-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-10-30 데이터 최종 개방 1.0 2024-06-28 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-28 산출물 공개 Beta Version 소개
- 아파트 주거환경에서 화초, 관상수를 건생/중생/습생 3가지 카테고리 별로 거실과 베란다에 건조, 일반, 과습의 다양한 형태의 물주기를 하여 수집한 90종의 이미지(JPG) / 메타데이터(JSON) 각 495,359건의 데이터
구축목적
- 인공지능 학습을 위한 최적의 원예식물 수분공급 주기 생육데이터 셋을 구축하여, 일반 가정환경 내의 화분에서 최적의 물주기 추천 시스템에 이용될 수 있는 데이터를 구축하고 스마트 식물 재배 산업의 AI 생태 환경을 고도화하고자 함
-
메타데이터 구조표 데이터 영역 농축수산 데이터 유형 센서 , 이미지 데이터 형식 jpg 데이터 출처 자체 수집 라벨링 유형 폴리곤데이터(이미지)/이미지캡셔닝(이미지) 라벨링 형식 json 데이터 활용 서비스 일상생활 속 홈 기반 스마트 식물 재배 시스템을 통한 식물 상태에 따른 자동화된 물주기 최적화 추천, 원격지에서도 식물의 상태를 감시 및 데이터 클라우드 서버 저장, 자동화된 식물의 지속적 관리, AI를 활용한 생육 예측 데이터 구축년도/
데이터 구축량2023년/원예식물 이미지 데이터(원시데이터) : 495359건, 원예식물 이미지(잎, 뿌리 등) 및 센서 데이터에 라벨링된 데이터 495359건 -
- 데이터 구축 규모
• 원예식물 이미지 데이터 (원시데이터) : 495,359장
• 원예식물 이미지(잎, 뿌리 등) 및 센서 데이터에 라벨링된 데이터 495,359건- 데이터 분포
• 각 실물별 30,000장 이상의 데이터 수집
• 모든 식물의 데이터의 분포를 고르게 수집
• 건생식물/중생식물/습생식물 카테고리 별로 최소 식물 1종 이상 포함
• 수분 공급 전·후 잎 상태 파악을 위한 작물별 특성에 따른 자동 관수 시스템 적용
• 식물 15종을 베란다와 거실에서 작물마다 물주기를 다르게 하여(건조/일반/과습) 수집데이터 분포 PlantName COUNT 결과 구성비 몬스테라 30,371 6.1% 보스턴고사리 31,828 6.4% 홍콩야자 35,240 7.1% 스파티필럼 31,696 6.4% 테이블야자 34,367 6.9% 호접란 31,080 6.3% 부레옥잠 30,584 6.2% 선인장 34,950 7.1% 스투키 32,452 6.6% 금전수 35,110 7.1% 벵갈고무나무 33,791 6.8% 디펜바키아 30,317 6.1% 관음죽 34,451 7.0% 오렌지쟈스민 35,003 7.1% 올리브나무 34,119 6.9% 합계 495,359 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 이미지 분류 학습 모델
PolyNet이라는 신경망 모델을 사용하여 복잡한 이미지 분류 작업을 수행함. 이 모델은 InceptionResNetV2 아키텍처를 기반으로 하면서도, 다양한 크기의 컨볼루션 필터를 사용하는 PolyInception 모듈을 추가하여 구성된 모델임. 이 모델은 이미지의 다양한 특성을 포괄적으로 파악하여 분류의 정확도를 높이는 것이 특징임. 학습을 위해 검증용 이미지와 시험용 이미지를 모두 전체 이미지의 10%로 제시하며, 본 사업에서는 전체 데이터를 40만 이상 구축하므로 최소 검증과 시험을 모두 각 4만 이미지 이상으로 통일하여 준비하는 것을 제안함.이미지 분류 학습 모델 학습(Learning) 검증(Validation) 시험(Test) 개요 InceptionResNetV2 기반 PolyInception 모듈 추가 학습 도중 모델 평가 및 비교 F1-Score, accuracy 등 모델 학습 완료 후 모델 테스트 필요 데이터 많을수록 좋음(십만 단위) 10% (최대 5만 문장) 10% (최대 5만 문장) ▫ 데이터 준비 및 전처리 과정
데이터 준비 과정에서는 이미지 파일의 경로를 수집하고, 라벨을 수집하여 데이터 프레임 구성함. 라벨은 LabelEncoder를 통해 정수로 인코딩한 후, to_categorical 함수로 원-핫 인코딩을 적용함. 전처리 단계에서는 이미지를 모델에 맞는 크기로 조정하고, 픽셀 값을 [0, 1] 범위로 정규화함. 데이터 증강은 ImageDataGenerator를 사용하여 수행했으며, 이를 통해 모델의 일반화 능력을 향상시키고 과적합을 방지함.
