교육용 한국인의 중국어·일본어 음성 데이터
- 분야교육
- 유형 오디오
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2024-06-25 원천데이터, 라벨링데이터 수정 1.1 2023-11-03 데이터 최종 개방 1.0 2023-06-28 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-13 데이터설명서, 담당자 정보 수정 2023-12-08 산출물 전체 공개 2023-12-01 구축업체정보 수정 2023-11-24 구축업체정보 수정 소개
인공지능 외국어 발음 교육 및 평가와 말하기 교육 및 평가를 위한 한국인의 외국어 발화 음성 데이터 및 학습자별 수준 분류·평가, 언어학적 분석이 포함된 메타데이터의 구축
구축목적
- 외국어 음성 인식, 통·번역, 교육용 AI 모델 등 연구·개발에 활용 - 외국어 교육을 위한 AI 기반 발음/말하기 평가 시스템 개발 등 산업분야 활용
-
메타데이터 구조표 데이터 영역 교육 데이터 유형 오디오 데이터 형식 WAV 데이터 출처 신규 제작 라벨링 유형 전사, 태깅, 말뭉치(음성) 라벨링 형식 JSON 데이터 활용 서비스 음성 인식 서비스, 교육용 학습 서비스 등 (예시) 데이터 구축년도/
데이터 구축량2022년/1,019시간 -
데이터 통계
데이터 구축 규모
데이터 통계 데이터 구축 규모 데이터 종류 규모 음성 및 전사데이터 1,019시간 데이터 분포
○ 말하기 평가 문항 주제 분포
*주제 분포는 말하기 평가 문항에서만 확인 가능함데이터 분포○ 말하기 평가 문항 주제 분포 문항 주제 비율 인간관계 20% 음식 15% 미용/뷰티/패션 10% 엔터테인먼트/게임 10% 의료/의학 5% 과학기술 5% 산업경제 5% 스포츠/건강 5% 자연/동식물 10% 여행/교통 15% 총 100% 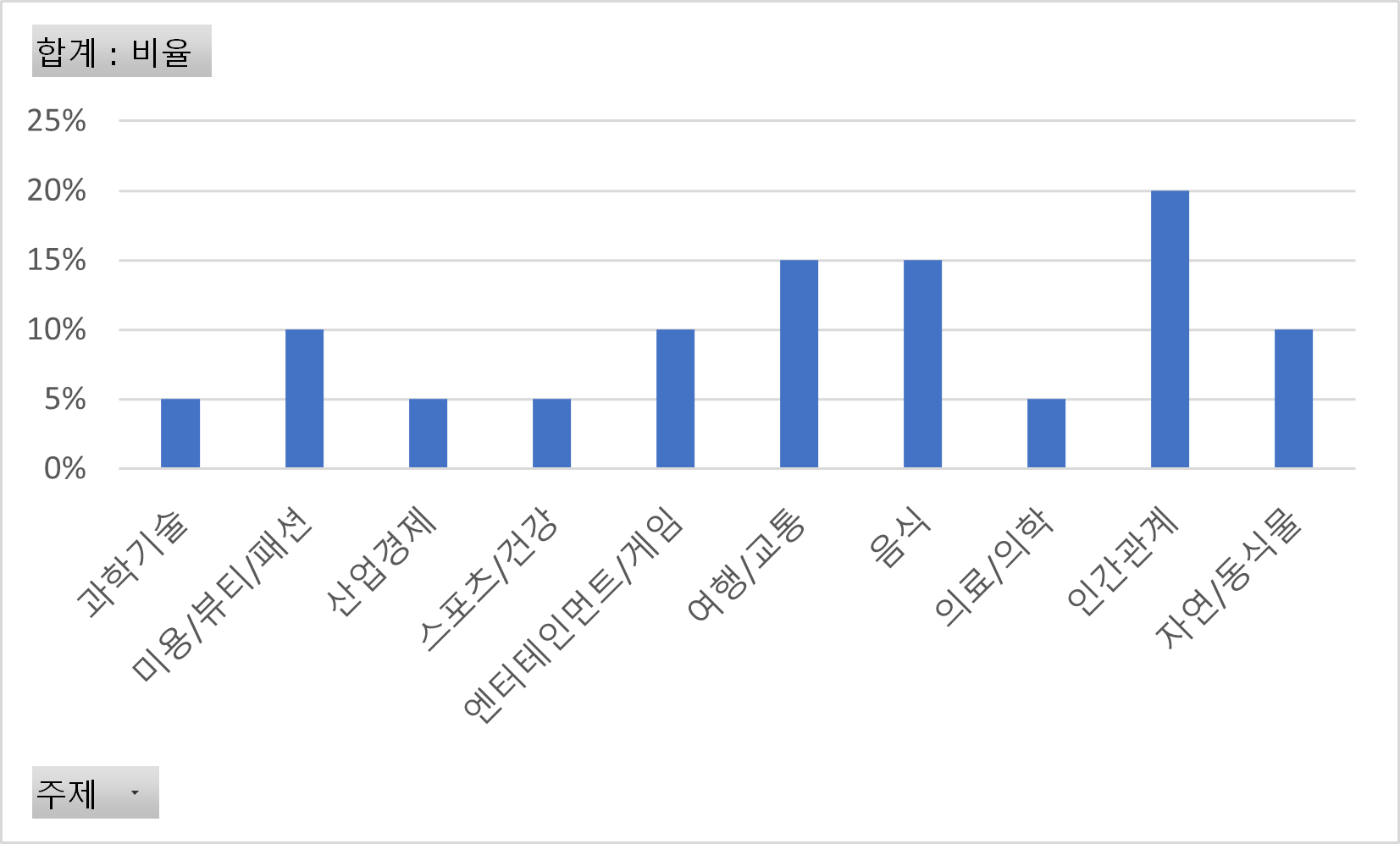
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드모델 학습
1. 음성인식 모델
○ 학습모델 연구- 음성인식 모델은 음향모델(AM) 과 언어모델( LM) 을 독립적으로 학습하여 인식에 활용하는 hybrid 모델과 하나의 딥러닝 모델로 인식을 수행하는 E2E 모델이 있음
- hybrid 모델은 개발자가 언어에 인식대상 언어에 대해 일정 정도의 지식이 필요하나 E2E 모델은 음성데이터와 그 음성에 대한 스크립트 정보만 있으면 모델 학습이 가능함
- 위와 같은 이유로 짧은 시간에 여러 언어에 대한 모델을 학습해야 하는 경우 E2E 방식이 유리함- E2E 모델은 크게 CTC( Connectionist temporal Classificaiton), AED( attention-based encoder decoder ), RNN-Transcuder 방식이 있음
- 이 세가지 방식중 인식 성능이 높고 실시간 streaming 인식이 쉬운 구조인 RNN-Transducer 방식을 학습 모델로 선정하였음
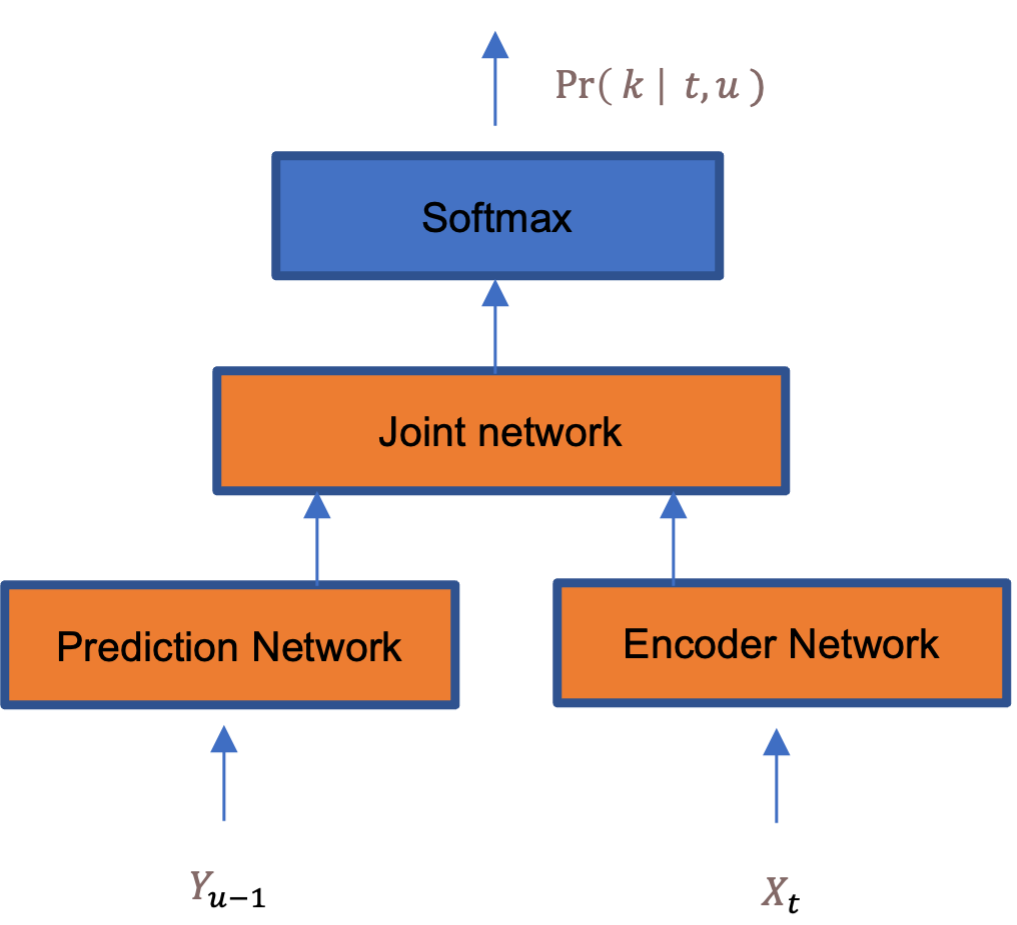
○ 모델 구조
- RNN-Transcuder 모델은 Encoder Network, Prediction Network, Joint Network로 이루어짐
* Encoder network : 음성데이터를 encoding 하는 부분으로 conformer 모델을 사용하여 학습
** conformer 모델을 하나의 층으로 해서 12개층을 쌓아올린 구조
* Prediction network : 현재까지 인식된 결과를 encoding 하는 부분으로 LSTM 모델을 사용하여 학습
