NEW 차트 이미지-텍스트 쌍 데이터
- 분야영상이미지
- 유형 텍스트 , 이미지
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-10-30 데이터 최종 개방 1.0 2024-06-28 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-09-03 구축활용가이드, 어노테이션 포맷 및 데이터 구조 수정 2024-09-02 데이터설명서 수정 2024-06-28 산출물 공개 Beta Version 소개
- 문서 내 차트의 내용 정보를 구조화된 문장으로 자동 추출하기 위한 차트 이미지와 설명문 텍스트로 구성된 데이터셋
구축목적
- 차트 이미지에 대한 해석 데이터를 생성하며 차트 정보 추론이 가능한 서비스를 구축하는데 사용할 수 있는 인공지능 학습용 데이터 구축
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 텍스트 , 이미지 데이터 형식 jpg, json 데이터 출처 국가 공공 사이트, MOU/수요기관 협약, 주관사에서 자체 생성한 데이터에서 수집 가능한 차트 이미지 라벨링 유형 차트 구성요소 라벨링(이미지)/내용 생성 요약(자연어) 라벨링 형식 json 데이터 활용 서비스 - 차트로 작성된 자료 취합과 통계, 분석 등의 서비스 - 차트 분석 데이터를 활용한 챗봇 질의응답 서비스 - 시각장애인 또는 인지 능력이 상대적으로 낮은 노약자의 정보제공 및 차트에 대한 음성 정보 제공 서비스 데이터 구축년도/
데이터 구축량2023년/원천데이터(jpg, json) : 300,002세트 라벨링 데이터(json) : 300,002개 -
- 데이터 통계
데이터 통계 대분류 데이터 형태 원천데이터 규모 라벨링데이터 규모 세로 막대형 차트 이미지 106,642장 106,642건 차트 내용 정보 106,642건 가로 막대형 차트 이미지 84,133장 84,133건 차트 내용 정보 84,133건 원형 차트 이미지 38,608장 38,608건 차트 내용 정보 38,608건 선형 차트 이미지 42,015장 42,015건 차트 내용 정보 42,015건 기타 차트 이미지 28,604장 28,604건 차트 내용 정보 28,604건 합계 600,004 300,002건 - 차트 유형별
차트 유형별 대분류 구축 수량(건) 구성비(%) 세로 막대형 106,649 35.55 가로 막대형 84,127 28.04 원형 38,634 12.88 선형 42,019 14.01 기타 28,573 9.52 합계 300,002 100 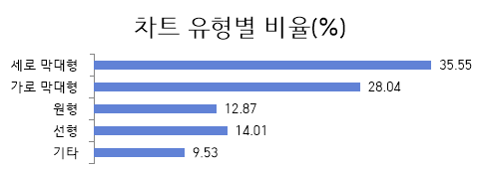
- 차트 분야별
차트 분야별 분야 구축 수량(건) 비율(%) 경제 64,334 21.45 과학 20,409 6.8 문화 34,344 11.45 보건 47,882 15.96 사회/교육 94,625 31.54 산업 38,408 12.8 합계 300,002 100 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- AI 모델 설계