▫ 학습 알고리즘에 대한 설명
모델은 Adam 최적화 알고리즘을 사용하여 컴파일됨. 이는 효율적인 학습률 조정을 가능하게 하여 다양한 크기의 데이터셋에서 효과적인 성능을 발휘함. 손실 함수로는 다중 클래스 분류에 적합한 categorical_crossentropy가 사용되며, 정확도(accuracy)를 메인 평가 지표로 사용하여 모델의 성능을 평가함.
▫ 데이터 학습 진행 과정
fit 함수를 사용하여 모델에 데이터를 공급하고 학습을 진행함. EralyStopping과 CustomCallback, CustomMetricsCallback을 사용하여 모델의 학습 진행 상황을 모니터링하고, 정확도가 90%를 넘었을 경우 종료하도록 설정함. 학습 과정은 각 에포크마다의 손실 값과 정확도를 기록하면서 진행됨.
▫ 모델 학습 결과 및 결과 확인 방법
학습이 완료되면, 모델은 .h5 파일 형식으로 지정된 경로에 저장되며, 저장된 모델은 나중에 불러와 추가 평가나 예측을 수행할 수 있음. 검증 데이터셋을 사용하여 모델의 성능을 평가하고, 정확도와 F1 Score를 통해 모델의 성능을 객관적으로 측정함.▫ 모델 학습 결과 확인
테스트 데이터셋에 대한 예측을 수행하여 모델의 최종 성능을 평가함. 예측 결과를 바탕으로 classification_report와 confusion_matrix를 생성하여 모델의 성능을 상세하게 분석하고, 이를 엑셀 파일로 저장하여 결과를 문서화함. 이 과정을 통해 모델의 강점과 약점을 파악하고, 향후 개선 방향을 설정할 수 있음.
전체적인 프로세스를 정리하면 다음과 같은 이미지로 정리할 수 있다.
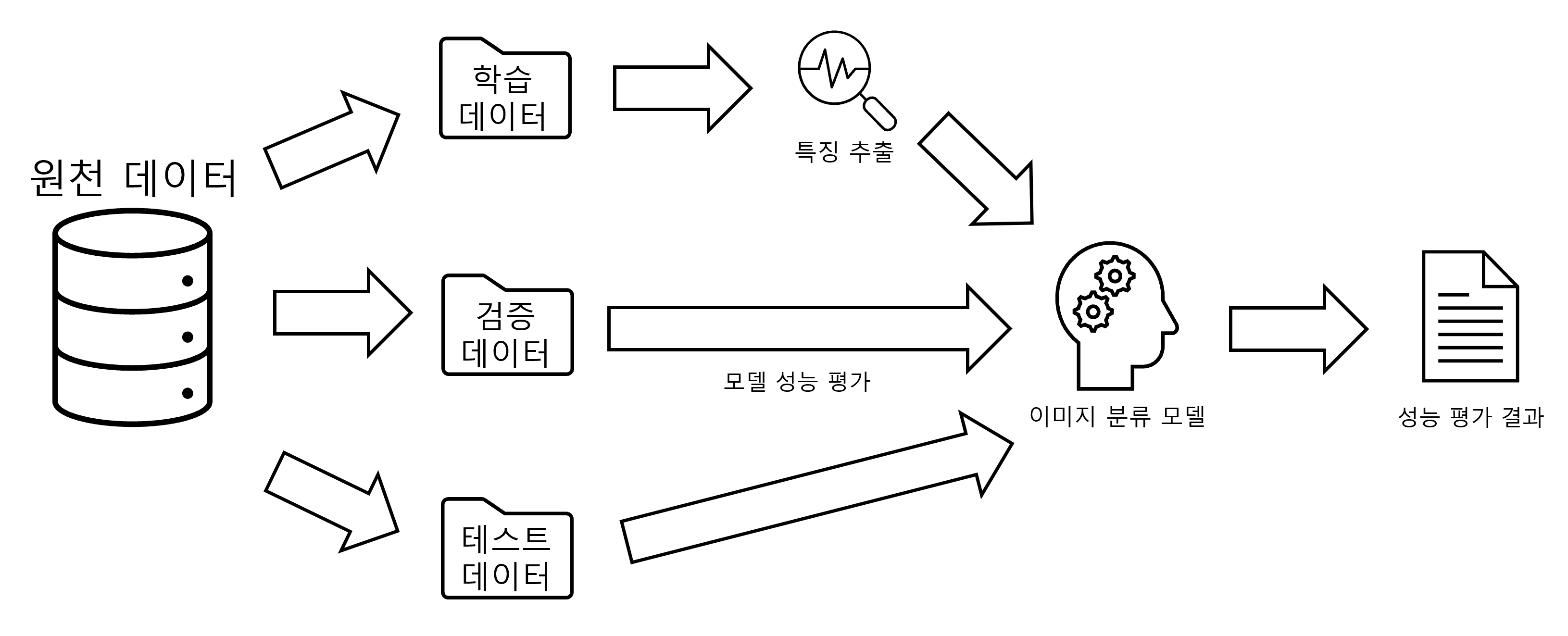
이러한 프로세스를 통해 이미지 분류 과정을 수행한다.
- 생장예측 학습 모델
▫ 데이터가공
식물생장예측 모델을 만들기 위해 사용한 데이터는 각 원예식물 15종을 2023년 8월 24일부터 2023년 10월 22일까지 베란다와 거실 두 곳에 배치를 해서 , 관수를 각각 건조, 일반, 과습 이렇게 3종류로 나뉘게 관수를 함으로써, 총 90개의 화분을 분류하여 식물의 생장에 필요한 요소들을 관측함, 여기서 관측한 값들은 이후에 식물생장예측 모델을 제작하는데 필요한 학습데이터가 된다.
