-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-01 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-10 산출물 전체 공개 소개
인간의 행동을 가장 작은 단위의 동작으로 쪼개어, 그 쪼개진 단위마다 알맞은 자연어 캡션을 붙여 행동을 추론하기 위한 데이터 수집
구축목적
본 세부과제에서는 실세계 미디어 영상으로부터 장면 설명문(annotation)을 자동으로 생성하기 위한 인공지능 모델의 학습용 영상 데이터를 구축하고자 함
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 비디오 데이터 형식 mp4 데이터 출처 자체 수집, 구매 영상 라벨링 유형 행동설명(자연어) 라벨링 형식 json 데이터 활용 서비스 영상 내 행동 구간 설명문 서비스 데이터 구축년도/
데이터 구축량2022년/97,382개 .mp4 및 .json -
1. 데이터구축 수량
영상 : 97,382개, 이미지 : 314,489장2. 데이터 분포
2. 데이터 분포 D3 원천데이터 분 시간 드라마 17360 17360 289시간 20분 음악 5537 12653 210시간 53분 반려동물 6987 12033 200시간 33분 스포츠 11205 19055 317시간 35분 여행 11803 24395 406시간 35분 엔터 6824 21364 356시간 4분 요리 12104 19484 324시간 44분 일상 6276 25640 427시간 20분 패션뷰티 9145 20087 334시간 47분 헬스건강 10141 26729 445시간 29분 합계 97382 198800 3313시간 20분 D3 1분 3분 5분 합계 드라마 17360 0 0 17360 음악 3222 1072 1243 5537 반려동물 5468 515 1004 6987 스포츠 8033 2419 753 11205 여행 6311 4688 804 11803 엔터 2571 1236 3017 6824 요리 9956 606 1542 12104 일상 876 1118 4282 6276 패션뷰티 6140 539 2466 9145 헬스건강 3513 4962 1666 10141 합계 63450 17155 16777 97382 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드ㅇ 학습모델
