-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-29 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-19 산출물 전체 공개 소개
별도로 개발된 APP을 통해 2 사람이 다양한 주제에 대해 실시간 음성 통화를 하며, 해당 통화 내역을 텍스트로 전사함 각각의 음성은 감정 상태, 감정 유형, 감정 정도, 감정 대상 등으로 세분화된 감정 태깅을 수행함
구축목적
성인의 자유대화를 수집하되 대본이 없이 진행되는 일상 대화 음성 데이터를 구축 음성 데이터 전사 정보, 감정 상태 및 유형 정보 등이 태깅된 데이터 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 데이터 형식 wav 데이터 출처 자체 수집 라벨링 유형 자유대화음성(자연어) 라벨링 형식 JSON 데이터 활용 서비스 자연어처리 모델 개발, 대화형 인공지능 시스템 연구, 대화형 로봇/앱 개발, 가상의 아바타 응답 패턴 개발 등 데이터 구축년도/
데이터 구축량2022년/6,000시간 -
1. 데이터 구축 규모
- 총 3,000시간의 음성 데이터 구축데이터 구축 규모 구분 총 데이터수집 (건) 성인 데이터 수집 규모 3,000 시간 2. 성인 데이터 분포 (3,000시간)
- 대화 참여자 성별 분포 (성인)성인 데이터 분포 - 대화 참여자 성별 분포 (성인) 성별 인원(명) 비율(%) 남성 826 20.27% 여성 3,249 79.73% 합계 4,075 100% - 대화 참여자 연령대 분포 (성인)
성인 데이터 분포 - 대화 참여자 연령대 분포 (성인) 연령대 수량(명) 비율(%) 20대~30대 1,636 40.15% 40대 이상 2,439 59.85% 합계 4,075 100% - 대화 참여자 지역 분포 (성인)
성인 데이터 분포 - 대화 참여자 지역 분포 (성인) 연령대 수량(명) 비율(%) 서울/인천/경기 2,029 49.79% 대전/세종/충청/강원 1,609 39.48% 광주/전라/제주 107 2.63% 부산/대구/울산/경상 330 8.10% 합계 4,075 100% - 주제 분포: 교육/학문, 엔터테인먼트, 쇼핑, 게임 등 11개 주제 대분류 (성인)
성인 데이터 분포 - 주제 분포: 교육/학문, 엔터테인먼트, 쇼핑, 게임 등 11개 주제 대분류 (성인) 순서 주제 수량(건) 비율(%) 1 교육/학문 724 5.94% 2 엔터테인먼트 1,356 11.13% 3 쇼핑 1,156 9.49% 4 게임 269 2.21% 5 고민Q&A 1,331 10.93% 6 음식 1,894 15.55% 7 스포츠 192 1.58% 8 건강 1,140 9.36% 9 취미 1,842 15.12% 10 생활 1,606 13.18% 11 경제/사회 672 5.52% 합계 12,182 100% - 감정 상태 분포 (성인)
성인 데이터 분포 - 감정 상태 분포 (성인) 순서 주제 수량(건) 비율(%) 1 기쁨 1,397,414 38.13% 2 놀라움 481,440 13.14% 3 두려움 101,813 2.78% 4 사랑스러움 317,402 8.66% 5 슬픔 242,445 6.61% 화남 285,943 7.80% 6 없음 838,780 22.88% 합계 3,665,237 100% - 감정 유형 분포 (성인)
성인 데이터 분포 - 감정 유형 분포 (성인) 순서 주제 수량(건) 비율(%) 1 긍정 2,535,322 69.17% 2 부정 672,371 18.34% 3 중립 457,544 12.48% 합계 3,665,237 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. Transformer 기반의 엔진 활용
- 자체 엔진 개발 경험을 통해 End-to-End 방식의 STT 엔진을 선정2. AI 모델 선정 후보 간 비교
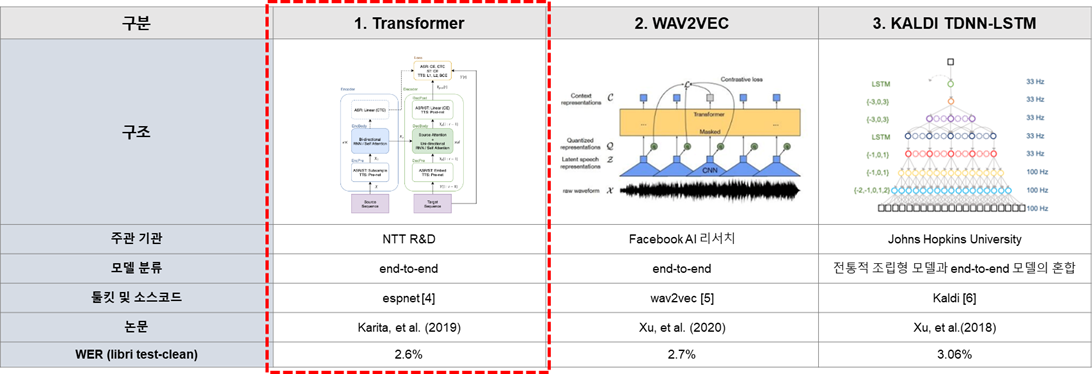

- 감정인식 알고리즘은 청소년, 성인 감정 태깅 대상 각각 100시간에 대한 유효성 검증용으로 도입 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 감정인식 Speech Recognition Convolutional Neural Network Accuracy 75 % 91.37 % 2 CER 성능지표 Speech Recognition Transformer CER 8 % 6.8 % 3 화자인식 Speech Recognition x-vector EER 8 % 3.174 % 4 WER 성능지표 Speech Recognition ESPnet WER 16 % 13.3 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터셋 구성
- 성인 3,000시간의 음성 데이터 구축
- 2사람의 대화를 각각 녹음한 음성 파일(16kHz, 16bit, mono)이 하나의 대화 파일로서 음성 파일을 구성(16kHz, 16bit, stereo)
- 2사람이 각각 30분씩 대화를 한 경우, 두 모노 파일을 합쳐서 총 대화 시간 30분 스테레오로 저장
- 텍스트 전사는 각각의 화자에 대해 개별 진행하고, 하나의 Json 파일에 메타 정보와 함께 기재