** LSTM Layer 1개층
* Joint network : encoder network의 출력값과prediction network의 출력값을 합치는 역할을 하면 feed forward network 을 사용하여 학습
** Feed Forward Layer 2개층
○ 모델 학습
- 음성인식은 음성정보를 text 정보로 변환하는 것으로 매 frame 마다 N개의 BPE중 가장 가능성이 높은 BPE를 찾는 문제임
- espnet 프레임워크를 이용하여 RNN-T Conformer 모델을 학습- 입력 데이터
* 16khz sampled wav 에서 추출한 특징벡터
* 83차 벡터 : 80차 FilterBank + 3차 Pitch
* 40ms 간격으로 입력- 출력 데이터* STT 모델링 Unit으로 음성에 대한 Script를 N개의 BPE(Byte Pair Encoding)를 사용하여 표현하도록 변형
* 매 frame 마다 softmax 확률값이 가장 높은 BPE가 해당 프레임의 결과로 출력
2. 발음평가 모델
○ 학습모델 연구- 발음평가 모델은 입력 음성에 대한 발음평가 점수를 자동으로 추정하기 위한 모델로 전문평가자가 평가한 점수와 모델이 추정한 점수의 correlation이 최대가 되도록 모델을 학습한다.
* 음성에서 발음평가 모델링에 사용되는 특징을 추출하는 방법은 음성인식의 결과를 이용하는 방법, GOP feature, End-To-End 딥러닝 모델, SSL( Self Supervised Learning ) 방법 등이 있음
* 이중 개발자가 언어에 대한 전문 지식이 필요 없고 여러 언어에 동일한 방식으로 사용할 수 있는 SSL 방법의 일종인 wav2vec2.0을 통해 음성을 일정한 크기의 벡터로 변환하는 방법을 사용
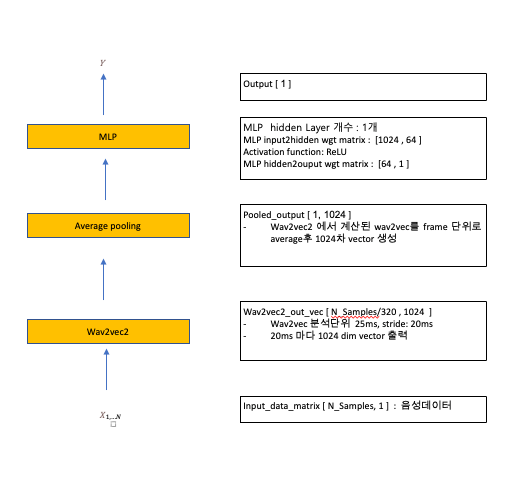
○ 모델 구조
- 크게 pre-trained wav2vec2.0, Average pooling, MLP 세 부분으로 나눔
- wav2vec2.0
* 음성데이터를 매 20ms 간격으로 1024차 벡터로 변환
- Average Pooling
* wav2vec2.0에서 출력된 1024차 벡터를 frame 단위로 averaging 하여 1024차 벡터로 변환
- MLP
* input layer, hidden layer, output layer를 갖는 feed forward network- 본 과제에서는 hidden layer 개수 1개
○ 모델 학습
- 발음평가 모델은 target score를 추정하는 회귀 모델링 task
- wav2vec2.0으로 변환하고 averaging 한 feature를 입력으로 하여 target score를 추정하는 MLP를 학습
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 음성인식 모델(중국어) Speech Recognition RNN-Transducer CER 14.5 % 6 % 2 음성인식 모델(일본어) Speech Recognition RNN-Transducer CER 14 % 4.2 % 3 발음 평가 모델(중국어) Audio Classification wav2vec2.0 + MLP Correlation(Pearson) 0.5 단위없음 0.73 단위없음 4 발음 평가 모델(일본어) Audio Classification wav2vec2.0 + MLP Correlation(Pearson) 0.5 단위없음 0.62 단위없음
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷
대표도면
JSON 형식
JSON 형식 <발음> <말하기> { "recrdDt": "2022-09-21",
"recrdTime": 4.9146667,
"fileNm": "ED-EV-F-20-ko-220921-100002_524_1_72-zh",