DEPLOT(Image to data) + KE-T5(Data to Text)로 이루어진 2-Step Pipe Line 모델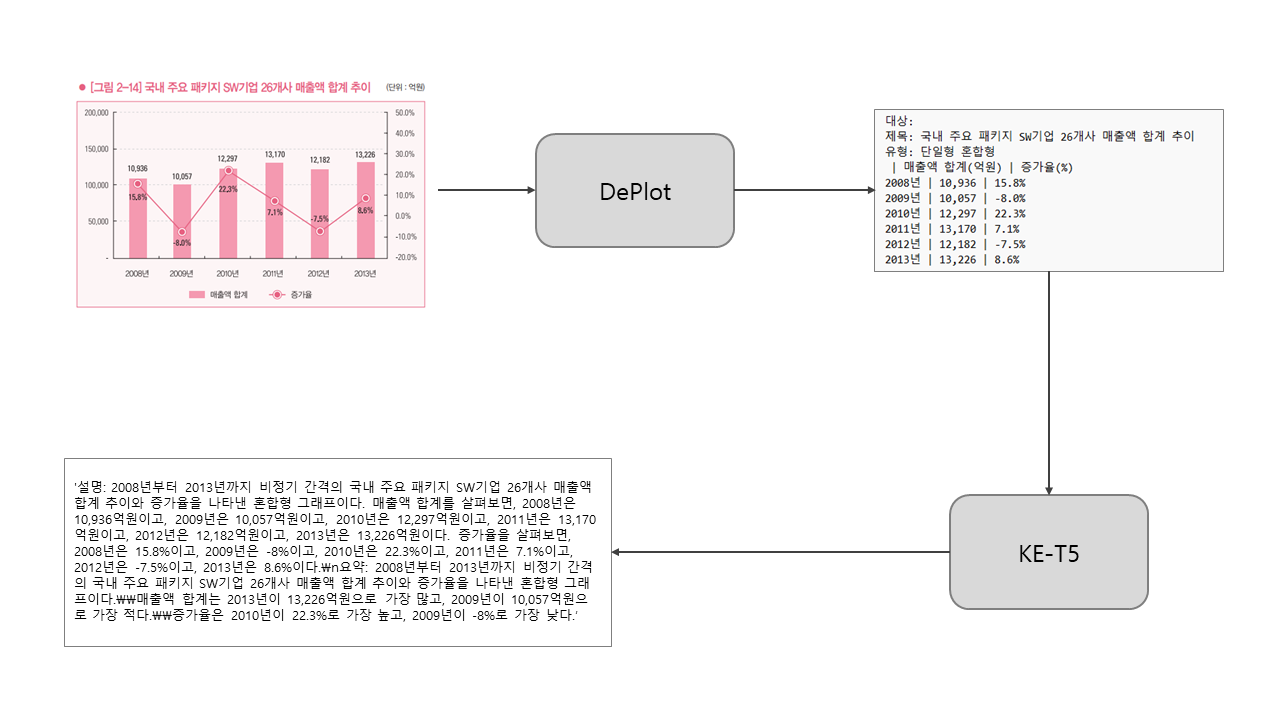
1) DEPLOT (Pretrain)
- 구글 브레인에서 공개한 pix2struct 모델을 차트 이미지 구조화에 특화시켜 학습시킨 모델로 4개의 차트 유형(막대, 선형, 점선, 원형)에 대해 좋은 성능을 보임
- 대부분 연구에서 차트 이미지의 데이터 객체에 bounding box를 표기하는 방식을 이용하나, 해당 모델은 bounding box 없이 차트 이미지를 데이터 테이블 형식(표 형태의 텍스트)으로 해석함2) KE-T5 (Finetuning)
- T5(Text-To-Text Transformer) 모델을 한국어와 영어 코퍼스를 이용하여 사전학습한 모델
- T5는 인용이 가장 높은 선행연구의 구조를 활용하고 NLU Task에서 SOTA 성능을 보이는 사전학습모델- 성능 평가 지표
- 설명문은 BLEU, 요약문은 BLEU-RT로 설명문과 요약문에 대한 측정 성능 지표를 달리함.
- BLEU 점수(Bilingual Evaluation Understudy score) : 예측 문장과 실제 문장이 얼마나 유사한지 n-gram에 기반하여 측정
- BLEU-RT 점수(Bilingual Evaluation Understudy with Representations from Transformers) : 문맥을 이해하는 BERT 기반으로 사전훈련된 회귀 모델을 사용하여 실제 문장과 예측 문장이 주어졌을 때, 예측 문장이 실제 문장과 어느 정도 유사한지 점수로 반환하는 방법
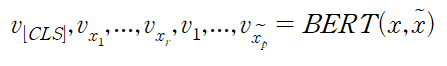
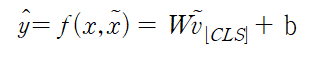
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성
데이터 구성 Key Description Type info.name 데이터셋 명 String info.description 데이터셋 상세설명 String info.year 데이터셋 생성연도 String image[].id 이미지 식별자 Number image[].file_name 이미지 파일명 String image[].width 이미지 너비 Number image[].height 이미지 높이 Number metadata.image_id 이미지 ID Number metadata.data_category 차트 분야 String metadata.chart_source 차트 출처 String metadata.chart_color 차트 색상 String metadata.chart_multi 차트 복잡도 String metadata.chart_year 차트 연도 Number metadata.chart_main 차트 대분류 String metadata.chart_sub 차트 중분류 String annotations[].image_id 이미지 ID Number annotations[].is_title 차트 제목 유무 Boolean annotations[].is_legend 차트 범례 유무 Boolean annotations[].is_datalabel 차트 