- 7개 감정 상태(기쁨, 놀라움, 두려움, 사랑스러움, 슬픔, 화남, 없음)로 구분하여 태깅
- 그 외 감정 정도(강함, 보통, 약함), 감정 대상(특정 인물/사물, 특정 사건, 대화 태도), 감정 종류(긍정, 중립, 부정) 등 감정과 관련된 태깅 정보를 기재
- 각 음성 파일 당 1개의 Json 파일이 존재하며, 메타정보와 모든 대화 텍스트를 저장함2. 데이터 분류 체계 정의
- 성인 자유대화 : 감정이 태깅된 성인 자유대화3. 데이터 출처
- 크라우드 워커를 모집하여 자유대화 직접 구축4. 라벨링 데이터 구성
라벨링 데이터 구성 구분 속성명 타입 필수여부 설명 범위 1 File Object 파일 정보 1-1 FileName String y 파일명 1-2 FileLength String y 파일 길이 1-3 BeginOfSpeech String y 발화 시작점 1-4 EndOfSpeech String y 발화 끝점 1-5 SpeechLength String y 발화 길이 (초) 2 Wav Object 원천데이터 정보 2-1 SamplingRate String y 주파수 2-2 NumberOfBit String y 비트수 2-3 EncodingLaw String y 인코딩방식 2-4 NumberOfChannel String y 채널수 3 Noise Object 소음 정보 3-1 Speaker1NoiseCategory String y 실내/실외 환경 종류 실내/실외 3-2 Speaker1NoiseType String n 녹음 장소 3-3 Speaker1SNR String n SNR 3-4 Speaker2NoiseCategory String y 실내/실외 환경 종류 실내/실외 3-5 Speaker2NoiseType String n 녹음 장소 3-6 Speaker2SNR String n SNR 4 Speaker1 Object 참여자 정보 4-1 ID String y 발화자 고유 번호 0001~9999 4-1 AgeCategory String y 성인 구분 성인 4-1 Age String y 연령 A1~A6 4-1 Gender String y 성별 G1/G2 4-1 Residence String n 거주지 4-1 Occupation String y 직업 4-1 Condition String n 목상태 4-1 Mask String n 마스크 착용 유/무 착용/미착용 4-1 RecDevice String n 녹음 장치 5 Speaker2 Object 참여자 정보 5-1 ID String y 발화자 고유 번호 0001~9999 5-2 AgeCategory String y 성인 구분 성인 5-3 Age String y 연령 A1~A6 5-4 Gender String y 성별 G1/G2 5-5 Residence String y 거주지 5-6 Occupation String y 직업 5-7 Condition String n 목상태 5-8 Mask String n 마스크 착용 유/무 착용/미착용 5-9 RecDevice String n 녹음 장치 6 ConversationInfo Object 대화정보 45078 Domain String y 대화 도메인 6-1 Step1Subject String y 대화 토픽 6-1 Step2Subject String y 대화 토픽 7 Conversation Object 대화내용 7-1 TextNo String y 대화 순서 번호 000001~999999 7-2 SpeakerNo String y 발화자 구분 Speaker1/Speaker2 7-3 SpeakerEmotionCategory String y 감정 유형 긍정/부정/중립 7-4 SpeakerEmotionTarget String y 감정 상태 기쁨/사랑스러움/두려움/화남/슬픔/놀라움/없음 7-5 SpeakerEmotionLevel String y 감정 정도 약함/보통/강함 7-6 SpeakerEmotionObject String y 감정 대상 2000-01-02 7-7 VerifyEmotionCategory String y 감정 유형 긍정/부정/중립 7-8 VerifyEmotionTarget String y 감정 상태 기쁨/사랑스러움/두려움/화남/슬픔/놀라움/없음 7-9 VerifyEmotionLevel String y 감정 정도 약함/보통/강함 7-10 VerifyEmotionObject String y 감정 대상 2000-01-02 7-11 Text String y Text 전사내용 7-12 StartTime String y 대화 시작시간 7-13 EndTime String y 대화 끝 시간 -
데이터셋 구축 담당자
수행기관(주관) : 미디어젠
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 송민규 02-6429-7104 [email protected] 설계 분석 및 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 비디 시스템 구축 메트릭스 크라우드소싱 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 송민규 02-6429-7104 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.