"recrdPlace": "hm",
"recrdDevice": "PC",
"peakLevel": 0.54039127,
"rmsLevel": null,
"recorder": {
"recorderId": 102722,
"motherLang": "ko",
"gender": "F",
"age": 20,
"ability": "MID"
},
"scriptInfo": {
"scriptName": "zh_prn_set13(m)",
"scriptId": "100002_524_1_72",
"language": "zh",
"evaluationArea": "PRN"
},
"itemScript": {
"testType": "PRN01",
"rating": {
"articulationScore": 4.0,
"prosodyScore": 4.0,
"ratingSum": 8.0
},
"contents": [
{
"sentence": "今天学校的篮球比赛非常精彩。",
"sttText": "今天学校的篮球比赛非常精彩",
"transAnsw": " j in1 q ian1 x ue3 x iao4 d e5 l an2 q iu2 b i3 s ai4 b ei1 ch ang3 j ing1 c ai2",
"phonemeText": " j in1 t ian1 x ue2 x iao4 d e5 l an2 q iu2 b i3 s ai4 f ei1 ch ang2 j ing1 c ai3",
"tagging": " C C S C C S C C C C C C C C C C C C S C C S C C C S C "
}
]
}
}{ "recrdDt": "2022-09-08",
"recrdTime": 2.696,
"fileNm": "ED-EV-F-19-ko-220908-100001_164_1_111-jp",
"recrdPlace": "hm",
"recrdDevice": "PC",
"peakLevel": 0.16165654,
"rmsLevel": 0.019209413,
"recorder": {
"recorderId": 101646,
"motherLang": "ko",
"gender": "F",
"age": 19,
"ability": "LOW"
},
"scriptInfo": {
"scriptName": "ja_prn_set01(l)",
"scriptId": "100001_164_1_111",
"language": "jp",
"evaluationArea": "PRN"
},
"itemScript": {
"testType": "PRN01",
"rating": {
"articulationScore": 3.0,
"prosodyScore": 3.0,
"ratingSum": 6.0
},
"contents": [
{
"sentence": "体育時間(たいいくじかん)に雨(あめ)が降(ふ)った。",
"sttText": "妙子痴漢ね雨が降った",
"transAnsw": "た い い く じ か ん *** に あ め が ふ っ た",
"phonemeText": "た え い こ ち か ん ね ん あ め が ほ っ た",
"tagging": "C S C S S C C I S C C C S C C"
}
]
},
"pronFeat": {
"ros": 3.41,
"ar": 3.41,
"ptr": 1.0,
"wpsec": 0.28,
"wpsecutt": 0.28,
"silpsec": 0.0,
"silmean": 0,
"silmeandev": 0,
"longpfreq": 0,
"longpmn": 0,
"longpwd": 0.0,
"longpmeandev": 0,
"silstddev": 0,
"longpstdev": 0
}
}데이터 구성
