-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-06 데이터 최종 개방 1.0 2023-07-05 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-05 산출물 전체 공개 소개
지문-질문-답변으로 구성된 약 40만 건의 데이터셋으로 수식은 LaTex을, 표는 html 문법을 이용하고 동의 질문을 함께 구축함. ‘정답경계추출형’, ‘YesNo 단문형’, ‘표 정답 추출형’, ‘다지선다형’, ‘절차형’ 5가지로 구분
구축목적
전문 과학/공학 분야 영역을 포함하는 기술과학 문서 기반 인공지능 훈련을 위한 데이터셋으로 기술과학 분야 기계독해 연구, 각종 질의응답 및 지능형 검색 서비스, 기술과학 분야 인공지능 챗봇/스피커 개발 등에 활용 가능
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 국가 오픈액세스 플랫폼 AccessOn, 국내 학회, 전문 서적 출판사 라벨링 유형 질의응답(자연어) 라벨링 형식 JSON 데이터 활용 서비스 기술과학 분야 텍스트의 단락 및 테이블 대상 기계독해 연구, 비정형 데이터 질의응답, 대화형 시스템 연구 및 기술과학 문서 내용 기반 지능형 검색 및 질의응답, 챗봇 질의응답, 웹 기반 질의응답, 인공지능 스피커, 교육용 튜터 데이터 구축년도/
데이터 구축량2022년/400,000건 -
1. 데이터 통계
- 데이터 구축 규모데이터 구축 규모 수량 원시 데이터 6,853건 원천 데이터 22,616건 질의응답 라벨링 데이터 400,346건 - 데이터 분포
● 기술 과학 문서 연도 분포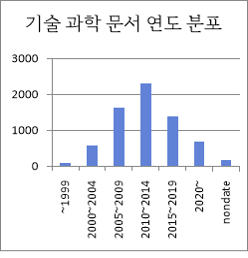
데이터 구축 규모 연도 수량 구성비 ~1999 83 1% 2000~2004 579 8% 2005~2009 1646 24% 2010~2014 2308 34% 2015~2019 1390 20% 2020~ 675 10% nondate 172 3% 합계 6853 100% ● 지문 구성 비율
지문 구성 비율 지문 내 표 여부 수량 구성비 Y 6823 30% N 15793 70% 합계 22616 100% ● 표 유형 분포
표 유형 분포 표 유형 수량 구성비 0 15793 70% 1 4460 20% 2 2363 10% 합계 22616 100% 표 유형 분포 표기 0 1 2 의미 표가 포함되지 않음 depth1 표 포함 depth2 표 포함 ● 질문 유형(Yes/No단문형 제외)
질문 유형 질문 유형 수량 구성비 who 2715 1% when 4030 1% where 10198 3% what 260605 76% why 10252 3% how 55024 16% 합계 342824 100% ● 질문 난이도
질문 난이도 질문 난이도 수량 구성비(%) 상 56875 14% 중 60819 15% 하 282652 71% 합계 400346 100% ● 지문 길이 분포
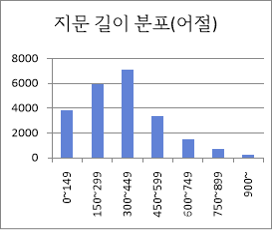
지문 길이 분포 어절 수량 구성비 0~149 3826 17% 150~299 5933 26% 300~449 7056 31% 450~599 3388 15% 600~749 1476 7% 750~899 698 3% 900~ 239 1% 합계 22616 100% ● 질의 문장 길이 분포
