방송콘텐츠 한국어-아시아어 번역 말뭉치
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-01-10 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-07-15 데이터 설명서, 구축업체 정보 수정 2023-12-15 산출물 전체 공개 소개
방송콘텐츠의 인공신경망기계번역기(Neural Machin Translation;NMT) 성능향상을 위하여 학습데이터로 활용하기 위한 한국어-아시아어 음성 및 말뭉치 데이터
구축목적
한국어 방송콘텐츠 분야의 아시아어 통·번역 성능 향상 및 상황별 신조어, 약어, 은어, 관용적 의미와 어투까지 효과적으로 전달 가능한 인공신경망기계번역(Neural Machin Translation;NMT) 인공지능 학습모델 개발
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 방송콘텐츠(KBS 등) 라벨링 유형 번역(자연어) 라벨링 형식 JSON 데이터 활용 서비스 인공신경망기계번역(NMT) 데이터 구축년도/
데이터 구축량2022년/말뭉치 250만 문장 -
▪ 데이터 구축 규모
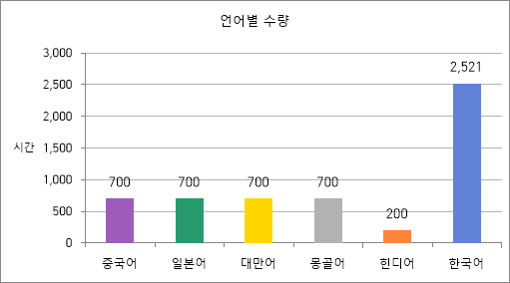
- 말뭉치데이터 250만 문장데이터 구축 규모 분류 북경어 일본어 대만어 몽골어 힌디어 합계 텍스트 데이터(문장) 900,513 701,426 701,426 100,000 100,000 2,503,365 ▪ 데이터 분포
- 언어별 분포 : 북경어, 일본어, 대만어, 몽골어, 힌디어
- 카테고리별 분포 : 연예/공연, 영화/드라마. 다큐멘터리. 오락/예능, 교양○ 1-11-036 방송콘텐츠 한국어-아시아어 번역 데이터
▪ 방송콘텐츠 카테고리 분포방송콘텐츠 카테고리 분포 항목명 측정지표 목표 성과 방송콘텐츠
카테고리분포구성비 중첩률 구성비 중첩률 50% 결과 구성비 목표 구성비 연예/공연 20% 연예/공연 21.20% 영화/드라마 20% 영화/드라마 24.20% 다큐멘터리 20% 다큐멘터리 19.40% 오락/예능 20% 오락/예능 16.60% 교양 20% 교양 18.70% 언어별 수량 수량 목표 수량(단위:문장) 결과 수량(단위:문장) 한국어→북경어 900,513 한국어→북경어 1,011,606 한국어→일본어 701,426 한국어→일본어 709,454 한국어→대만어 701,426 한국어→대만어 702,862 한국어→몽골어 100,000 한국어→몽골어 293,085 한국어→힌디어 100,000 한국어→힌디어 238,444 해외콘텐츠 수량 북경어→한국어 41,750 북경어→한국어 42,178 일본어→한국어 16,700 일본어→한국어 16,783 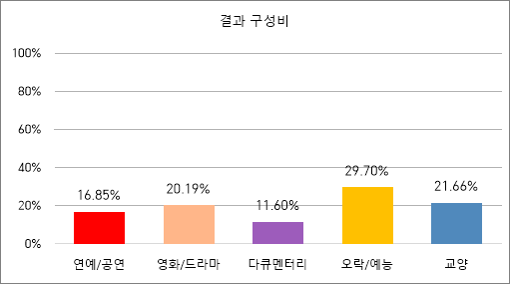
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드▪ 활용모델
가. 인공지능 학습용 데이터 활용모델 개발 방안
1) 구축 데이터 품질을 위한 방송콘텐츠용 한국어 음성인식 학습모델 선정, 개발
○ 방송콘텐츠용 한국어 음성인식 모델
- 본 과제를 통하여 구축된 3,000시간 이상의 ‘방송콘텐츠 한국어-아시아어 통번역 음성데이터’의 한국어 음성데이터 및 전사 텍스트데이터에 대한 데이터 품질 검토를 위하여 방송콘텐츠용 한국어 음성인식 학습모델을 선정함
○ 오픈소스 툴킷 이용한 방송콘텐츠용 한국어 음성인식 학습모델 구축
- 학습도구: 오픈소스툴인 ESPnet을 사용함
- 학습방식: ESPnet의 학습스크립트를 바탕으로 수정하여 사용함
○ 최신 종단형 방송콘텐츠용 한국어 음성인식 학습모델 학습
- 구축데이터의 80%에 해당하는 학습용 데이터셋과 10%에 해당하는 개발용 데이터셋을 이용하여 인공지능 음성인식 모델을 학습함
- 최신 알고리즘인 Transformer, Conformer 등 학습모델을 생성함
○ 방송콘텐츠용 한국어-아시아어 음성인식 학습모델 평가
- 구축데이터의 10%에 해당하는 평가용 데이터셋을 이용하여 학습된 인공지능 음성인식 모델을 평가함
- 한국어 음성인식 분야에서의 평가척도인 CER을 측정 및 목표성능 충족 여부를 판단함
- 목표 성능은 다음과 같음방송콘텐츠용 한국어-아시아어 음성인식 학습모델 평가 AI 모델 모델 성능 지표 Transformer, Conformer 등 한국어 음성인식 모델 CER 10 이하 2) 구축 데이터 품질을 위한 방송콘텐츠용 한국어-아시아어 자동통역 학습모델 선정, 개발
○ 방송콘텐츠용 한국어-아시아어 자동통역 모델
- 본 과제를 통하여 구축된 2,000시간 이상의 ‘방송콘텐츠 한국어-아시아어 통번역 음성데이터’의 한국어 음성데이터 및 번역 텍스트데이터에 대한 데이터 품질 검토를 위하여 방송콘텐츠용 한국어-아시아어 자동통역 학습모델을 선정함
○ 오픈소스 툴킷 이용한 방송콘텐츠용 한국어-아시아어 자동통역 학습모델 구축
- 학습도구: 오픈소스툴킷인 ESPnet을 사용함