데이터 구성 데이터 유형 구분 설명 원천데이터 파일 포맷 WAV 샘플링 레이트 16Khz sampling rate 파일 명명규칙 맥락범주 대분류-맥락범주 중분류_성별-연령-모국어-녹음일자-일련번호-언어 라벨링데이터 발음 평가 발음의 정확성 (articulationScore) : 1-5점
운율의 유창성 (prosodyScore) : 1-5점문장 단위 오류 유형: C (정조음), D (음소 삭제), I (음소 삽입), S(음소 교체), O (기타) 말하기 평가 총체적 평가 : 1-9점 기타 메타정보 녹음자 정보, 스크립트 정보 등 어노테이션 포맷
○ 발음 데이터
어노테이션 포맷○ 발음 데이터 No 항목 타입 필수여부 한글명 영문명 1 녹음 일자 recrdDt string Y 2 음성 녹음 길이 recrdTime number Y 3 파일명 fileNm string Y 4 녹음장소 recrdPlace string Y 5 녹음기기 recrdDevice string Y 6 파형의 가장 높은값 peakLevel number N 7 전체 레벨의 평균값 rmsLevel number N 8 녹음자 정보 recorder object Y 8-1 녹음 사용자 식별 아이디 recorderId number Y 8-2 모국어 motherLang string Y 8-3 성별 gender string Y 8-4 연령 age number Y 8-5 언어 실력 ability string Y 9 스크립트 정보 scriptInfo object Y 9-1 스크립트 파일명 scriptName string Y 9-2 스크립트 아이디 scriptId string Y 9-3 스크립트 언어 language string Y 9-4 평가유형 evaluationArea string Y 10 평가문항의 평가결과 itemScript object Y 10-1 문제 testType string Y 10-2 DA 평가 rating object Y 10-2-1 발음의 정확성 articulationScore number Y 10-2-2 운율의 유창성 prosodyScore number Y 10-2-3 합산 점수 ratingSum number Y 10-3 문장과 문단(5~6개의 문장)으로 구성된 문항의 스크립트 contents array Y 10-3-1 스크립트 문장 sentence string Y 10-3-2 STT 결과물 sttText string N 10-3-3 문장 단위 표준 발음 transAnsw string N 10-3-4 문장 단위 음소 인식 결과 phonemeText string N 10-3-5 문장 단위 오류 유형 라벨링 tagging string Y 11 feature 태깅 pronFeat object N (영어와 일본어에 대하여 정보제공) 11-1 feature 항목 ros number N 11-2 feature 항목 ar number N 11-3 feature 항목 ptr number N 11-4 feature 항목 wpsec number N 11-5 feature 항목 wpsecutt number N 11-6 feature 항목 silpsec number N 11-7 feature 항목 silmean number N 11-8 feature 항목 silmeandev number N 11-9 feature 항목 longpfreq number N 11-10 feature 항목 longpmn number N 11-11 feature 항목 longpwd number N 11-12 feature 항목 longpmeandev number N 11-13 feature 항목 silstddev number N 11-14 feature 항목 longpstdev number N