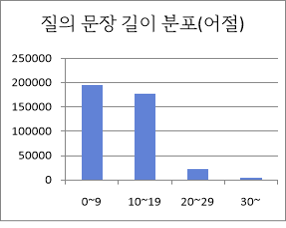
질의 문장 길이 분포 어절 수량 구성비 0~9 195236 49% 10~19 177610 44% 20~29 22525 6% 30~ 4975 1% 합계 400346 100% ● 답변 문장 길이 분포
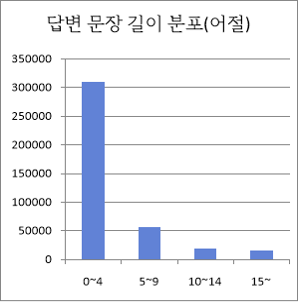
답변 문장 길이 분포 어절 수량 구성비 0~4 309644 77% 5~9 56677 14% 10~14 18724 5% 15~ 15301 4% 합계 400346 100% ● 지문 당 질문 수 분포
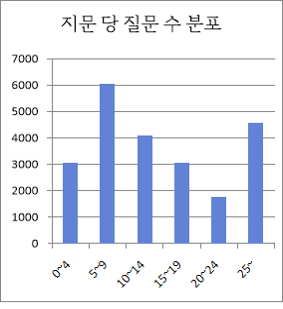
지문 당 질문 수 분포 질문 수 수량 구성비 0~4 3072 14% 5~9 6048 27% 10~14 4104 18% 15~19 3054 14% 20~24 1773 8% 25~ 4565 20% 합계 22616 100% ● 동의 질의 수 분포
동의 질의 수 분포 동의 질문 수량 구성비 원질문 313147 78% 원질문 + 동의질문 87199 22% 합계 400346 100% ● 답변 유형
답변 유형 답변 유형 수량 구성비 정답경계추출형 164114 41% YesNo단문형 57522 14% 표 정답 추출형 100069 25% 다지선다형 39828 10% 절차형 38813 10% 합계 400346 100% ● 기술 과학 문서 K-NSCC 분포
K-NSCC 분포 대분류 중분류 분류코드 개수 구성비 분류코드 개수 구성비 ED 159144 40% 1 8529 2.13% 2 2989 0.75% 3 11759 2.94% 4 23642 5.91% 5 14749 3.68% 6 8673 2.17% 7 12186 3.04% 8 18929 4.73% 9 4337 1.08% 10 10732 2.68% 11 18111 4.52% 99 24508 6.12% EE 166625 42% 1 26564 6.64% 2 22024 5.50% 3 11291 2.82% 4 22514 5.62% 5 12635 3.16% 6 12274 3.07% 7 5853 1.46% 8 3484 0.87% 9 2516 0.63% 10 2649 0.66% 11 12315 3.08% 12 1348 0.34% 13 1028 0.26% 14 2539 0.63% 99 27591 6.89% LA 64489 16% 1 8493 2.12% 2 8200 2.05% 3 1517 0.38% 4 8317 2.08% 5 5575 1.39% 6 3512 0.88% 7 763 0.19% 8 8925 2.23% 9 10079 2.52% 10 644 0.16% 11 1631 0.41% 99 6833 1.71% NA 10088 3% 1 1016 0.25% 2 3068 0.77% 3 357 0.09% 4 1701 0.42% 5 97 0.02% 6 408 0.10% 7 135 0.03% 8 174 0.04% 9 408 0.10% 10 1508 0.38% 99 1216 0.30% 합계 400346 100% 합계 400346 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드학습 모델 학습 모델 한국어 