- 학습방식: ESPnet의 학습스크립트를 바탕으로 수정하여 사용함
○ 최신 종단형 방송콘텐츠용 한국어-아시아어 자동통역 학습모델 학습
- 구축데이터의 80%에 해당하는 학습용 데이터셋과 10%에 해당하는 개발용 데이터셋을 이용하여 인공지능 자동통역 모델을 학습함
- 최신 알고리즘인 Transformer, Conformer 등 학습모델을 생성함
○ 방송콘텐츠용 한국어-아시아어 자동통역 학습모델 평가
- 구축데이터의 10%에 해당하는 평가용 데이터셋을 이용하여 학습된 인공지능 자동통역 모델을 평가함
- 자동통역 분야에서의 주요 평가척도인 BLEU를 측정 및 목표성능 충족 여부를 판단함
- 목표 성능은 다음과 같음방송콘텐츠용 한국어-아시아어 자동통역 학습모델 평가 AI 모델 모델 성능 지표 Transformer, Conformer 등 한국어-아시아어 자동통역 모델 중국어, 일본어 BLEU 20 이상 기타 BLEU 15 이상 나. 인공지능 모델을 적용한 기술혁신 지원 방안
1) 국가적 측면
○ 인공지능 기술의 국가 경쟁력 제고를 위하여 고품질의 통번역 데이터를 공유, 개방
- 인공지능 기술력의 선진국과의 격차 극복을 도모
- 개방적인 데이터 유통 과정으로 누구나 자유롭게 고품질의 데이터 활용할 수 있는 환경 조성
- 높은 자료의 접근성 및 연구의 다양성 확보를 통한 인공지능 기술력에 대한 국가경쟁력 제고 및 경제 성장 도모
○ 방송콘텐츠에 대한 디지털 산업 혁신 및 시장 확대를 위하여 데이터 활용 서비스 개발 가이드를 제공함
- 지속적인 선순환 체계 구축을 위한 데이터 활용 서비스 개발 가이드를 제공함
- ESPnet과 연계하여 연구, 개발할 수 있는 데이터 처리 가이드 제공
2) 연구, 개발적 측면
○ 한국어-아시아어 자동통역 학습모델 공개
- 주관기관 및 참여기관이 영위하는 유관 사업의 저작권, 영업권 등에 상충하지 않는 범위에서 한국어-아시아어 자동통역 학습모델 공개함
● 공개하는 한국어-아시아어 자동통역 학습모델은 ESPnet 툴킷에서 동작 가능함
● 품질 평가를 위해 사용되는 학습모델과는 다를 수 있음 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드▪ 데이터 포맷
데이터 포맷 콘텐츠명 생로병사의 비밀(816회) 카테고리 다큐멘터리 언어 일본어 발화시간 5.23초 성별 남 나이 50대 원문 20년 전을 보면 통념성이라고 해서 1년 내내 지속되면서 전처리 후 20年前を見ると、通念性といって、1年中に続いて。 ▪ 어노테이션 포맷 설명
"01_dataset" : {
"1_identifier" : "2022-1-11-036",
"2_name" : "방송콘텐츠 한국어-아시아어 번역 말뭉치",
"3_src_path" : "11-2/source/L01/C02/C00024/U00001.txt",
"4_label_path" : "11-2/labels/L01_L06/C02/C00024/U00001.json",
"5_category" : "C02",
"6_type" : "텍스트",
"7_copyright" : "Y"
},
"02_srcinfo" : {
"1_id" : "C00024",
"2_title" : "경찰수업_월화_O_210405_마이리틀폴리스_6화_완",
"3_language" : "한국어"
},
"04_contentinfo" : {
"4_storyline" : "술에 취해 나눈 강희와의 첫 키스를 기억하지 못하는 선호. 덕분에 둘 사이는 살벌해진다. 한편 학교는 곧 있을 청람체전으로 들썩인다. 우승 상품으로 걸린 특박권을 강희에게 따주고 싶은 선호와, 새로운 용의자를 찾아 미끼를 던지는 동만! 모든 것은 청람체전, 그날에 달렸다."
},
"05_speakerinfo" : {
"1_id" : "S097020",
"2_gender" : "남"
},
"06_ttsinfo" : [],
"07_text" : {
"1_text" : "근데 지금 몇 시지?"
},
"08_translation" : {
"1_text" : "Харин одоо цаг хэд болж байна вэ?",
"2_language" : "몽골어"
}
}
-
데이터셋 구축 담당자
수행기관(주관) : 아키아카
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 이동훈 070-5226-1346 [email protected] 사업 관리, 데이터 가공 수행기관(참여)
수행기관(참여) 기관명 담당업무 스피치랩스 데이터 설계 및 AI모델 개발 쿠버릭스 정제 및 가공 밍크엔터테인먼트 원천데이터 수집 이랜서 크라우드워커 채용 한국국가기록연구원 품질관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이동훈 070-5226-1346 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.