기계번역 품질 검증 데이터
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-08 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-13 데이터설명서, 담당자 정보 수정 2024-01-12 산출물 전체 공개 2023-12-01 구축업체정보 수정 2023-11-24 구축업체정보 수정 소개
- 한국어-영어 양방향에 대하여 기계번역 사후교정 및 어절, 문장, 문서 수준에서 기계번역 품질주석 데이터 구축
구축목적
- 자연어 이해 및 자연어 생성에 대한 연구 및 개발한 언어모델 평가 등에 활용 - 다양한 산업에서 민원·응대 등에 활용되는 챗봇, AI 비서와 같은 언어모델 평가 등에 활용
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 JSON 데이터 출처 신규 제작 라벨링 유형 분류, 교정 라벨링 형식 JSON 데이터 활용 서비스 기계번역 데이터 구축년도/
데이터 구축량2022년/620,002건 -
데이터 구축 규모
데이터 구축 규모 데이터 종류 규모 텍스트 데이터 620,002건 ○ 데이터셋별 분포
○ 데이터셋별 분포 데이터셋명 수량 052-1 MTPE 310,000 052-2 QE 310,002 총 620,002 ○ 주제별 분포
○ 주제별 분포 주제 비율 CA 40.22% ES 19.98% SH 20.01% ST 19.79% 총 100% 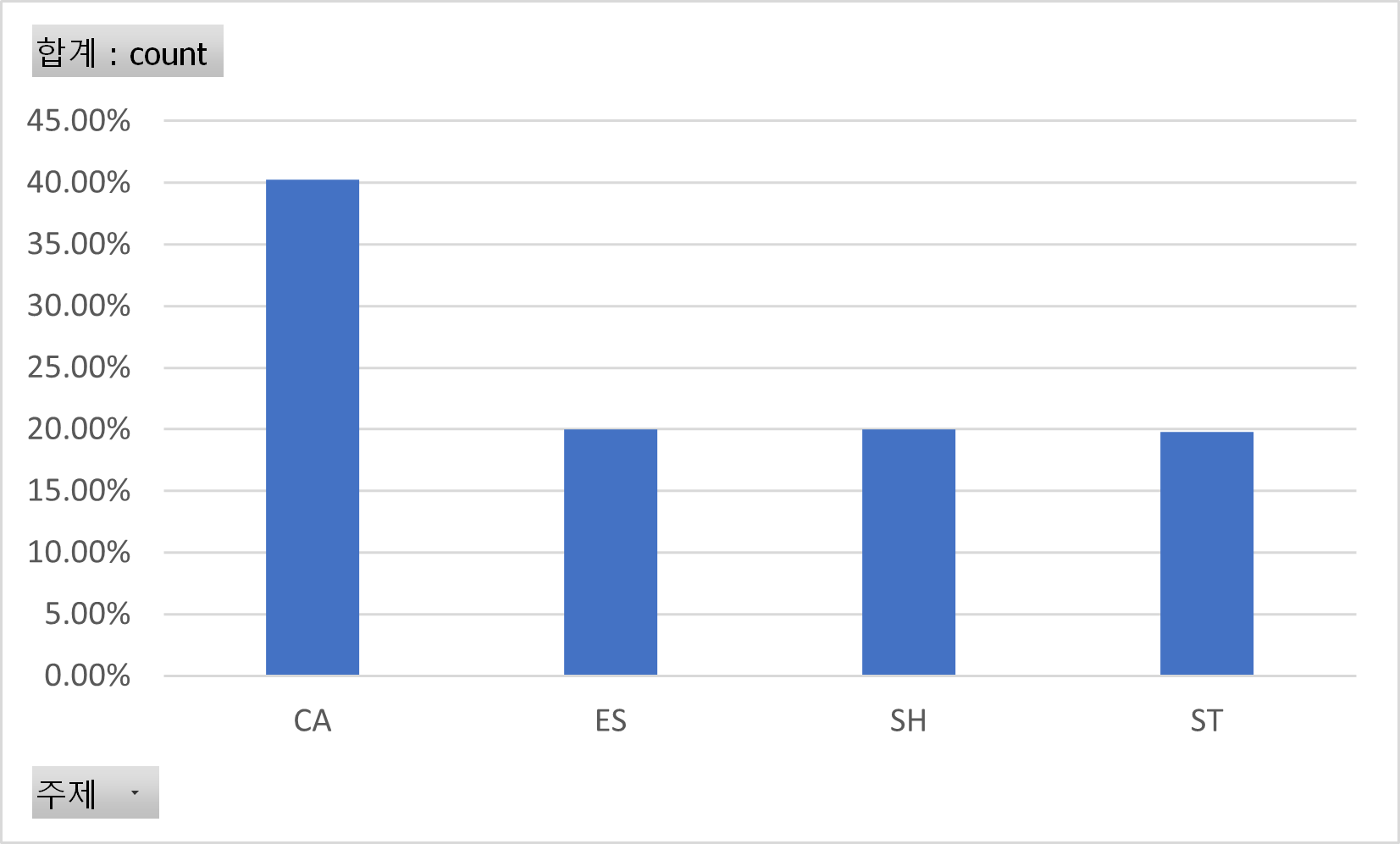
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드모델 학습
○ 기계번역 사후 교정 모델기계번역된 문장을 사람과 비슷한 번역으로 교정해주는 모델
예시)
입력: 조의 국내 첫 공연인 쇼팽 피아노 협주곡 1번과 2번을 연주할 예정이다.