데이터레이블 유무 Boolean annotations[].is_unit 차트 단위 유무 Boolean annotations[].is_base 차트 베이스 유무 Boolean annotations[].is_axis_label_x_axis 차트 X축 유무 Boolean annotations[].is_axis_label_y_axis 차트 Y축 유무 Boolean annotations[].title 차트 제목 String annotations[].legend 차트 범례 Arr[String] annotations[].unit 차트 단위 String annotations[].base 차트 베이스 String annotations[].axis_title.x_axis X축 제목 String annotations[].axis_title.y_axis Y축 제목 String annotations[].axis_label.x_axis X축 레이블 목록 Arr[String] annotations[].axis_label.y_axis Y축 레이블 목록 Arr[String] description 차트 설명문 String summary 차트 요약문 Arr[String] - 어노테이션 포맷
어노테이션 포맷 구분 속성명 타입 필수
여부설명 1 image Arr[Obj] 이미지 정보 1-1 image[].id Number Y 이미지 식별자 1-2 image[].filename String Y 이미지 파일명 1-3 image[].width Number Y 이미지 너비 1-4 image[].height Number Y 이미지 높이 2 metadata Object 메타데이터 2-1 metadata.image_id Number Y 이미지 ID 2-2 metadata.data_category String Y 차트 분야 2-3 metadata.chart_source String Y 차트 출처 2-4 metadata.chart_color String Y 차트 색상 2-5 metadata.chart_multi String Y 차트 복잡도 2-6 metadata.chart_year Number Y 차트 연도 2-7 metadata.chart_main String Y 차트 대분류 2-8 metadata.chart_sub String Y 차트 중분류 3 annotations Arr[Obj] 어노테이션 정보 3-1 annotations[].image_id Number Y 이미지 ID 3-2 annotations[].is_title Boolean Y 차트 제목 유무 3-3 annotations[].is_legend Boolean Y 차트 범례 유무 3-4 annotations[].is_datalabel Boolean Y 차트 데이터레이블 유무 3-5 annotations[].is_unit Boolean Y 차트 단위 유무 3-6 annotations[].is_base Boolean Y 차트 베이스 유무 3-7 annotations[].is_axis_label_x_axis Boolean Y 차트 X축 유무 3-8 annotations[].is_axis_label_y_axis Boolean Y 차트 Y축 유무 