○ 말하기 데이터어노테이션 포맷○ 말하기 데이터 No 항목 타입 필수여부 한글명 영문명 1 녹음 일자 recrdDt string Y 2 음성 녹음 길이 recrdTime number Y 3 파일명 fileNm string Y 4 녹음장소 recrdPlace string Y 5 녹음기기 recrdDevice string Y 6 파형의 가장 높은값 peakLevel number N 7 전체 레벨의 평균값 rmsLevel number N 8 녹음자 정보 recorder object Y 8-1 녹음 사용자 식별 아이디 recorderId number Y 8-2 모국어 motherLang string Y 8-3 성별 gender string Y 8-4 연령 age number Y 8-5 언어 실력 ability string Y 9 스크립트 정보 scriptInfo object Y 9-1 스크립트 파일명 scriptName string Y 9-2 스크립트 아이디 scriptId string Y 9-3 스크립트 언어 language string Y 9-4 주제 topic string Y 9-5 평가유형 evaluationArea string Y 10 평가문항의 평가결과 itemScript object Y 10-1 문제 testType string Y 10-2 DA 평가 rating number Y 10-3 지시문 question string Y 10-4 문항 passage string N 10-5 이미지나 음원 파일명 referenceFileName string N 10-6 발화자의 자유발화 내용 contents array Y 10-6-1 자유발화 내용 전사 sentence string Y 10-6-2 화행 speechAct string N 11 feature 태깅 (영어와 일본어에 대하여 정보 제공) pronFeat object N 11-1 feature 항목 ros number N 11-2 feature 항목 ar number N 11-3 feature 항목 ptr number N 11-4 feature 항목 wpsec number N 11-5 feature 항목 wpsecutt number N 11-6 feature 항목 silpsec number N 11-7 feature 항목 silmean number N 11-8 feature 항목 silmeandev number N 11-9 feature 항목 longpfreq number N 11-10 feature 항목 longpmn number N 11-11 feature 항목 longpwd number N 11-12 feature 항목 longpmeandev number N 11-13 feature 항목 silstddev number N 11-14 feature 항목 longpstdev number N 실제 예시
실제 예시 <발음> <말하기> { "recrdDt": "2022-09-21",
"recrdTime": 4.9146667,
"fileNm": "ED-EV-F-20-ko-220921-100002_524_1_72-zh",
"recrdPlace": "hm",
"recrdDevice": "PC",
"peakLevel": 0.54039127,
"rmsLevel": null,
"recorder": {
"recorderId": 102722,
"motherLang": "ko",
"gender": "F",
"age": 20,
"ability": "MID"
},
"scriptInfo": {
"scriptName": "zh_prn_set13(m)",
"scriptId": "100002_524_1_72",
"language": "zh",
"evaluationArea": "PRN"
},
"itemScript": {