- 데이터 가공 사용 컬럼데이터 가공 사용 컬럼 컬럼 설명 AirTemperature 대기온도 AirHumidity 대기습도 Quantum 대기광양자 HighSoilHumi 상층지습 HighEC 상층EC HighPH 상층PH LowSoilHumi 하층지습 LowSoilEC 하층EC LowSoilPH 하층PH AmtIrrigation 관수량 생장예측 모델에서는 줄기의 길이(PlantHeight)를 종속변수로 두어서진행을 하게 된다. 데이터 가공의 목표가 되는 데이터의 형태는 데이터 안의 시간데이터를 기준으로, 각 화분마다 일주일씩 나눠서 위의 요소들의 "평균", "최대", "최소", "최대와 최소의 차", "표준편차" 이렇게 5개를 계산한 값들을 열로 갖는 형태이다.
- 데이터 가공 예시
데이터 가공 예시 AirTemperature_mean AirTemperature_max AirTemperature_min AirTemperature_diff ..... AmtIrrigation_std A-1-01-V-w1 30 40 10 30 ..... 0.78 A-1-01-V-w2 31 40 10 30 ..... 0.78 A-1-01-V-w3 32 40 10 30 ..... 0.78 데이터 전처리 과정은 크게 , "그룹핑" , "계산" , "병합" 순으로 진행이 된다.
- 그룹핑
그룹핑은 90개의 화분을 구분하는 속성인 "ClassID"별로 데이터를 나누는 과정이다 여기에서 각 화분별로 필터링이 된 데이터가 90개 생성이 된다. 그리고 여기에서 추가적인 처리가 필요한데 , 식물 데이터 수집 중 중간에 괴사한 식물들도 있기 때문에 추가적인 처리로 ClassID 뒤에 'r'을 붙여서 총 109개의 화분이 최종적으로 생성된다.- 계산
계산에서는, 시간 데이터를 기준으로 일주일씩 나눈다. 식물생장 데이터에서는 총 9주의 데이터가 한 화분에서 나오게 된다 , 일주일씩 묶어서 각 평균, 최대, 최소, 최대와 최소의 차, 그리고 표준편차를 요소별로 계산을 한다.- 병합
마지막으로, 모든 데이터를 행 방향으로 붙이면 각 화분단 9주씩 묶인 데이터가 행단위로 연결이 되어 가공형태의 데이터프레임이 나오게 된다.그 외에는 범주형 변수들이 있다, 화분이 배치장소(locate), 관수상태(water), 식물종(ClassType), 식물 이름(ClassNo)이 있다.