DVC(Dense-Video-Captioning) 분야는 영상에 대한 캡션을 생성하는 Video-Captioning 분야보다 고도화된 분야로, 비디오 내의 행동들에 대한 시간적 위치 및 캡션을 생성한다.ㅇ 데이터 셋 분할
ㅇ 데이터 셋 분할 구분 학습(Learning) 검증(Validation) 시험(Test) 데이터 역할 모델 학습 모델 과적합 방지 모델 검증 건수 및 비율 78,174 (80%) 9,772 (10%) 9,778 (10%) 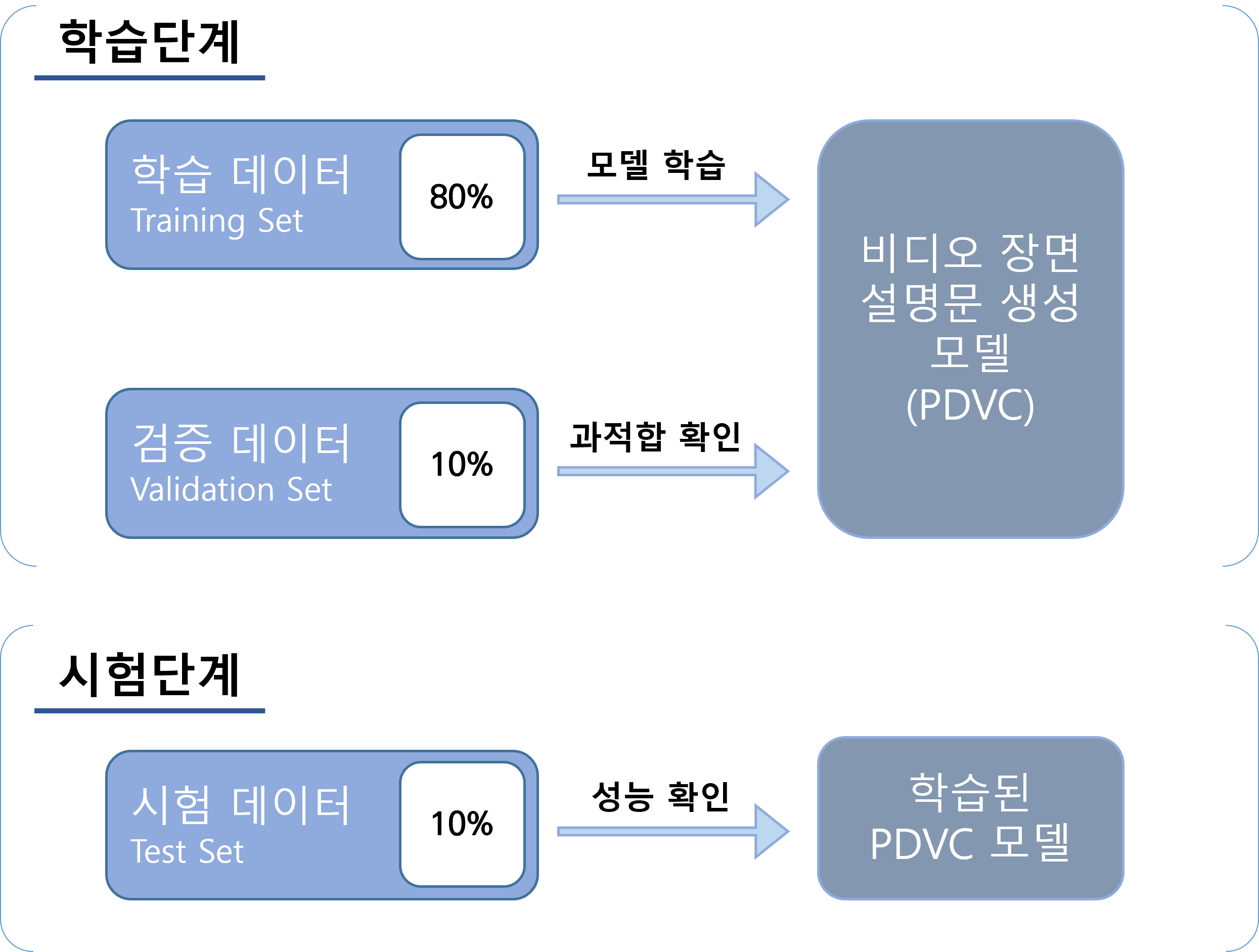
<데이터 사용 단계>
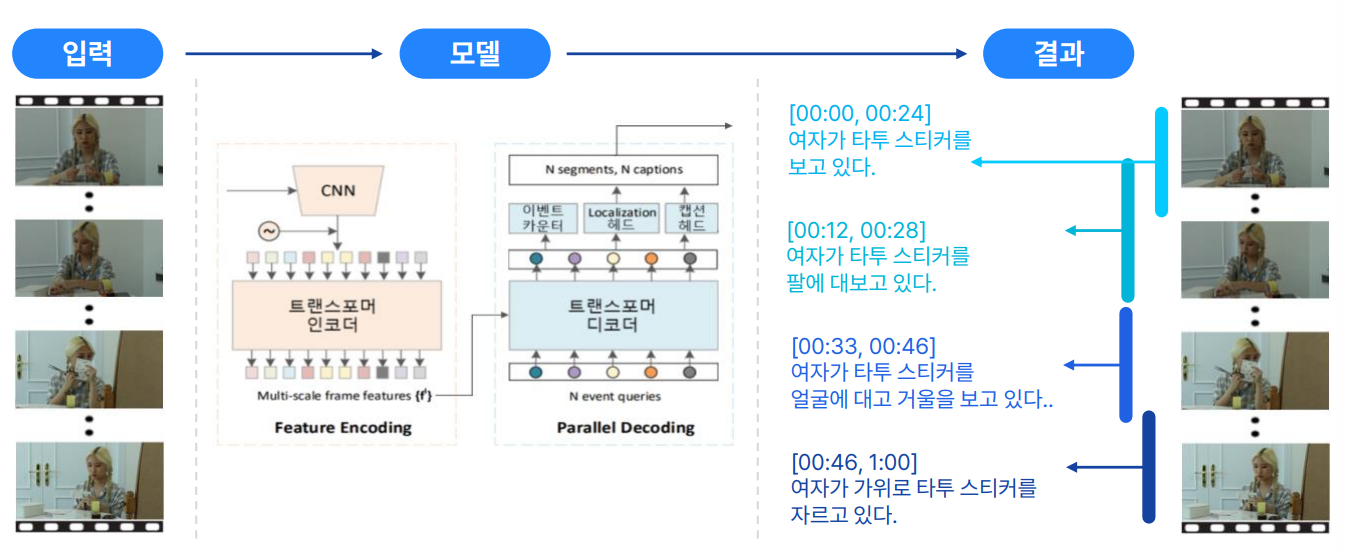
<모델 학습 예시>
ㅇ 활용서비스
컴퓨터 비전 영역
① 장면 설명문 생성
- 영상 내 장면 설명문 생성 분야는 컴퓨터 비전 연구의 주요 분야 중 하나이며 국내에서도 다수의 연구실에서 높은 성과를 거두고 있음
- 관련 연구실에서는 제안하는 데이터 셋을 활용하여 더욱 풍부한 실험을 통해 경쟁력 확보
② 영상 장면 예측
- 영상을 구성하는 장면들의 일반적인 흐름과 구조을 학습하여 앞으로 나올법한 장면을 예측하는 연구 가능
③ 영상 내용 구성 이해
- 장면 설명문을 기반으로 영상 내에서 발생하는 다양한 사건들에 대한 통계적인 분석을 통해 영상의 일반적인 구성에 대해 파악하는 연구 가능
④ 영상 장면 전환 경계 탐색 데이터와 연계
- 장면 설명문 생성 분야를 기반으로, 장면 전환 경계 탐색 데이터를 학습한 인공지능을 활용하여 장면 설명문을 위한 장면을 효율적으로 탐색할 수 있도록 하여 전체 인공지능의 성능을 향상시키고자 하는 연구 가능
미디어 콘텐츠 영역
① 영상 검색 서비스
- 설명문을 메타 데이터로서 활용하여 사용자가 원하는 영상을 효율적으로 검색 하는 인공지능을 활용한 영상 검색 서비스 제공
② 영상 추천 서비스
- 설명문을 메타 데이터로서 활용하여 사용자가 선호할만한 장면이 포함된 영상들을 추천하는 인공지능을 활용한 추천 서비스 제공
③ 요약문 문구 생성 서비스
- 학습된 장면 설명문 생성 인공지능을 기반으로, 장면 간 중요도를 파악하고 중요도가 높은 장면의 설명문을 종합하여 긴 영상 전체를 효과적으로 설명하는 요약문 생성 서비스 제공
