중·노년층 한국어 방언 데이터 (충청도, 전라도, 제주도)
- 분야한국어
- 유형 오디오 , 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2024-07-02 원천데이터 수정 1.1 2023-11-03 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-27 Sample 파일 추가 공개 2023-12-15 산출물 전체 공개 2023-11-30 데이터 통계 수정 데이터 구축 규모 수정 소개
충청도, 전라도, 제주도 지역의 50대 이상 발화자가 발화한 따라말하기(정형), 질문답하기(비정형), 2인대화(비정형) 의 방언 발화 음성 데이터
구축목적
중노년층의 음성 특징과 지역별 방언 특징을 최대로 표출하여 다각적으로 활용 가능한 데이터를 구축하여 중노년층 방언 사용자의 음성인식률 상승 및 사멸 위기인 방언의 보존
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 , 텍스트 데이터 형식 wav 데이터 출처 직접 수집 라벨링 유형 전사, 주석 라벨링 형식 Json 데이터 활용 서비스 챗봇 서비스, 온라인 심리상담, 스마트 스피커 등 데이터 구축년도/
데이터 구축량2022년/2,004시간 -
■ 데이터 통계
□ 데이터 구축 규모데이터 통계 - 데이터 구축 규모 지역 종류 데이터 형태 규모 충청도 원천 데이터 .wav 801.1시간 라벨링 데이터 .json 161,415건 전라도 원천 데이터 .wav 1015시간 라벨링 데이터 .json 179,844건 제주도 원천 데이터 .wav 207.2시간 라벨링 데이터 .json 56,666건 ■ 데이터 분포
□ 발화 타입 비율데이터 분포 - 발화 타입 비율 지역 종류 지역 비율 발화 타입 발화 건수(시간) 발화 타입 비율 충청도 40% 따라말하기 246.6시간 31% 질문답하기 395.8시간 49% 2인대화 158.9시간 20% 전라도 50% 따라말하기 300.9시간 30% 질문답하기 509.9시간 50% 2인대화 204.2시간 20% 제주도 10% 따라말하기 66.1시간 32% 질문답하기 100.6시간 49% 2인대화 40.5시간 20% 합계 100% - 2,023시간 - □ 성별 비율
데이터 분포 - 성별 비율 구분 충청도 전라도 제주도 남성 28% 31% 17% 여성 72% 69% 83% 합계 100% 100% 100% □ 연령대 비율
데이터 분포 - 연령대 비율 구분 충청도 전라도 제주도 50대 45% 40% 65% 60대 25% 25% 28% 70대 23% 27% 6% 80대 6% 8% 1% 합계 100% 100% 100% □ 거주기간 비율
데이터 분포 - 거주기간 비율 구분 충청도 전라도 제주도 20~29년 41% 36% 21% 30~39년 21% 10% 6% 40~49년 9% 11% 6% 50~59년 10% 16% 41% 60~69년 9% 14% 22% 70~79년 8% 10% 4% 80~89년 2% 2% 0% 합계 100% 100% 100% □ 학력 비율
데이터 분포 - 학력 비율 구분 충청도 전라도 제주도 초졸이하 13% 13% 2% 중졸이하 35% 36% 21% 고졸이하 28% 19% 44% 대학원이하 24% 32% 34% 합계 100% 100% 100% □ 건강상태 비율
데이터 분포 - 건강상태 비율 구분 충청도 전라도 제주도 무 99% 96% 100% 치아손실 1% 4% 0% 조음장애 0% 0% 0% 치아손실, 조음장애 0% 0% 0% 합계 100% 100% 100% □ 주제 비율
