-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-10-30 데이터 최종 개방 1.0 2024-07-05 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-07-05 산출물 공개 Beta Version 소개
- 저작권 문제를 해결한 방송 콘텐츠를 음성인식 기술을 활용하여 하이라이트 검색이 가능한 학습용 데이터 - 전체 영상 중 음성 발화가 70% 이상 포함되어 있는 방송 콘텐츠 3,000시간 이상(각 5분 이상, 총 4천 건 이상) 신규 구축 - 검색을 위한 질의어(음성 및 전사) 약 20만 건 및 질의에 상응하는 하이라이트 영상 구간 및 구간의 분류에 대한 라벨링
구축목적
- 최근 ChatGPT등 초거대AI 등장에 따라 환경변화에 국가적 차원의 선제적인 대응 필요 - 국내 기업·기관 등의 인공지능 학습용 데이터 구축은 많은 시간과 비용이 소요되기에 인공지능 도입·개발에 진입장벽으로 작용되기에 국가적 차원의 고품질·대규모 인공지능 학습 데이터 구축 지원 필요 - 인공지능 생태계 조성 및 일상생활 곳곳으로 확산하기 위해 다양한 분야의 대규모 학습용 데이터 수집·공유 필요
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 비디오 데이터 형식 mp4 데이터 출처 방송국 (TBS, EBS) 라벨링 유형 전사, 키워드 추출, 태깅 라벨링 형식 JSON 데이터 활용 서비스 인공지능(AI) 면접, 화상 미팅의 활성화, 공공 및 민간 서비스의 AI 고객상담용 챗봇, 스마트 스피커 데이터 구축년도/
데이터 구축량2023년/원천데이터 5,958건 / 라벨링데이터 5,958건 -
- 데이터 구축 규모
음성 발화가 70% 이상 포함되어 있는 방송 콘텐츠 3천 시간 이상(각 5분 이상, 총 4천 건 이상) 데이터 구축데이터 구축 규모 구분 구축 시간 구축 건수 교양 454.8499 888 뉴스 485.4187 1,224 다큐 391.2883 715 문화 301.6747 378 생활 300.6682 408 시사 300.6968 411 여행 465.2676 1,428 예능 305.2821 506 합계 3,005.15 5,958 - 데이터 분포
데이터 분포 구분 비율(%) 방송 콘텐츠별 최소 시간 6.69분 방송 콘텐츠 총 구축 시간 3,005시간 방송 콘텐츠 총 구축 수 5,958건 콘텐츠 대비 음성 발화 시간 70% 이상 카테고리별 분포 교양 15.14% 뉴스 16.15% 다큐 13.02% 문화 10.04% 생활 10.01% 시사 10.01% 여행 15.48% 예능 10.16% 질의 문장 수 210,817건 카테고리별 분포(요약) 카테고리별 분포(요약) category SUM 결과 구성비 목표 구성비 교양 454.8499 15.14% 15.00% 뉴스 485.4187 16.15% 15.00% 다큐 391.2883 13.02% 15.00% 문화 301.6747 10.04% 10.00% 생활 300.6682 10.01% 10.00% 시사 300.6968 10.01% 10.00% 여행 465.2676 15.48% 15.00% 예능 305.2821 10.16% 10.00% 합계 3,005.15 100.00% 100.00% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 음성인식 학습모델
질의 쿼리를 음성인식으로 인식하기 위해 질의어 음성인식 학습을 위해 검증용 말뭉치와 시험용 말뭉치를 전체 말뭉치의 10%로 제시한다.음성인식 학습모델 학습 검증 시험 개요 질의어 음성 학습 시 모델 성과 평가 및 비교 모델 학습 완료 후 테스트 CER, WER 필요문장 80% 10% 10% 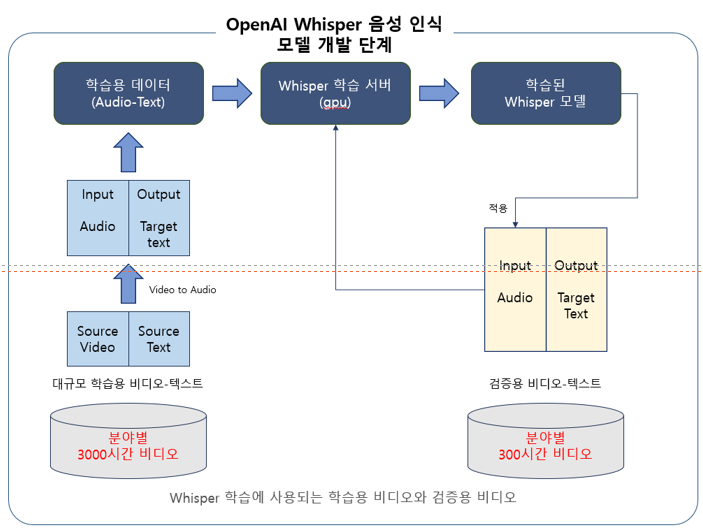
서비스 활용 시나리오
○ 구축한 모델은 동영상 하이라이트 음성 검색에 사용할 수 있음.