출력: 조성진은 국내 첫 공연에서 쇼팽 피아노 협주곡 1번과 2번을 연주할 예정이다.○ 문서 수준의 기계번역 품질예측 모델한->영 그리고 영->한 방향에서 원문장과 기계번역된 문서의 특정문장이 주어졌을 때 MQM 점수를 예측하는 모델.예시)입력: Many choose to meet their friends for a beer at the outside seating area at night to enjoy the chill atmosphere.,많은 사람들은 밤에 야외 좌석 공간에서 시원한 분위기를 즐기기 위해 친구들을 만나 맥주를 마시곤 합니다.출력: 0.8074413520467247
○ 문장 수준의 기계번역 품질예측 모델한->영 그리고 영->한 방향에서 원문장과 기계번역된 문장이 주어졌을 때 SQM 점수를 예측하는 모델.예시)입력: 이따가 피시방에서 아이스크림 물고 롤?,Eat ice cream and rolls at the PC room later?출력: -0.827451103646026
○ 어절 수준의 기계번역 품질예측 모델한->영 그리고 영->한 방향에서 원문장과 기계번역된 문장이 주어졌을 때 기계번역된 문장의 어절 수준으로 좋은 번역인지 안좋은 번역인지 분류해주는 모델.예시)입력: 원문장 - 욕실까지 외부가 아닌 텐트 안에 있어 편의성을 높였다.기계번역문장 - "Even the bathroom is inside the tent, not outside, so the convenience is increased."출력: Good Good Good Good Good Good Good Good Good Good Good Bad Bad Bad
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 문서, 문장, 어절 수준의 기계번역 품질예측 데이터에서 학습 데이터 그리고 평가 데이터 매핑 정확도 Prediction COMET22 + COMET-KIWI Accuracy 50 % 98.2 % 2 문서 수준의 기계번역 품질예측 정확도(MQM, 영-한) Prediction COMET22 + COMET-KIWI Correlation(Kendall) 0.05 점 0.293 점 3 문서 수준의 기계번역 품질예측 정확도(MQM, 한-영) Prediction COMET22 + COMET-KIWI Correlation(Kendall) 0.05 점 0.333 점 4 문장 수준의 기계번역 품질예측 정확도(SQM, 영-한) Prediction COMET22 + COMET-KIWI Correlation(Kendall) 0.05 점 0.344 점 5 문장 수준의 기계번역 품질예측 정확도(SQM, 한-영) Prediction COMET22 + COMET-KIWI Correlation(Kendall) 0.05 점 0.341 점 6 어절 수준의 기계번역 품질예측 정확도 (영-한) Prediction COMET22 + COMET-KIWI Precision 60 % 70.4 % 7 어절 수준의 기계번역 품질예측 정확도 (한-영) Prediction COMET22 + COMET-KIWI Precision 60 % 68.3 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷 대표도면 및 JSON 형식
{ "documentId": "100017-1196",
"fileName": "en-ko_SH_en_ko_100017-1196-1-1_1",
"dataSet": "기계번역 품질 예측 데이터",
"domain": "SH",
"sourceLanguage": "en",
"targetLanguage": "ko",
"segments": {
"segmentId": "100017-1196-1-1",
"index": 1,
"mtSource": "GOOGLE",
"sourceText": "Technically, we don’t know for sure if he’s virus-free.",
"mtText": "기술적으로 우리는 그가 바이러스에 감염되지 않았는지 확실하지 않습니다.",
"score": 40.0,
"document": [
{
"severity": "CRITICAL",
"startPoint": 19,
"endPoint": 28,
"errorSpan": "19-28"
},
{
"severity": "CRITICAL",
"startPoint": 29,
"endPoint": 39,
"errorSpan": "29-39"
}
],
"words": [
{
"wordIndex": 1,
"startPoint": 0,
"endPoint": 5,
"text": "기술적으로",
"state": "Good"
},
{
"wordIndex": 2,
"startPoint": 6,
"endPoint": 9,
"text": "우리는",
"state": "Good"
},
{
"wordIndex": 3,
"startPoint": 10,
"endPoint": 12,
"text": "그가",
"state": "Good"
},
{
"wordIndex": 4,
"startPoint": 13,
"endPoint": 18,
"text": "바이러스에",
"state": "Good"
},
{
"wordIndex": 5,
"startPoint": 19,
"endPoint": 23,
"text": "감염되지",
"state": "Bad"
},
{
"wordIndex": 6,
"startPoint": 24,
"endPoint": 28,