종속변수로 사용이 될 , PlantHeight가 전 주에 비해서 어느정도 성장했는지를 보는 척도로 , 이전 주의 PlantHeight를 가져오는 열인 PlantHeight_ago를 추가를 해서 전 주와의 비교도 가능하게 한다.
▫ 모델 설명
사용 모델 : RandomForestRegressor
사용한 학습모델 랜덤포레스트 모델이다. 과대적합을 방지하기 위해서 최적의 기준변수를 랜덤하게 선택하는 머신러닝 기법이다.
여러개의 의사결정나무를 조합한 모델인데, 이 모델은 여러개의 의사결정나무를 조합하기 때문에 앙상블(ensemble) 모델이며, 집단 지성과 비슷한 원리로 움직인다.
식물생장예측의 경우, 각 화분별로 데이터가 정리되어있기 때문에 , 사용되는 모든 특성이 식물에 영향을 미칠 때, 유기적으로 결합된 영향을 지니고 있다, 여기에서 선형회귀 모델을 사용할 경우, 각 특성을 가중치와 곱한 후 더하는 방식으로 예측을 하기 때문에 사용되는 특성들의 관계성을 반영하기 힘들 수도 있다.
랜덤포레스트 모델은 여러 특성들의 관계성을 반영한 값을 여러개 만들어 내서, 그 값들을 통해 최종적인 결론을 내리게 되므로 랜덤포레스트 모델이 더 적절하다고 생각하여 선정하였다.▫ 원리 설명
Bagging방식을 통해서 움직이는데, Bagging은 Bootstraping과 Aggregating을 합친 말이다.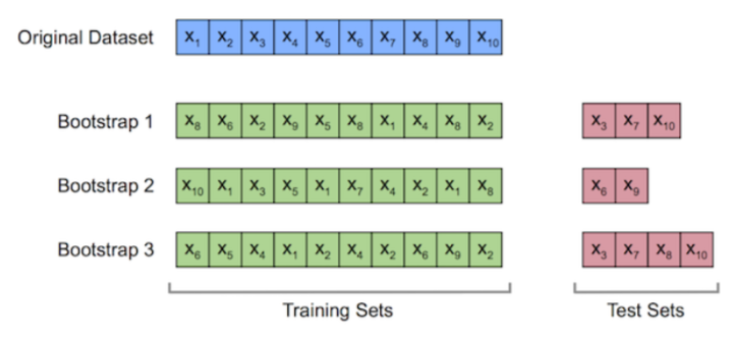
Bootstraping
Bootstraping은 샘플링의 일종으로, "복원추출"을 한다는 특징을 가지고 있다 , 여기에서 위의 사진과 같이 하나의 샘플에 같은 데이터가 들어가 있는 것처럼, 샘플을 모두 다 다르게 생성할 수 있다.
이렇게 해서 여러개의 의사결정나무를 만들고 마지막에 Aggregating을 한다. Aggregating을 할 때, 모델이 회귀문제에 쓰이는지 분류 문제에 쓰이는지에 따라서 결정방법이 달라지게 된다.
회귀문제 : 평균을 계산하여 , 결정한다.
분류문제 : 다수결을 따른다.▫ 학습과정
식물생장예측 모델의 학습과정은 전체적으로 아래와 같은 방식으로 이루어진다.
- 데이터 분할
- 모델 학습
- 모델 튜닝
- 평가▫ 데이터분할
모델 학습을 진행하기 전에, 데이터를 학습데이터, 테스트데이터, 검증데이터로 나누어야 한다.
먼저 , 무작위로 데이터의 ClassID를 9개씩 추출을 한다. 그리고 같은 ClassID도 , 화분의 배치장소와 , 관수 상태로 구분이 되기에 베란다 2종류와 관수상태 3종류 총 6종류의 아이디를 ClassID와 결합시켜서 하나의 화분에 대한 ClassID를 만들어야 한다.