"testType": "PRN01",
"rating": {
"articulationScore": 4.0,
"prosodyScore": 4.0,
"ratingSum": 8.0
},
"contents": [
{
"sentence": "今天学校的篮球比赛非常精彩。",
"sttText": "今天学校的篮球比赛非常精彩",
"transAnsw": " j in1 q ian1 x ue3 x iao4 d e5 l an2 q iu2 b i3 s ai4 b ei1 ch ang3 j ing1 c ai2",
"phonemeText": " j in1 t ian1 x ue2 x iao4 d e5 l an2 q iu2 b i3 s ai4 f ei1 ch ang2 j ing1 c ai3",
"tagging": " C C S C C S C C C C C C C C C C C C S C C S C C C S C "
}
]
}
}{ "recrdDt": "2022-09-08",
"recrdTime": 2.696,
"fileNm": "ED-EV-F-19-ko-220908-100001_164_1_111-jp",
"recrdPlace": "hm",
"recrdDevice": "PC",
"peakLevel": 0.16165654,
"rmsLevel": 0.019209413,
"recorder": {
"recorderId": 101646,
"motherLang": "ko",
"gender": "F",
"age": 19,
"ability": "LOW"
},
"scriptInfo": {
"scriptName": "ja_prn_set01(l)",
"scriptId": "100001_164_1_111",
"language": "jp",
"evaluationArea": "PRN"
},
"itemScript": {
"testType": "PRN01",
"rating": {
"articulationScore": 3.0,
"prosodyScore": 3.0,
"ratingSum": 6.0
},
"contents": [
{
"sentence": "体育時間(たいいくじかん)に雨(あめ)が降(ふ)った。",
"sttText": "妙子痴漢ね雨が降った",
"transAnsw": "た い い く じ か ん *** に あ め が ふ っ た",
"phonemeText": "た え い こ ち か ん ね ん あ め が ほ っ た",
"tagging": "C S C S S C C I S C C C S C C"
}
]
},
"pronFeat": {
"ros": 3.41,
"ar": 3.41,
"ptr": 1.0,
"wpsec": 0.28,
"wpsecutt": 0.28,
"silpsec": 0.0,
"silmean": 0,
"silmeandev": 0,
"longpfreq": 0,
"longpmn": 0,
"longpwd": 0.0,
"longpmeandev": 0,
"silstddev": 0,
"longpstdev": 0
}
} -
데이터셋 구축 담당자
수행기관(주관) : 한국외국어대학교
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 한승희 02-2173-2493 [email protected] 데이터 설계 및 원천데이터 가공, 라벨링데이터 검수 수행기관(참여)
수행기관(참여) 기관명 담당업무 엠브레인퍼블릭 원시데이터 수집 및 정제 카카오엔터프라이즈 AI 학습 모델링 ㈜오피니언라이브 저작도구 개발 및 운영, 품질관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 한승희 02-2173-2493 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.