데이터 분포 - 주제 비율 구분 충청도 전라도 제주도 가족 16% 26% 22% 자연 10% 10% 10% 건강 12% 11% 8% 주 11% 7% 9% 농경 12% 13% 12% 의 11% 9% 10% 식 12% 10% 12% 풍속 9% 9% 8% 응급상황 8% 5% 8% 합계 100% 100% 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드■ 활용 모델
□ 모델 학습
- 감정분류 모델의 경우 Bert 모델 활용하며, 검증용 데이터와 시험용 데이터는 전체 데이터의 10%로 제한
- 음성인식 모델의 경우 Conformer 모델 활용하며, 검증용 데이터와 시험용 데이터는 전체 데이터의 10%로 제한모델 학습 학습(Train) 검증(Validation) 시험(Test) BERT MLM과 NSP를 위해 Transformer를 기반으로 구성되며, CNN 및 RNN을 사용하지 않고 self-attention 개념을 도입 Conformer 광역 정보를 잘 표현할 수 있는 트랜스포머와 지역 정보를 잘 표현할 수 있는 CNN을 결합한 신경망 비율 80% 10% 10% 학습 알고리즘 구조 학습 알고리즘 구조 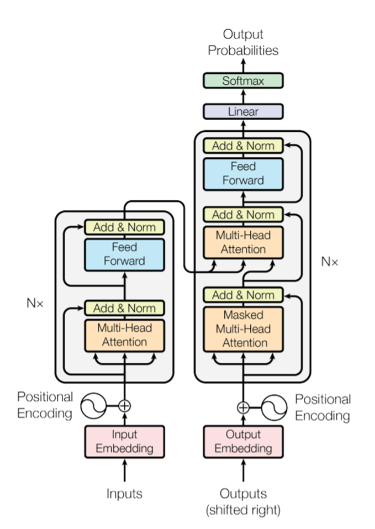

Bert Conformer □ 서비스 활용 시나리오
- 전국 각 시, 도 지역 방언 음성 인식 서비스
AI 기반 서비스에 대한 접근성 향상
AI 음성인식 기반 서비스의 품질 향상
- 노인 대상 home AI 비서 서비스
노인들의 고독사 예방과 같은 사회 문제 해별
노인 복지 향상 기여
- 온라인 심리상담, 고객상담 챗봇 서비스
성능이 향상된 한국어 음성 인식 모델을 통한 중노년층의 편의성 향상
- 음성 발화, 음성 인식 등 연구에 활용 가능
음성 발화, 음성 인식 등 연구 지원 및 사멸 위기 언어 보존 연구 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드■ 데이터 포맷
데이터 포맷 유형 예시 데이터 형식 원천 데이터 
.wav 
라벨링 데이터 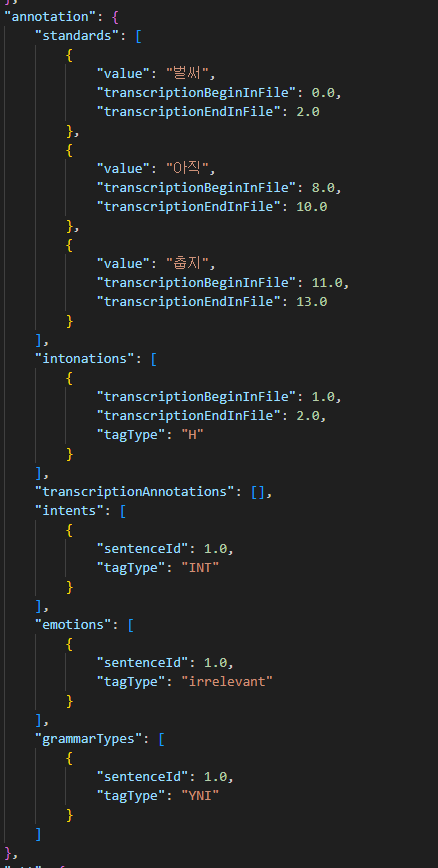
.json ■ 어노테이션 포맷
어노테이션 포맷 구분 속성명 타입 필수여부 설명 범위 비고 1 fileName string Y 파일 이름 음성타입_세트번호_수집자ID_발화자ID_녹음번호_시간(초) 2 speaker object Y 발화자 정보 2-1 speakerId string Y 발화자 ID speaker[지역코드][일련번호] 2-2 gender string Y 성별 여성, 남성 2-3 birthYear number Y 출생년도 1932/1973 출생년도 4자리 2-4 residenceProvince string Y 거주 도 cc : 충청도, jl : 전라도 jj : 제주도 2-5 residenceCity number Y 거주 읍/군/시 최솟값 :1 최댓값: 129 2-6 residencePeriod number Y 지역 거주 기간 거주년 수 2-7 job string Y 직업 ex) 농부 2-8 academicBackground number Y 학력 01월 04일 1:초졸이하,2:중졸이하,3:고졸이하,4:대학원이하 2-9 healthCondition number Y 건강상태 01월 04일 1:무 ,2:치아손실, 3:조음장애,.4:치아손실, 조음장애 3 collector object Y 수집자 정보 3-1 collectorId string Y 수집자 ID collector[지역코드][일련번호 4자리] 3-2 residenceProvince string Y 거주 도 cc : 충청도, jl : 전라도 jj : 제주도 3-3 residenceCity number Y 거주 읍/군/시 코드번호 3-4 residencePeriod number Y 지역거주 기간 거주년 수 4 script object Y 수집자료 정보 4-1 scriptId number Y 문장번호 녹음시 제시된 문장 번호 4-2 value string Y 발화유도 스크립트 따라말하기 문장, 질문 지시문 4-3 domain string Y 수집문 주제 도메인 농경, 가족, 의,식,주, 자연, 건강, 풍속, 응급상황 4-4 speechType string Y 발화유형 Read:정형(따라말하기),Speak:비정형(질문답하기/2인대화) 5 audio object Y 오디오정보 5-1 speechStartTime string Y 음성 시작 시각 음성 시작 시각 (HH:MM:SS) 5-2 speechEndTime string Y 음성 종료 시각 음성 종료 시각 (HH:MM:SS) 5-3 recordDuration number Y 녹음 길이 1 녹음시간 (Second) 5-4 bitsPerSample number Y 오디오 비트레이트 비트레이트 수치(BPS) 5-5 samplingFrequency number Y 샘플링주파수 주파수 수치(Hz) 5-6 channel string Y 녹음 채널 녹음 채널 수 5-7 recordDate string Y 녹음 일자 YYYYMMDD 6 stt object Y 음성인식결과 6-1 recognizer string Y 음성인식기출처 음성인식프로그램명 6-2 responseDate string Y 음성인식실행일 음성인식실행일자 6-3 speakerIds array Y 발화자ID 목록 1 speaker[지역코드][일련번호] 6-4 segments array Y 음성인식결과(부분) 어절단위 추정 음성구간 6-4-1 orderInFile number Y 파일 내 순서 1 1부터 시작 6-4-2 startTime string Y 음성인식대상오디오시작구간 음성인식대상오디오시작구간 6-4-3 endTime string Y 음성인식대상오디오종료구간 음성인식대상오디오종료구간 6-4-4 value string Y 음성인식결과 문자열 음성인식결과 문자열 7 transcription object Y 7-1 pronunciation string Y 발음 전사문 발음 전사문 7-2 dialect string Y 방언표기 전사문 방언표기 전사문 7-3 standard string Y 표준표기치환문 표준표기치환문 7-4 segments array Y 전사단위 전사단위(어절 또는 구) 7-4-1 orderInFile number Y 파일 내 순서 1 1부터 시작 7-4-2 startTime string Y 문장시작오디오구간 문장시작오디오구간 7-4-3 endTime string Y 문장종료오디오구간 문장종료오디오구간 7-4-4 voiceType string Y 발화유형(발화잡음, 발화) 발화유형(발화잡음, 발화) 7-4-5 pronunciation string N 발음전사 발음전사 7-4-6 dialect string Y 방언표기(표기전사) 방언표기(표기전사) 7-4-7 standard string N 표준어 대응표현 표준어 대응표현 7-5 sentences array Y 7-5-1 sentenceId number Y 문장번호 1 1부터 시작 7-5-2 speakerId string Y 화자ID speaker[지역코드][일련번호] 7-5-3 startTime string Y 문장시작오디오구간 문장시작오디오구간 7-5-4 endTime string