여기에서는, 6종류의 아이디에 대해서 위에서 사용한 방법과 동일하게 하나를 무작위로 추출하는 방법으로 한다.▫ 모델 학습
지금까지 나눈 데이터로, 학습데이터, 테스트데이터, 검증데이터 이렇게 3가지 데이터가 결과적으로 나오게 되었다. 이제 세가지 데이터와 각 데이터의 종속변수(PlantHeight)를 토대로 모델을 학습시킨다.▫ 모델 튜닝
각 모델에는 외부에서 직접 값을 조정할 수 있는, 외부 구성 변수가 있는데, 여기서 설정된 값들은 모델의 학습에 영향을 미치며, 성능을 높일 수도 있고 성능이 낮아질 수도 있다. 그리고 그 수의 조합이 많기 때문에 이것을 자동화 시켜서 성능을 높일 수 있는 변수들의 조합을 찾는 과정이다.▫ 사용 기법 : GridSearchCV
그리드서치는 모델을 튜닝하는 과정에서 쓰이는 기법중의 하나이고 가장 직관적인 방법인데, 변수의 값이 될 수 있는 수들의 범위를 사용자가 지정을 해주면, 그 범위의 값들을 조합해서 모델의 성능이 최적이 되는 값을 찾아주는 방법이다.
사용하기 간편하며, 결과물도 괜찮지만, 시간이 많이 걸린다는 단점이 있다.모델 튜닝에서 사용한 변수들을 나열하자면
- n_estimators
- max_depth
- min_samples_split
- min_samples_leaf각 값들의 의미는
- 랜덤포레스트를 구성하는 결정 트리의 개수
- 각 결정 트리의 최대 깊이
- 노드를 분할하기 위한 최소한의 샘플 수
- 리프 노드가 가져야 하는 최소한의 샘플 수위의 데이터 분할, 모델 학습, 모델 튜닝 이러한 작업을 30번 반복을 시키면서 우연이나 랜덤성에 의해서 평가가 달라지는 것을 파악하면서 일반적인 성능을 파악할 수 있도록 한다.
▫ 평가
모델 평가의 척도로는 MAPE(Mean Absolute Percentage Error)을 사용한다. 값이 작을 수록 좋으며, 특징으로는 값이 모두 0~100% 사이의 값을 가지기 때문에 결과 해석에 용이하다는 특징이 있다.

MAPE 결과값(최소 , 최대 , 평균)
모델 평가의 결과를 보면 0~100%의 값을 가지는데 평균이 4% 가장 큰 값도 7%로 매우 양호한 성능을 가지고 있다는 것을 알 수 있다.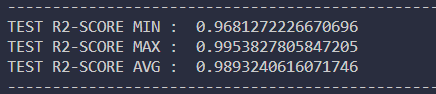
결정계수 결과값(최소 , 최대 , 평균)
결정계수란 , 모델이 종속변수를 얼마나 잘 설명하느냐를 보여주는 계수인데 , 이 값은 1로 갈 수록 높은 값을 가지며 , 믿을 만 하다는 것이기 문에 , 해당 모델은 결정계수 측면에서도 양호한 성능을 가지고 있다는 것을 판단할 수 있다.