기술과학 전문 질의 응답 모델, 한국어 기술과학 전문 테이블 질의 응답 모델 모델 Longformer, TAPEX(KoBART) 성능 지표 질의응답 - F1 75% 이상, 테이블 질의응답 -EM 50% 개발 내용 구축되는 학습데이터를 활용하여 기술과학 전문 질의 응답이 가능한, 길이가 긴 문서와 표가 포함된 지문 내에서 정답을 추출해 낼 수 있는 Longformer, TAPEX(KoBART) 기반의 모델 개발 응용서비스 본 기술과학 특화 모델과 대량의 지식 베이스를 이용해 기술과학 전문 질의응답이 가능한 교육용 AI 튜터 서비스 (예시 및 유의사항) 질문에 적합한 컨텍스트를 찾아내고 정답을 추론하는 open-domain 질의응답 모델 개발 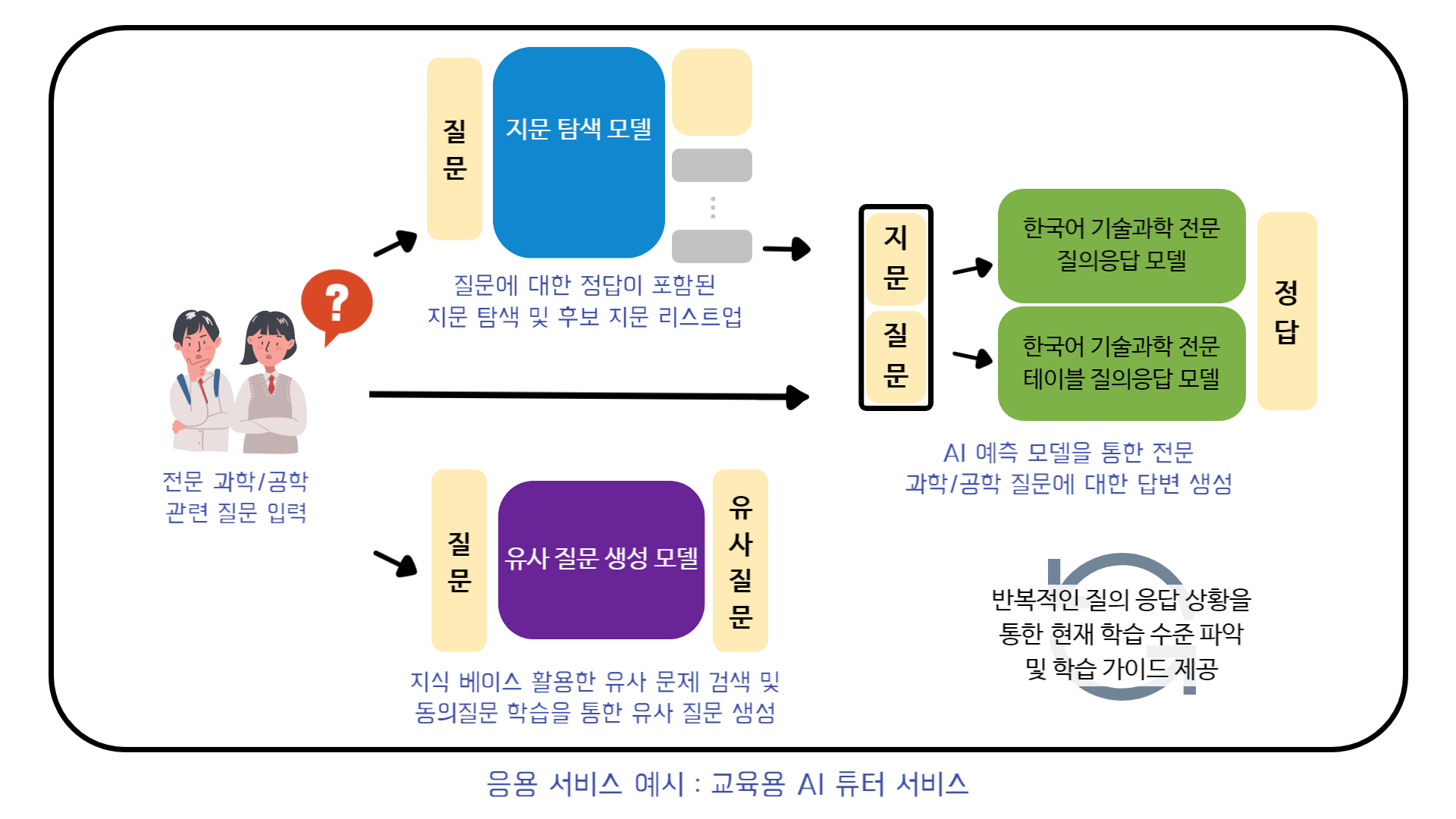
□ 응용 서비스 개발 예시 : 교육용 AI 튜터 서비스
● 지문 탐색 모델 : 구축된 대량의 전문 과학/공학 데이터를 통해 지식 베이스를 구축하여 사용자가 입력한 질문에 대한 정답이 포함된 지문 탐색 후 후보 지문 리스트업 가능한 모델을 개발하여 참고 자료 제시 및 질의응답(기계독해) 모델의 지문으로서 사용
● 유사 질문 생성 모델 : 축된 대량의 전문 과학/공학 데이터를 통해 지식 베이스를 구축하여 유사 문제 검색과 또 각 질문 데이터에 부착된 동의질문으로 유사 질문 생성 학습을 통해, 사용자가 입력한 질문의 유사 문제를 제공
● 튜터 서비스 : 반복적인 질의 응답 내역(상황)을 저장하면서 현재 학습 수준 파악 및 학습 진행 가이드 제공 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 긴 문서에 대한 질의응답 성능 Question Answering longformer(The Long-Document Transformer) EM 70 % 74.18 % 2 테이블 질의응답 성능 Question Answering tapex(Table Pre-training via Learning a Neural SQL Executor) EM 50 % 51.63 % 3 긴 문서에 대한 질의응답 성능 Question Answering longformer(The Long-Document Transformer) F1-Score 0.73 점 0.883 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- 포맷 예시포맷 예시 문서 제목 티타늄 박막을 이용한 염료감응형 태양전지 모듈 특성에 관한 연구 유형 기계독해-정답경계추출형 분류 ED 지문 \( \mathrm{Ti} \) 금속 전극을 사용한 염로감응형 태양전지 모듈은 단위셀과 달리 하나의 기판 내에 셀들을 분리시켜 태양 빛에 의해 변환되는 전력을 증가시킬 수 있다. 설계된 모듈은 \(3 \)셀의 Z-타입(type)이였으며, 유리기판을 \( 43 \times 46 \mathrm{~mm} \) 크기로 재단하였다. 단위셀 공정과는 달리 \( \mathrm{Ti} \) 박막을 레이저 패터닝해서 \(3 \)개의셀로 분리시켰으며 기판을 세척하였다. \( \mathrm{Ti} \) 박막이 증착된 기판에 \( \mathrm{TiO}_{2} \) 광전극 베이스트를 코팅해서 광전극 기판을 형성하고, 투명한 전도성 기판에는 \( \mathrm{Pt} \) 페이스트를 인쇄하여 상대전극 기판을 형성하였다. 