3.49% 합계 111,152 100% 2-2 자연어 발화 질의 유형 분포
자연어 발화 질의 유형 분포 자연어 발화 질의 유형 의문사 개수(건) 구성률 수량 얼마 23,889 21.49% 사물/속성 무엇 22,402 20.15% 인물/조직 누구 21,926 19.73% 장소 어디 21,610 19.44% 일시 언제 21,325 19.19% 합계 111,152 100% 2-3 SQL 난이도 분포
SQL 난이도 분포 SQL 난이도 개수(건) 구성률 하(easy) 25,660 23.09% 중(medium) 50,435 45.37% 상(hard) 28,200 25.37% 최상(extra hard) 6,857 6.17% 합계 111,152 100% 2-4 자연어 발화의 길이 분포
자연어 발화의 길이 분포 자연어 발화 길이 개수(건) 구성률 20글자 미만 16,487 14.83% 20~49글자 91,797 82.59% 50~80글자 2,868 2.58% 합계 111,152 100% 2-5 SQL 질의의 길이 분포
SQL 질의의 길이 분포 SQL 질의 길이 구성률 개수(건) 20~39글자 0.13% 148 40~59글자 5.18% 5,756 60~79글자 34.30% 38,122 80~99글자 27.62% 30,705 100글자 이상 32.77% 36,421 합계 100% 111,152 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 모델 학습
1-1 학습 모델
■ 학습모델의 적합성, 활용성, 실현가능성을 고려하여 RYANSQL 모델, BRIDGE모델 2개 모델에 대하여 모델 학습 실행학습 모델 구 분 설 명 RYANSQL BERT를 이용한 Schema Encoding 독자적 기술인 SPC(Statement Position Code) 기법을 이용하여 모델 학습 SQL 예측에 필요한 요소들을 예측하는 Slot Filling 방식으로 SQL 생성 BRIDGE 자연어 쿼리로부터 DB content를 탐색하고 이를 학습의 자질로 사용 BERT + Bi-LSTM을 이용하여 primary key, foreign key, field type을 반영하여 Schema Encoding self-attention 모델을 강화한 Pointer-Generator Network를 이용하여 recursive 방식으로 SQL 생성 1-2 모델 학슴
■ 학습용, 검증용, 평가용 데이터셋을 적용하며, 대이터셋 비율은 각각 80%, 10%, 10%로 구성
■ 학습모델의 SQL 질의 생성 결과를 정답(ground truth) SQL 질의를 비교하여 Exact Set Match without value (EM) 값에 따라 학습모델 성능 평가2. 서비스 활용 시나리오
■ 구축한 자연어 기반 질의 생성 모델(RYANSQL, BRIDGE)을 활용하여, 데이터베이스를 대상으로 자연어 검색 서비스를 구축할 수 있음
■ 기존의 DBMS를 통한 데이터 탐색과 달리, SQL 질의가 아닌 자연어 질의를 통해 필요한 정보획득이 가능함
3. 기타 정보
3-1 포괄성
■ 서울시 열린데이터광장 및 공공데이터포털에서 제공하는 공공행정분야 데이터 중, 편향성 방지 및 다양성 확보를 고려하여 적절한 8개 카테고리에 대해 데이터를 수집함3-2 독립성
■ 원시데이터의 제공기관이 정한 저작권에 의존함. 데이터베이스의 출처를 표시하는 조건을 만족하면 자유롭게 이용할 수 있음3-3 유의사항
■ 데이터베이스의 출처를 표시하는 조건을 만족하면 자유롭게 이용할 수 있음
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 자연어 발화의 SQL 질의 변환 성능(RYANSQL모델) Text Generation RYANSQL Accuracy 58 % 82.2 % 2 자연어 발화의 SQL 질의 변환 성능(BRIDGE모델) Text Generation BRIDGE Accuracy 60 % 80.8 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 원천 데이터 포맷 (데이터베이스)
원천 데이터 포맷 원천데이터 테이블 정보 데이터베이스ID seouldata_financial_0001 테이블ID entrprs_info 한국어 테이블ID 영리 사업체 정보 한국어 컬럼명 “데이터 일련번호”, “행정동 코드”, “기업명”, “업종명”, “도로명”, “창립년월” 데이터타입 “number”, “number”, “text”, “text”, “text”, “number” 컬럼명 "data_sno", "adstrd_code_se", "entrprs_nm", "induty_nm", "road_nm", "fndtn_ym" 제공기관 서울특별시 데이터베이스
데이터베이스 data_sno adstrd_code_se entrprs_nm induty_nm road_nm fndtn_ym 546719 1123053 (주)제일FNE 유통 테헤란로 200011 108959 1117071 ㈜케이티서비스북부중랑지점 드론응용소프트웨어개발 디지털로 201301 148693 1104054 덕진티엠에스주식회사 논술 영신로34길 201502 210574 1122054 어바웃 모델 실내인테리어공사 디지털로33길 200801 데이터베이스 자연어 발화-SQL질의 어노테이션 자연어 발화 2000년 이후에 창업한 기업의 이름과 창립년월을 이름의 가나다 순으로 보여줘 SQL 난이도 중 (“medium”) 자연어 발화 유형 사물/속성 SQL 질의 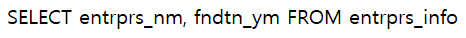

데이터베이스ID seouldata_financial_0001 2. 데이터 구성 및 어노테이션 포맷