이렇게 전체적인 과정을 정리하면 ,
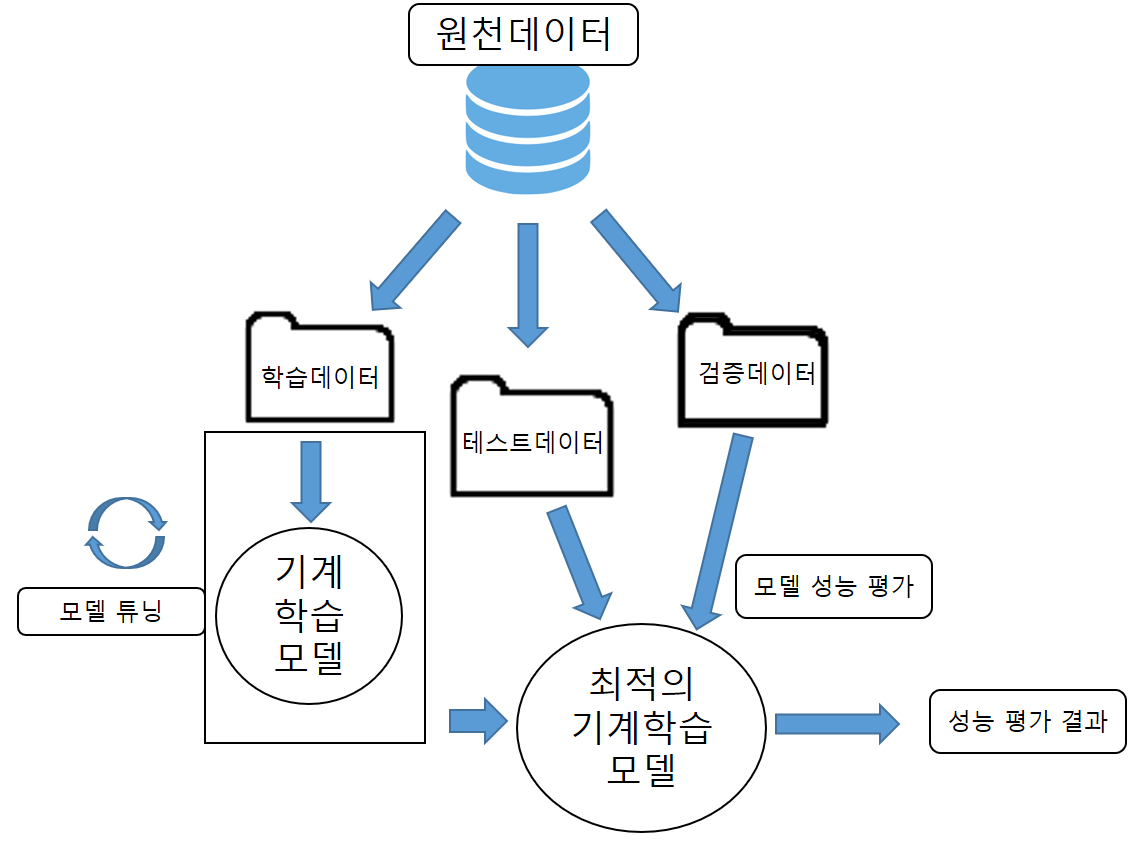
모델 학습 프로세스
이러한 프로세스를 통해서 데이터의 분할부터 평가까지 이루어진다고 정리할 수 있다.
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성
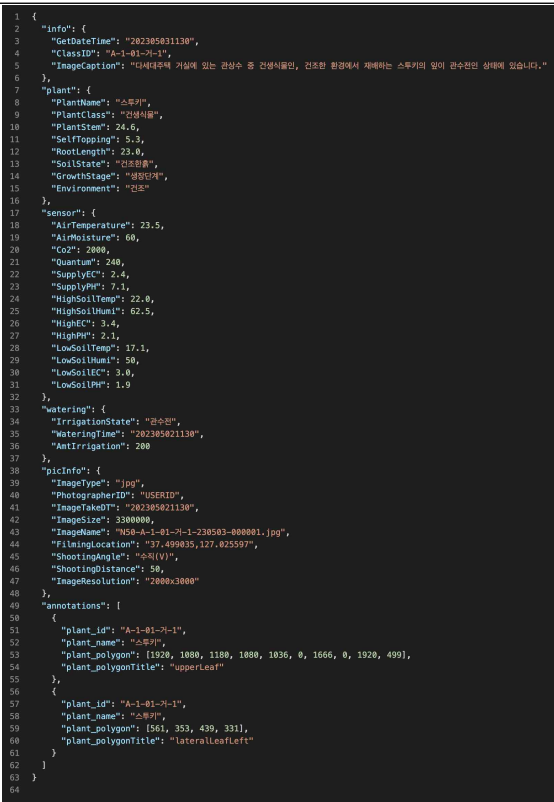
데이터 구성 Key Description Type Child Type info 기본정보 JsonObject GetDateTime 수집시간 String ClassID 클래스 ID String Place 수집장소 String ImageCaption 이미지 캡션 String 한글명 ResultOfGrowthLevel 생장결과 String plant 작물정보 JsonObject PlantName 식물명 String 한글명 PlantClass 식물 종류 String 한글명 PlantHeight 식물 길이 누적 정보 Array {} Object date 측정날짜 String height 측정길이 String PlantThickness 줄기 두께 누적 정보 Array {} Object date 측정날짜 String thickness 측정길이 String SelfTopping 화방 String RootLength 식물 뿌리 정보 Object plant 심을 때 뿌리 길이 String uproot 뽑았을 때 뿌리 길이 String SoilState 흙 상태 String 한글명 GrowthStage 생장 상태 String 한글명 Environment 재배 환경 String 한글명 sensor 센서정보 JsonObject AirTemperature 기온 String AirHumidity 습도 String Co2 대기 CO₂농도 String Quantum 일사량 String SupplyEC 공급 영양분 농도 String SupplyPH 공급 산성도 String HighSoilTemp 화분 흙 상단 온도 String HighSoilHumi 화분 흙 상단 습도 String HighEC 화분 흙 상단 영양분 농도 String HighPH 화분 흙 상단 산성도 String LowSoilTemp 화분 흙 하단 온도 String LowSoilHumi 화분 흙 하단 습도 String LowSoilEC 화분 흙 하단 영양분 농도 String LowSoilPH 화분 흙 하단 산성도 String watering 관수정보 JsonObject IrrigationState 관수 상태 String 한글명 WateringTime 관수 시간 String AmtIrrigation 관수량 String picInfo 사진정보 JsonObject ImageType 사진 포맷 String PhotographerID 사진작가 ID String ImageTakeDT 촬영 시간 String ImageSize 사진 크기 String ImageName 사진명 String FilmingLocation 촬영 위치 String ShootingAngle 촬영 각도 String 한글명 ShootingDistance 촬영 거리 String ImageResolution 해상도 String annotations 폴리곤 어노테이션 정보 Array plant_id 식물 클래스 ID String plant_name 식물명 String plant_polygon 폴리곤 위치 정보 array int plant_polygonTitle 폴리곤 잎 정보 String - 어노테이션 포맷