전자를 원활히 포집하기 위해서 포전성 페이스트를 인쇄해서 그리드(grid)와 버스바(busbar)를 형성시켰다. \( 120^{\circ} \mathrm{C} \)에서 건조공정을 거쳐 \( 45^{\circ} \mathrm{C} \) 에서 광전극 및 상대전극 기판을 소성한 후 광전극을 \( 0.5 \mathrm{mM}\) N19 염료에 담지해 염료를 흡착하였다. 염료가 흡착된 광전극 기판과 상대전극 기판을 \(60 \) \( \mu \mathrm{m} \) 의 두께를 갖는 Surlyn을 사용하여 \( 120^{\circ} \mathrm{C} \) 에서 \(10 \)분간 열을 가해 접합하였다. 최종적으로 전해질을 주입하고 외부를 실링하여 염료감응형 태양전지 모듈을 제작한 후 에너지 변환효율을 평가하였다. 그림 \( 2 \frac{2}{2}= \) 염료감응형 태양전지 모듈 제작 공정을 나타내고 있으며, 사용한 재료는 단위셀 제조 방법에서 상용 것과 동일하다. 단서문장 전자를 원활히 포집하기 위해서 포전성 페이스트를 인쇄해서 그리드(grid)와 버스바(busbar)를 형성시켰다. 질문 포전성 페이스트를 인쇄해 그리드(grid)와 버스바(busbar)를 형성한 이유가 뭐야? 답변 전자를 원활히 포집하기 위해서 포맷 예시 유형 기계독해-Yes/No 단문형 분류 ED 단서문장 \( \mathrm{Ti} \) 금속 전극을 사용한 감응형 태양전지 모듈은 단위셀과 달리 하나의 기판 내에 셀들을 분리시켜 태양 빛에 의해 변환되는 전력을 증가시킬 수 있다. 질문 \( \mathrm{Ti} \) 금속 전극을 사용한 염료감응형 태양전지 모듈을 이용하면 태양 빛에 의해 변환되는 전력을 증가시킬 수 있어? 답변 YES 포맷 예시 유형 기계독해-절차(방법)형 분류 ED 단서문장 단위셀 공정과는 달리 \( \mathrm{Ti} \) 박막을 레이저 패터닝해서 \(3 \)개의셀로 분리시켰으며 기판을 세척하였다. \( \mathrm{Ti} \) 금속 전극을 사용한 염로감응형 태양전지 모듈은 단위셀과 달리 하나의 기판 내에 셀들을 분리시켜 태양 빛에 의해 변환되는 전력을 증가시킬 수 있다. 질문 염료감응형 태양전지 모듈을 만들 때 \( \mathrm{Ti} \) 박막을 여러 개의 셀로 분리하기 위해서 어떤 과정을 거쳤어? 답변 레이저 패터닝 포맷 예시 유형 기계독해-다지선다형 분류 ED 단서문장 염료가 흡착된 광전극 기판과 상대전극 기판을 \(60 \) \( \mu \mathrm{m} \) 의 두께를 갖는 Surlyn을 사용하여 \( 120^{\circ} \mathrm{C} \) 에서 \(10 \)분간 열을 가해 접합하였다. 질문 염료가 흡착된 광전극 기판과 상대전극 기판을 접합할 때 어떤 온도와 시간 조건으로 열을 가했어? 답변 \( 120^{\circ} \mathrm{C} \) 에서 \(10 \)분간 정답이 아닌 지시문 \( 120^{\circ} \mathrm{C} \) 에서 \(1 \)분간 \( 20^{\circ} \mathrm{C} \) 에서 \(10 \)분간 동의질문 어떤 온도와 시간 조건으로 염료가 흡착된 광전극 기판과 상대전극 기판을 접합할 때 열을 가했지? \( 100^{\circ} \mathrm{C} \) 에서 \(10 \)분간 \( 120^{\circ} \mathrm{C} \) 에서 \(20 \)분간 - JSON 형식