2-1 데이터베이스 구성 및 어노테이션 포맷데이터베이스 구성 및 어노테이션 포맷 No. 속성명(Key) 항목 설명(Description) Type 필수 여부 작성 예시 1 Dataset 메타데이터 객체 obj Y 1.1 Dataset.identifier 데이터셋 식별자 str Y TEXT_NL2SQL_01 1.2 Dataset.name 데이터셋 이름 str Y 자연어 기반 질의 검색 생성 데이터 1.3 Dataset.src_path 데이터셋 폴더 위치 str Y /dataSet/text/ 1.4 Dataset.label_path 데이터셋 레이블 폴더 위치 str Y /dataSet/text/ 1.5 Dataset.category 데이터셋 카테고리 int Y 9 (9: 시맨틱 파싱) 1.6 Dataset.type 데이터셋 타입 int Y 0 (0: 텍스트) 2 data 데이터베이스 어노테이션 객체의 리스트 array Y 2.1 data[].db_id 데이터베이스 식별자 str Y "seouldata_financial_0001" 2.2 data[].source 데이터베이스의 제공기관 str Y “서울특별시” 2.3 data[].table_names_original 테이블 이름의 리스트 array Y [ "use3upjongitem", "areacode", "upjongitemcode", "agegrcode" ] 2.4 data[].table_names 테이블의 한국어 이름의 리스트 array Y [ "3개소업종의 품목별 구매데이터", "지역구분_코드", "품목구분_코드", "연령대구분_코드" ] 2.5 data[].column_names_original 테이블의 인덱스와 컬럼의 이름 쌍의 리스트 array Y [ [ -1, "*"], [ 0, "re_area"], [ 0, "use_area"], [ 0, "gender"], [ 0, "age"], [ 0, "date"], [ 0, "upjong"], [ 0, "item"], [ 0, "use_custm_cnt"], [ 0, "use_cnt"], [ 0, "use_amt"]] 2.6 data[].column_names 테이블의 인덱스와 컬럼의 컬럼의 한국어 이름 쌍의리스트 array Y [ [ -1, "*" ], [ 0, "주거지역" ], [ 0, "소비지역" ], [ 0, "성별" ], [ 0, "연령" ], [ 0, "이용년월일" ], [ 0, "업종" ], [ 0, "품목 및 가맹점" ], [ 0, "이용 고객수" ], [ 0, "이용 건수" ], [ 0, "이용 금액" ], ... ] 2.7 data[].column_types 컬럼의 데이터 타입으로 구성된 리스트 array Y [ "text", "text", "number", "number", "number", "text", "text", "number", "number", "number", ...] 2.9 data[].foriegn_keys 자식테이블과 부모테이블의 외래키의 컬럼의 column_names_original의 인덱스 쌍 array N [[0,1], [1, 3], ...] 2.10 data[].primary_keys 기본키에 해당하는 컬럼의 column_names_original의 인덱스 쌍 array N [0,9] 2-2. 라벨링데이터 구성 및 어노테이션 포맷
라벨링데이터 구성 및 어노테이션 포맷 No. 속성명 항목 설명 Type 필수 여부 작성 예시 1 Dataset 메타데이터 객체 obj Y 1.1 Dataset.identifier 데이터셋 식별자 str Y TEXT_NL2SQL_01 1.2 Dataset.name 데이터셋 이름 str Y 자연어 기반 질의 검색 생성 데이터 1.3 Dataset.src_path 데이터셋 폴더 위치 str Y /dataSet/text/ 1.4 Dataset.label_path 데이터셋 레이블 폴더 위치 str Y /dataSet/text/ 1.5 Dataset.category 데이터셋 카테고리 int Y 9 (9: 시맨틱 파싱) 1.6 Dataset.type 데이터셋 타입 int Y 0 (0: 텍스트) 2 data 질의 라벨링 객체의 리스트 str Y 2.1 data[].utterance_id 질문 식별자 str Y “Wht_00001” 2.2 data[].db_id 데이터베이스 식별자 str Y "seouldata_financial_0001" 2.3 data[].utterance_type 자연어 발화 유형 분류 str Y “BR04”: 사물/속성 “BR02”: 일시 “BR03“: 장소 ”BR08“: 수량 ”BR01“: 인물/조직 2.4 data[].hardness SQL 질의의 난이도 str Y 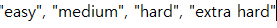
2.5 data[].utterance 자연어 발화 str Y "이용 금액이 100000원을 초과하는 모든 소비 내역을 보여줘" 2.6 data[].query SQL 질의 str Y 
2.7 data[].cols 토큰과 컬럼 매치 정보 객체의 리스트 array N 2.7.1 data[].cols[].token 토큰 텍스트 str N "이용 금액" 2.7.2 data[].cols[].column_index 토큰에 대응하는 컬럼의 인덱스 int N 9 2.7.3 data[].cols[].start 자연어 발화에서 토큰의 시작 위치 int N 0 2.8 data[].values 조건값 정보 객체의 리스트 array N 2.8.1 data[].values[].token 조건값 텍스트 str N "100000" 2.8.2 data[].values[].column_index 토큰에 대응하는 컬럼의 인덱스 int N 9 2.8.3 data[].values[].start 자연어 발화에서 토큰의 시작 위치 int N 7 3. 라벨링데이터 실제 예시

-
데이터셋 구축 담당자
수행기관(주관) : ㈜포티투마루
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정연재 02-6952-9201 [email protected] 인공지능 모델, 인공지능 응용서비스 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜유클리드소프트 AI 허브 개방 데이터, 저작도구 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정연재 02-6952-9201 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.