"text": "않았는지",
"state": "Bad"
},
{
"wordIndex": 7,
"startPoint": 29,
"endPoint": 33,
"text": "확실하지",
"state": "Bad"
},
{
"wordIndex": 8,
"startPoint": 34,
"endPoint": 39,
"text": "않습니다.",
"state": "Bad"
}
]
}
}데이터 구성
데이터 구성 데이터 유형 구분 설명 원천데이터 주제 문화예술(CA), 경제사회(ES), 생활건강(SH), 과학기술(ST) 라벨링데이터 사후교정 기계번역 사후교정문 품질주석 기계번역 어절, 문장, 문서 단위 품질 주석 어노테이션 포맷
○ MTPE
어노테이션 포맷○ MTPE No 항목 타입 필수여부 한글명 영문명 1 문서 아이디 documentId String Y 2 파일이름 fileName String Y 3 데이터셋 dataSet String Y 4 도메인 domain String Y 5 소스 언어 sourceLanguage String Y 6 타겟 언어 targetLanguage String Y 7 문서 내 문장 목록 segments Object Y 7-1 문장 아이디 segments.segmentId String Y 7-2 기계번역기 출처 segments.mtSource String Y 7-3 출발어 문장 segments.sourceText String Y 7-4 기계번역 문장 segments.mtText String Y 7-5 사후교정 문장 segments.targetText String Y ○ QE
어노테이션 포맷○ QE 구분 항목 타입 필수여부 한글명 영문명 1 문서 아이디 documentId String Y 2 파일이름 fileName String Y 3 데이터셋 dataSet String Y 4 도메인 domain String Y 5 소스 언어 sourceLanguage String Y 6 타겟 언어 targetLanguage String Y 7 문장 segments Object Y 7-1 문장 아이디 segments.segmentId String Y 7-2 평가자 구분 segments.index Number Y 7-3 기계번역기 출처 segments.mtSource String Y 7-4 출발어 문장 segments.sourceText String Y 7-5 기계번역 문장 segments.mtText String Y 7-6 문장 단위 평가 segments.score Number Y 7-7 문서 단위 평가 segments.document Array Y 7-7-1 심각도 segments.document[].severity String N 7-7-2 오류의 시작 위치 segments.document[].startPoint Number N 7-7-3 오류의 끝 위치 segments.document[].endPoint Number N 7-7-4 오류 span 정보 segments.document[].errorSpan String N 7-8 어절 단위 평가 segments.words Array Y 7-8-1 문장 내 어절 순서 segments.words[].wordIndex Number Y 7-8-2 어절의 시작 위치 segments.words[].startPoint Number Y 7-8-3 어절의 끝 위치 segments.words[].endPoint Number Y 7-8-4 어절 내용 segments.words[].text String Y 7-8-5 어절 평가 segments.words[].state String Y 실제 예시
{ "id": "100008-1-1-1",
"fileName": "TX_CA_1_100008-1-1-1",
"dataSet": "한국어 철자 및 맞춤법 교정용 병렬 데이터",
"domain": "CA",
"ko": "지금까지 다녀 본 여행지 중 좋았던 곳 추천해줘.",
"corrected": "지금까지 다녀 본 여행지 중 좋았던 곳 추천해 줘.",
"error": [
{
"errorType": "spac",
"startPoint": 22,
"endPoint": 27
}
]
}{ "id": "100008-1-1-1",
"fileName": "TX_CA_1_100008-1-1-1",
"dataSet": "한국어 철자 및 맞춤법 교정용 병렬 데이터",
"domain": "CA",
"ko": "지금까지 다녀 본 여행지 중 좋았던 곳 추천해줘.",
"corrected": "지금까지 다녀 본 여행지 중 좋았던 곳 추천해 줘.",
"error": [
{
"errorType": "spac",
"startPoint": 22,
"endPoint": 27
}
]
} -
데이터셋 구축 담당자
수행기관(주관) : 한국외국어대학교
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 신선호 02-2173-2493 [email protected] 데이터 설계 및 원천데이터 가공, 라벨링데이터 검수 수행기관(참여)
수행기관(참여) 기관명 담당업무 엠브레인퍼블릭 원시데이터 수집 및 정제 카카오엔터프라이즈 AI 학습 모델링 ㈜오피니언라이브 저작도구 개발 및 운영, 품질관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 신선호 02-2173-2493 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.