Y 문장종료오디오구간 문장종료오디오구간 7-5-5 pronunciation string Y 발음전사 발음전사 7-5-6 dialect string Y 방언표기(표기전사) 방언표기(표기전사) 7-5-7 standard string Y 표준어 대응표현 표준어 대응표현 7-5-8 intonations array Y 억양 8 annotation object Y 주석(어노테이션)정보 8-1 standards array Y 표준어 대응표현 8-2 transcriptionBeginInFile number N 표준어대응표현주석시작위치(문자열오프셋) 8-3 transcriptionEndInFile number N 표준어대응표현주석끝위치(문자열오프셋) 8-4 value string N 표준어대응표현 8-2 intonations array Y 억양 8-2-1 transcriptionBeginInFile number N 억양주석시작위치(문자열오프셋) 억양주석시작위치(문자열오프셋) 8-2-2 transcriptionEndInFile number N 억양주석끝위치(문자열오프셋) 억양주석끝위치(문자열오프셋) 8-2-3 tagType string N 억양주석표지값 억양주석표지값 8-3 transcriptionAnnotations array Y 전사주석 전사주석(간투사,반복,개인정보,청취불가,영어/숫자) 8-3-1 transcriptionBeginInFile number N 전사주석시작위치(문자열오프셋) 전사주석시작위치(문자열오프셋) 8-3-2 transcriptionEndInFile number N 전사주석끝위치(문자열오프셋) 전사주석끝위치(문자열오프셋) 8-3-3 tagType string N 전사주석표지값 전사주석표지값 8-4 intents array Y 발화의도 8-4-1 sentenceId number Y 문장번호 1 문장번호 8-4-2 tagType string Y 의도주석표지값 의도주석표지값: 화자의견, 화자느낌, 사실묘사, 질문, 명령, 부탁/요청/제안, 기타 8-5 emotions array Y 감정주석 감정주석 8-5-1 sentenceId number Y 문장번호 1 문장번호 8-5-2 tagType string Y 감정주석표지값 감정주석표지값 8-6 grammarTypes array Y 문장유형 8-6-1 sentenceId number Y 문장번호 1 8-6-2 tagType string Y 문장유형주석표지값 문장유형주석표지값 ■ 실제 예시
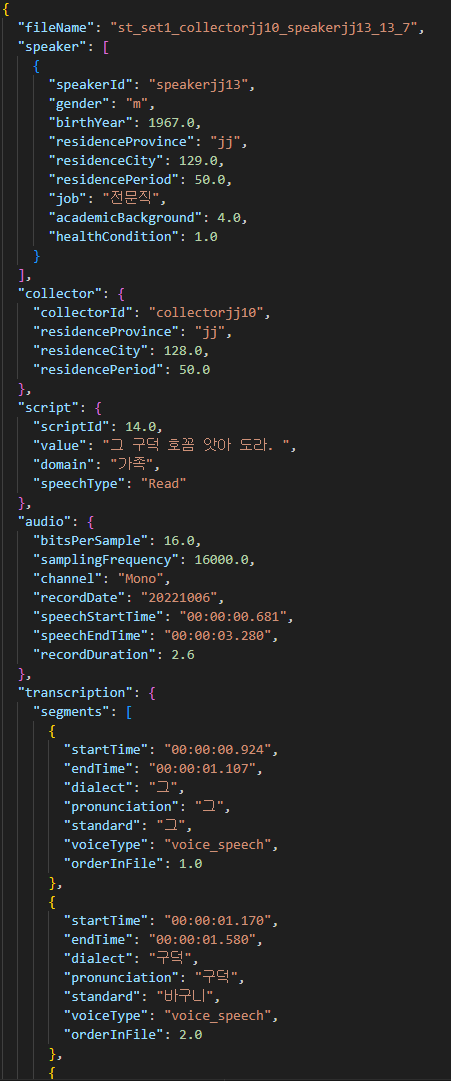

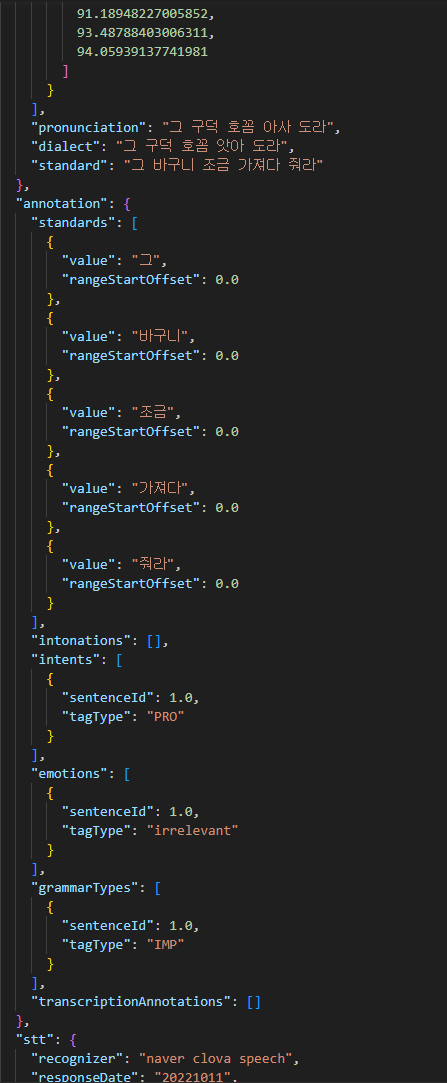
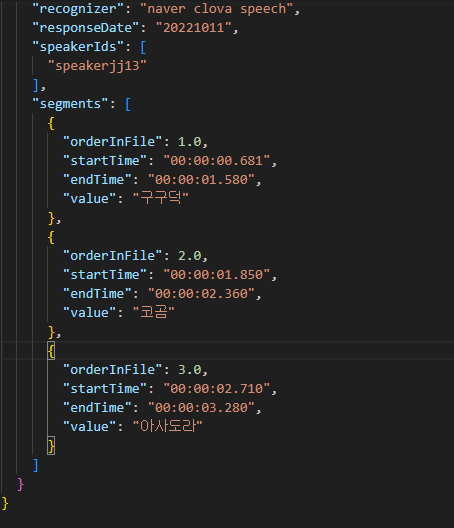
-
데이터셋 구축 담당자
수행기관(주관) : 엠티데이타
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 최상봉 070-4294-8810 [email protected] 데이터 정제 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜컨슈머인사이트 음성 수집 ㈜디그랩 가공_전사 ㈜브이티더블유 품질검사 ㈜스타셀 음성인식 학습_AI 모델 ㈜올림커뮤니케이션즈 감정분류 학습_AI 모델 세종대학교 산학협력단 가공_주석 혁신과 미래 사회적 협동조합 크라우드 워커 관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 최상봉 070-4294-8810 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.