어노테이션 포맷 구분 속성명 타입 필수여부 설명 범위 비고 1 info 기본정보 1-1 GetDateTime String Y 수집시간 1-2 ClassID String Y 클래스 ID A-1-01-L-1 1-3 Place String Y 수집장소 베란다(B)/거실(L) 1-4 ImageCaption String 이미지 캡션 1-5 ResultOfGrowthLevel String Y 생장결과 High/Medium/Low/DIE 2 plant 작물정보 2-1 PlantName String Y 식물명 15종 참고 2-2 PlantClass String Y 식물 종류 건생식물/중생식물/습생식물/수생식물 2-3 PlantHeight Array 식물 길이 누적 정보 {} Object date String 측정날짜 height String 측정길이 cm 2-4 PlantThickness Array 줄기 두께 누적 정보 cm {} Object date String 측정날짜 thickness String 측정길이 cm 2-5 SelfTopping String 화방 개 2-6 RootLength Object Y 식물 뿌리 정보 plant String 심을 때 뿌리 길이 cm uproot String 뽑았을 때 뿌리 길이 cm 2-7 SoilState String Y 흙 상태 건조한흙/습한흙/일반흙 2-8 GrowthStage String Y 생장 상태 생장단계/개화단계 2-9 Environment String Y 재배 환경 건조/일반/과습 3 sensor 센서정보 3-1 AirTemperature String Y 기온 °C 3-2 AirHumidity String Y 습도 % 3-3 Co2 String Y 대기 CO₂농도 ppm 3-4 Quantum String Y 일사량 umol/m2/s 3-5 SupplyEC String Y 공급 영양분 농도 dS/m 3-6 SupplyPH String Y 공급 산성도 pH 3-7 HighSoilTemp String Y 화분 흙 상단 온도 °C 3-8 HighSoilHumi String Y 화분 흙 상단 습도 % 3-9 HighEC String Y 화분 흙 상단 영양분 농도 dS/m 3-10 HighPH String Y 화분 흙 상단 산성도 pH 3-11 LowSoilTemp String Y 화분 흙 하단 온도 °C 3-12 LowSoilHumi String Y 화분 흙 하단 습도 % 3-13 LowSoilEC String Y 화분 흙 하단 영양분 농도 dS/m 3-14 LowSoilPH String Y 화분 흙 하단 산성도 pH 4 watering 관수정보 4-1 IrrigationState String Y 관수 상태 미관수/관수중 4-2 WateringTime String Y 관수 시간 4-3 AmtIrrigation String Y 관수량 dm³ 5 picInfo 사진정보 5-1 ImageType String Y 사진 포맷 jpg 5-2 PhotographerID String Y 사진작가 ID 5-3 ImageTakeDT String Y 촬영 시간 5-4 ImageSize String Y 사진 크기 byte 5-5 ImageName String Y 사진명 5-6 FilmingLocation String Y 촬영 위치 5-7 ShootingAngle String Y 촬영 각도 수직(V)/수평(H) 5-8 ShootingDistance String Y 촬영 거리 cm 5-9 ImageResolution String Y 해상도 pixel 6 annotations Array 폴리곤 어노테이션 정보 6-1 plant_id String Y 식물 클래스 ID A-1-01-L-1 6-2 plant_name String Y 식물명 15종 참고 6-3 plant_polygon array Y 폴리곤 위치 정보 $value number Y 6-4 plant_polygonTitle String Y 폴리곤 잎 정보 upperLeaf/lowerLeaf/lateralLeafLeft/lateralLeafRight - 데이터포맷
- 원천이미지 및 폴리곤 적용 예시데이터포맷 - 원천이미지 및 폴리곤 적용 예시 원천 이미지(원예식물) 원천 이미지(폴리곤 적용 시) 

- Json 포맷 예시
{
"info": {
"GetDateTime": "202309171804",
"ClassID": "A-2-07-L-3",
"ResultOfGrowthLevel": "High",
"Place": "거실(L)",
"ImageCaption": "잎의 색깔이 초록색을 가지고 있는 스파티필럼이 화분에 담겨져 있으며, 네모난 인식표가 보입니다."
},
"plant": {
"PlantName": "스파티필럼",