[
{
"context_id": b8f1c479-2365-4975-a3fa-da9321fe62f0",
"context_K-NSCC": {
"field": "자연",
"large_category": "ED",
"medium_category": "11“
}
"context_length": 372,
"context": "요약
본 논문에서 \(3\)차원 레이다 시험용 타이밍신호 발생기를 개발하였다. 개발된 발생기는 모의표적신호에 고각 정보를 모의할 수 있는 기능을 갖추었고, 내부에 구상변조 기능을 가지고 있어 \(80\\mathrm{MHz}\)까지의 변조된 신호를 발생할 수 있다. 또한 기저대역신호를 외부에서 입력받아 중간주파수로 변환하는 과정을 보드 내에서 처리가 가능하므로 다양한 시험환경을 쉽게 구현할 수 있고 별도의 파형합성기가 필요 없어 저렴한 비용으로 레이다 시험 장비 구성이 가능하다. 아울러 운용프로그램에 따라 쉽게 파라미터를 변경할 수 있는 충분한 메모리를 내장하고 있어 시험환경을 변경할 필요가 있을 때 시간 및 비용을 절감할 수 있다.
",
"qas":[
{
"question_id": 000001,
"question_type": "what",
"qeustion_level": "하",
"question": [
{"000001-1": "본 논문에서는 무엇을 개발했어"},
{"000001-2": "본 논문에서 개발한 발생기는 어떤 발생기야"},
]
"answer": "$3$차원 레이다 시험용 타이밍신호 발생기",
"answer_type": "extract_boundary",
"answer_start": 21,
"answer_end": 44,
"clue":[
{clue_start: 14, clue_end: 54}
]
},
{
"question_id": 000002,
"question_type": "what",
"qeustion_level": "하",
"question":[
{"000002-1": "본 논문에서 개발한 레이다 시험용 타이밍 신호 발생기는 몇 차원이야"},
{"000002-2": "본 논문에서는 몇 차원의 레이다 시험용 타이밍신호 발생기를 개발했어"}
],
"answer": "$3$차원",
"answer_type": "extract_boundary",
"answer_start": 21,
"answer_end": 26,
"clue":[
{clue_start: 14, clue_end: 54}
]
}
]
},
{
"context_id": 0f450d72-97ef-4029-8c94-0e305624f4a2",
"context_K-NSCC": {
"field": "자연",
"large_category": "ED",
"medium_category": "03“
}
"context_length": 723,
"context": "일반적으로 초전도 한류기는 변압기 \(2\)차측, 모선 또는 주급전선에 설치한다. 이는 전력이 송전계통망을 통해 배전계통으로 전송되는 구조에 기인한 결과이다. 본 논문에서는 초전도한류기를 주 급전선의 circuit breaker 연계 지점에 설치하였다.