○ 유사한 음성으로 질의 쿼리를 이용한 모든 검색에 사요할 수 있음- 하이라이트 요약 텍스트 검색 모델학습
영상요약 텍스트 기반 검색 엔진 학습을 위해 검증용 말뭉치와 시험용 말뭉치를 전체 말뭉치의 10%로 제시한다.하이라이트 요약 텍스트 검색 모델학습 학습 검증 시험 개요 영상 스크립트 요약 내용 학습 시 모델 성과 평가 및 비교 모델 학습 완료 후 테스트 F1-score 필요문장 80% 10% 10% 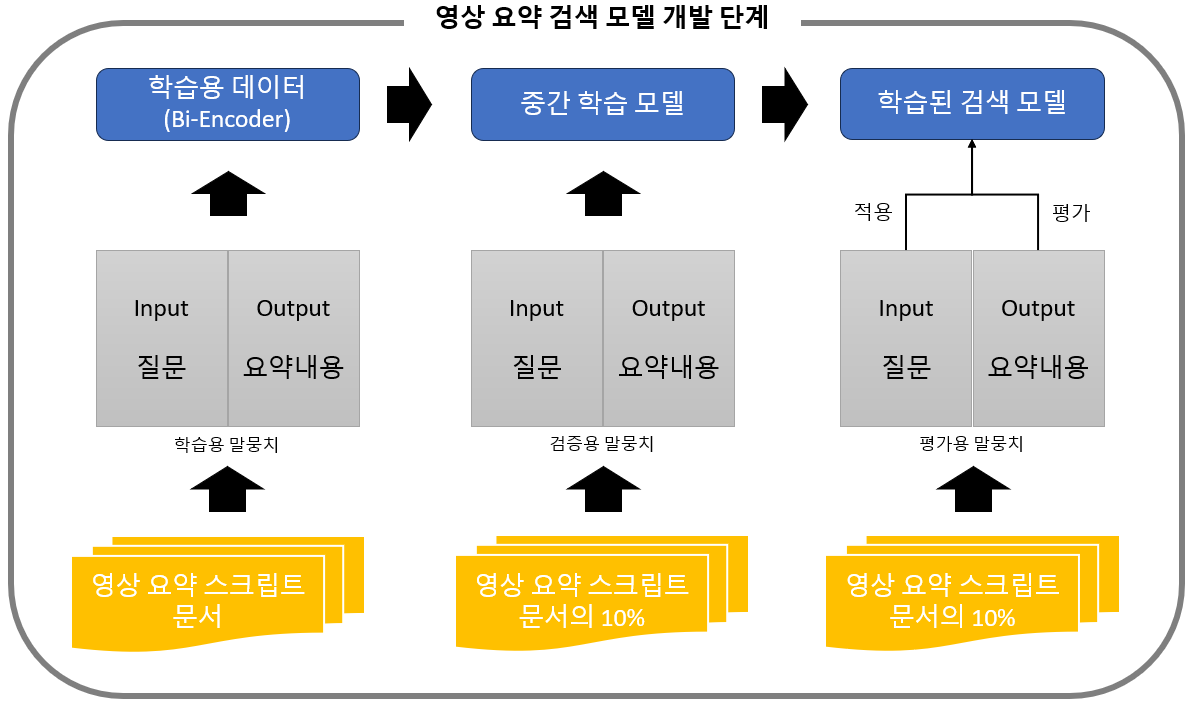
서비스 활용 시나리오
○ 구축한 모델은 QA업무에 활용할 수 있음.