"PlantClass": "중생식물",
"RootLength": {
"plant": "210",
"uproot": "209"
},
"SoilState": "습한흙",
"GrowthStage": "생장단계",
"Environment": "과습",
"PlantThickness":[{"date": "20230823", "thickness": "0.606"},
{"date": "20230912", "thickness": "1.714"}],
"PlantHeight": [{"date": "20230823", "height": "195.579"},
{"date": "20230912", "height": "212.436"}]
},
"sensor": {
"AirTemperature": "31.7",
"Co2": "244",
"Quantum": "9",
"SupplyEC": "1.5",
"SupplyPH": "7",
"HighSoilTemp": "31.0",
"HighSoilHumi": "30.9",
"HighEC": "200.0",
"HighPH": "5.47",
"LowSoilTemp": "30.7",
"LowSoilHumi": "86.8",
"LowSoilEC": "222.0",
"LowSoilPH": "4.34",
"AirHumidity": "62.6"
},
"watering": {
"IrrigationState": "관수중",
"WateringTime": "202309171804",
"AmtIrrigation": "86"
},
"picInfo": {
"ImageType": "jpg",
"PhotographerID": "USERID",
"ImageTakeDT": "202309171804",
"ImageSize": "3965740",
"ImageName": "N50-A-2-07-L-3-H-230917-000938.jpg",
"FilmingLocation": "37.499035,127.025597",
"ShootingDistance": "26",
"ImageResolution": "2160 * 3840",
"ShootingAngle": "수평(H)"
},
"annotations": [{"plant_id": "A-2-07-L-3",
"plant_name": "스파티필럼",
"plant_polygon": [ 1110, 1624, 1080, 1612, 1061, 1040, 1586, 1093, 1638],
"plant_polygonTitle": "lateralLeafLeft"},
{"plant_id": "A-2-07-L-3",
"plant_name": "스파티필럼",
"plant_polygon": [ 1758, 1758, 1778, 1708, 1803, 1695, 1815, 1655, 1767],
"plant_polygonTitle": "lateralLeafRight"}
]
- 실제 예시
-
데이터셋 구축 담당자
수행기관(주관) : ㈜지뉴소프트
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 홍성극 02-3463-0802 [email protected] 수집,정제,가공,검사,AI 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜동양테크윈 데이터 수집, 정제 ㈜글로텍 데이터 가공 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 임태훈 010-3307-5558 [email protected] 홍성극 010-6432-9054 [email protected] AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 임태훈 010-3307-5558 [email protected] 홍성극 010-6432-9054 [email protected] 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 임태훈 010-3307-5558 [email protected] 홍성극 010-6432-9054 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.