④ 영상 자막 보완 서비스
- 설명문 생성 인공지능을 기반으로 장면에 대한 설명을 제공하여 자막 제작자의 장면에 대한 이해를 돕는 서비스 제공
⑤ 영상 자막 생성 서비스
- 설명문 생성 인공지능에 자연어 처리 인공지능을 접목하여 자동으로 장면에 대한 상황과 대사 등에 대한 자막을 생성하는 서비스 제공 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 비디오 장면 설명문(한글) 생성 성능 Text Generation PDVC(end-to-end dense video captioning with parallel decoding) BLEU-4 0.0065 점 0.0489 점 2 비디오 장면 설명문(영어) 생성 성능 Text Generation PDVC(end-to-end dense video captioning with parallel decoding) BLEU-4 0.0075 점 0.0842 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 설명
1. 데이터 설명 구분 분류 설명 원천데이터 도메인 드라마/반려동물_동물/스포츠/엔터테인먼트/여행/ 요리_음식/음악/일상/패션_뷰티/헬스_건강 촬영날짜 220804 파일 D3_DR_0804_000001.mp4 데이터 3번 셋_도메인_영상촬영날짜_영상고유번호 라벨링데이터 D2폴더 드라마/반려동물_동물/스포츠/엔터테인먼트/여행/ 요리_음식/음악/일상/패션_뷰티/헬스_건강 JSON 파일 D3_DR_0824_000001.json 데이터 2번 셋_도메인_영상촬영날짜_영상고유번호 2. Json 형식
▼video info {21}
video_name: D3_AN_0531_000002.mp4
width: 1920
height: 1080
frame_rate: 30
duration: 60.0
total_frame: 1800.0
film_method: filmed_directly
filmed_date: 2022-05-31
domain_id: AN
place: outdoor
f1_consis: 1
f1_consis_avg: 1,
annotated_date: 2022-08-22
version: 1
revision_history: N/A
▼seg_annotator_id [5]
334,
...