○ QA 업무 활용- 데이터 수요자가 QA 서비스 제공회사라면 학습한 검색 엔진을 통해 문서내의 답변을 찾는 업무에 적용할 수 있음. -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 어노테이션 포맷
어노테이션 포맷 구분 속성명 타입 필수 여부 설명 범위 1 dataset object Y AI 학습데이터 파일 데이터셋 정보 1-1 title string Y AI 학습데이터 파일명 카테고리.구축년도.일련번호 1-2 creator string Y 구축자 솔트룩스 1-3 distributor string Y 배포자 솔트룩스 1-4 year string Y 구축년도 2023 2 typeInfo object Y 비디오 데이터 상세 정보 2-1 publisher string Y 제작사 EBS TBS 2-2 category string Y 카테고리 교양 뉴스 다큐 문화 생활 시사 여행 예능 2-3 length number Y 비디오 데이터 길이 소수점 3자리 2-4 resolution string Y 비디오 해상도 1280X720 2-5 speaker_number number Y 총 발화자 수 1,2,3~ 3 speakers array Y 발화자 상세 정보 (object) 3-1 speaker_id number Y 발화자 아이디 1,2,3~ 3-2 gender string Y 발화자 성별 남,여,알 수 없음 3-3 age string Y 발화자 연령대 10대 20대 30대 40대 50대 60대 이상 알 수 없음 4 transcript array (object) Y 전사 데이터 목록 4-1 speaker_id number Y 발화자 아이디 1,2,3~ 4-2 dialog_id number Y 발화 문장 순서 0,1,2,3~ 4-3 start number Y 발화 시작 시간 소수점 3자리 4-4 end number Y 발화 끝 시간 소수점 3자리 4-5 form string Y 발화 내용 전사 텍스트 5 highlight array (object) Y 하이라이트 구간 매핑 정보 5-1 id string Y 하이라이트 구간 아이디 파일명.일련번호 5-2 start_time number Y 하이라이트 구간 시작 시간 소수점 3자리 5-3 end_time number Y 하이라이트 구간 끝 시간 소수점 3자리 5-4 classification object Y 하이라이트 구간 분류 5-4-1 location array (string) Y 장소 분류 정보 *장소 분류 정보표 참고(아래) 5-4-2 action array (string) Y 행동 분류 정보 *행동 분류 정보표 참고(아래) 5-4-3 relation array (string) Y 관계 분류 정보 *관계 분류 정보표 참고(아래) 5-4-4 emotion array (string) Y 감정 분류 정보 *감정 분류 정보표 참고(아래) 5-5 keywords string Y 하이라이트 구간 키워드 5-6 summary string Y 하이라이트 구간 요약 5-7 user_query array (object) Y 하이라이트 구간 사용자 쿼리 정보 5-7-1 query_id string Y 사용자 쿼리 아이디 5-7-2 query string Y 사용자 쿼리 내용 * 장소 분류 정보(location)
장소 분류 정보(location) 교육시설 음식점 자연 경관 인공조성환경 거주시설 숙박시설 종교/의료시설 공공시설 교통/이동수단 상업시설 문화재 및 유적지 스포츠 관람 및 레저시설 오락시설 공연시설 행사/사무공간 건물 내부시설 도심 환경 도로 및 교통시설 예술/전시공간 산업시설 알 수 없음 * 행동 분류 정보(action)
행동 분류 정보(action) 음식을 먹거나 마시는 행동 스포츠, 여가, 반려동물과
관련된 행동일상적인 움직임 중 감각 기관과
관련된 행동일상적인 움직임 중 이동과
관련된 행동일상적인 움직임 중 기타 행동 신체 관리와 관련된 행동 업무, 사회생활 및 네트워킹과
관련된 행동알 수 없음 * 관계 분류 정보(relation)
관계 분류 정보(relation) 사회 속 관계 - 서로 아는 사이 사회 속 관계 - 유명인과 일반인 사회 속 관계 - 유명인과 유명인 사회 속 관계- 모르는 사이 가족 관계 - 부부 관계 가족 관계 - 부모 자식 관계 가족 관계 - 형제 자매 가족 관계 - 기타 친인척 친구/적 관계 - 친구 관계 친구/적 관계 - 적대 관계 친구/적 관계 - 연인 관계 직장 내 관계 - 친한 동료 직장 내 관계 - 친하지 않은 동료 알 수 없음 * 감정 분류 정보(emotion)
감정 분류 정보(emotion) 긍정 부정 중립 알 수 없음 - 데이터 예시
- 원천데이터(mp4)
- 라벨링데이터(json)


-
데이터셋 구축 담당자
수행기관(주관) : ㈜솔트룩스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김영혁 02-2193-1682 [email protected] 사업총괄, 데이터 수집, 학습모델 개발 수행기관(참여)
수행기관(참여) 기관명 담당업무 배재대학교 산학협력단 데이터 설계 및 품질 자문 ㈜비투엔 데이터 품질 검사 전담 ㈜팀벨 데이터 정제, 가공 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김민종 02-2193-1682 [email protected] 김영혁 02-2193-1682 [email protected] AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 이영원 02-2193-1682 [email protected] 박상민 02-2193-1682 [email protected] 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 최혜연 070-5090-7968 [email protected] 김보람 070-5086-7394 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.