본 논문의 사례연구를 수행하기 위한 수용가 정보는 다음과 같다.
표 \(4\) 수용가 정보 부하 번호 수용가 수 평균 부하량 \( [ \mathrm{kW}] \) L\( 1 \) \( 1000 \) \( 5000 \) L\( 2 \) \( 800 \) \( 5000 \) L\( 3 \) \( 700 \) \( 3000 \) L\( 4 \) \( 500 \) \( 2000 \) L\( 5 \) \( 1000 \) \( 5000 \) 합계 \( 4000 \) \( 19000 \) ",
"qas":[
{
"question_id": 000003,
"question_type": "what",
"qeustion_level": "상",
"question": [
{"000003-1": "본 논문의 사례연구를 수행하기 위한 수용가 정보에서, 부하 번호 L\(3\)의 수용가수는 몇 개인가"},
{"000003-2": "표\(4\)에서 부하 번호 L\(3\)의 수용가수는 몇 개인가"}
],
"answer": "\(700\)",
"answer_type": "table_extract_boundary",
"answer_start": 478,
"answer_end": 481,
"clue":[
{clue_start: 190, clue_end: 723}
]
}
]
}
]2. 데이터 구성 및 어노테이션 포맷
데이터 구성 및 어노테이션 포맷 구 분 항목명 타입 필수 설명 범위 1 dataset 데이터셋 라벨 정보 1-1 string y 데이터셋 식별자 identifier 1-2 name string y 데이터셋 명 1-3 category number y 데이터셋 분류 1-4 last_updated number y 마지막 갱신 날짜 2 doc_info 원시 데이터 정보 2-1 doc_id number y 원시 데이터 일련번호 2-2 doc_type string y 유형 2-3 doc_title 제목 2-3-1 kor string y 국문 제목 2-3-1 eng string y 영문 제목 2-4 doc_category 분류 번호 2-4-1 KDC string y KDC 분류 번호 2-4-2 DDC string y DDC 분류 번호 2-5 doc_number 식별 번호 2-5-1 ISSN string y ISSN 번호 2-5-2 ISBN string y ISBN 번호 2-5-3 DOI string y DOI 번호 2-5-4 UCI string y UCI 번호 2-6 doc_year string y 발행일 2-7 doc_author string y 저자 2-8 doc_publisher string y 출판사 2-9 doc_license string y 저작권 정보 2-10 context_info[] 원천 데이터 정보 2-10-1 context_id number y 원천 데이터 일련번호 2-10-2 context_K-NSCC 국가표준과학분류체계 2-10-2-1 field string y 과학기술 분야 2-10-2-2 large_category string y 대분류 2-10-2-3 medium_category number y 중분류 2-10-3 context_length number y 길이 2-10-4 context string y 원천 데이터 지문 정보 2-10-5 table_type string y 테이블 포함 여부, 유형 0,1,2 2-10-6 qas[] 원천 데이터 별 라벨 정보 2-10-6-1 question_id number y 라벨 일련번호 2-10-6-2 question1 string y 질문 (원질문) 2-10-6-2‘ question2 string y 질문 (동의질문) 2-10-6-3 question_type string y 질문 유형(5W1H) 5W1H 2-10-6-4 question_level string y 질문 난이도 상중하 2-10-6-5 answer string y 답변 2-10-6-6 answer_type string y 답변 유형 유형 2-10-6-7 answer_start number n 답변 시작 위치(추출형) 2-10-6-8 answer_end number n 답변 종료 위치(추출형) 2-10-6-9 clue[] 단서 2-10-6-9-1 clue_start number y 단서 시작 위치 2-10-6-9-2 clue_end number y 단서 종료 위치 2-10-6-10 wrong_answer[] string n 틀린 지시문 (다지선다형) -
데이터셋 구축 담당자
수행기관(주관) : 경북대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정호영 053-950-2337 [email protected] 사업 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 유니바 AI 모델 및 저작도구 개발 제이솔루션 데이터 정제 및 가공 엠엔비젼 데이터 정제 및 가공 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정호영 053-950-2337 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.