▼seg_confirmer_id: [5]
608,
...
distributor: selectstar
describe_ko: 영상 전체 포괄 설명문 (한글)
describe_en: 영상 전체 포괄 설명문 (영어)
▼sentences: {3}
timestamps:
00:00.00000,
00:16.00000
sentences_ko: 구간별 행동 설명문 (한글)
sentences_en: 구간별 행동 설명문 (영어)3. 어노테이션 포맷
3. 어노테이션 포맷 No 항목명 타입 필수 속성 및 내용 1 video_name string y 비디오 파일명 2 width number y 비디오 넓이 3 height number y 비디오 높이 4 frame_rate number y 프레임률 (fps) 5 duration number y 영상 시간 (초 단위) 6 total_frame number y 총 프레임 수 7 film_method string y 영상 수집 방법 8 domain_id string y 도메인 아이디 9 place string y 촬영 장소 10 f1_consis number y 라벨러 수 11 f1_consis_avg number y 라벨러 평균 수 12 annotated_date string y 가공 날짜 13 version number y 버전 정보 14 revision_history string y 데이터 수정 횟수 15 seg_annotator_id string y 라벨러 아이디 16 seg_confirmer_id string y 검수자 아이디 17 distributor string y 가공 업체명 18 describe_ko string y 국문 영상 캡션 (영상 전체) 19 describe_en string y 영문 영상 캡션 (영상 전체) 20 sentences array 타임스탬프 기준 설명문 정보 20-1 timestamps string y 행동 구간 20-2 sentences_ko string y 행동 구간 국문 캡션 20-3 sentences_en string y 행동 구간 영문 캡션 4. Json 실제 예시
{
"video_name": "D3_AN_0531_000002.mp4",
"width": 1920,
"height": 1080,
"frame_rate": 30,
"duration": 60.0,
"total_frame": 1800.0,
"film_method": "filmed_directly",
"filmed_date": "2022-05-31",
"domain_id": "AN",
"place": "outdoor",
"f1_consis": [
1
],
"f1_consis_avg": 1,
"annotated_date": "2022-08-22",
"version": 1,
"revision_history": "N/A",
"seg_annotator_id": [
334,
433,
323,
895,
727
],
"seg_confirmer_id": [
608,
346,
493,
352,
529
],
"distributor": "selectstar",
"describe_ko": "여자가 먹이를 먹는 당나귀를 찍는다.",
"describe_en": "A woman photographs a donkey eating food.",
"sentences": [
{
"timestamps": [
"00:00.00000",
"00:16.00000"
],
"sentences_ko": "여자가 스마트폰으로 사진을 찍는다.",
"sentences_en": "A woman takes a picture with a mobile phone."
} -
데이터셋 구축 담당자
수행기관(주관) : 스파크엑스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 최지민 [email protected] 품질관리실무자 수행기관(참여)
수행기관(참여) 기관명 담당업무 국민대 데이터 품질관리 이지원 데이터 수집 브릭메이트 데이터 정제 셀렉트스타 데이터 가공 코테크시스템 AI 모델 개발 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 최지민 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.