3-9 annotations[].title String N 차트 제목 3-10 annotations[].legend Arr[String] N 차트 범례 3-11 annotations[].unit String N 차트 단위 3-12 annotations[].base String N 차트 베이스 3-13 annotations[].axis_title Object 차트 축 제목 3-13-1 annotations[] String N X축 제목 .axis_title.x_axis 3-13-2 annotations[] String N Y축 제목 .axis_title.y_axis 3-14 annotations[] Object 차트 축 레이블 .axis_label 3-14-1 annotations[] Arr[String] N X축 레이블 목록 .axis_label.x_axis 3-14-2 annotations[] Arr[String] N Y축 레이블 목록 .axis_label.y_axis 3-15 annotations[] Arr[Arr[ Y 차트 데이터레이블 .data_label String]] 4 description String Y 차트 설명문 5 summary Arr[String] Y 차트 요약문 - 데이터 포맷
데이터 포맷 구분 데이터(라벨링) 유형 규모 파일포맷 데이터 유형 원천데이터 이미지 300,002건 JPG 10종의 차트 이미지 텍스트 300,002건 JSON 메타정보, 차트 내용 텍스트화 정보 라벨링데이터 내용요약(자연어) 300,002건 JSON 메타정보, 차트 구성요소 라벨링, 설명문, 요약문 - 데이터셋 예시
- 원천데이터 (이미지)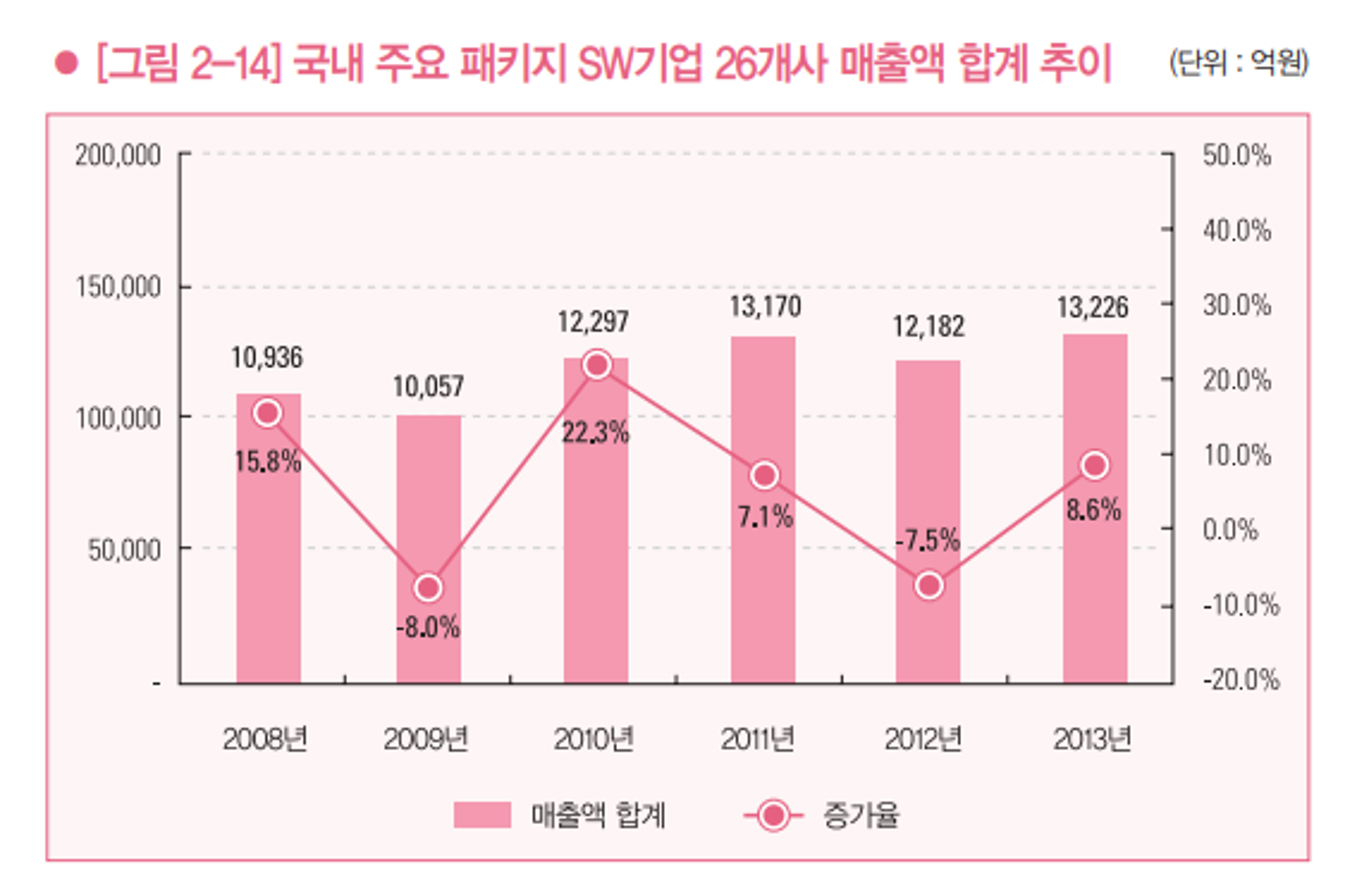
- 원천데이터 (차트 내용 정보)원천데이터 (차트 내용 정보) {
"image": [
{
"id": 29024,
"filename": "C_Source_029024_etc_mix",
"width": 568,
"height": 365
}
],
"metadata": {
"image_id": 29024,
"data_category": "경제",
"chart_source": "정보통신산업진흥원",
"chart_color": "컬러",
"chart_multi": "단일형",
"chart_year": "2013",
"chart_main": "기타",
"chart_sub": "혼합형",
"chart_text": [
"200,000", "50.0%", "40.0%", "150,000", "13,170", "13,226", "30.0%", "12,297",
"12,182", "10,936", "10,057", "20.0%", "100,000", "22.3%", "15.8%", "10.0%",
"7.1%", "8.6%", "50,000", "-7.5%", "0.0%", "-10.0%", "-8.0%", "-20.0%", "2008년",
"2009년", "2010년", "2011년", "2012년", "2013년", "%", "-",
"국내 주요 패키지 SW기업 26개사 매출액 합계 추이", "단위 : 억원",
" 매출액 합계", " 증가율"
]
}
}- 라벨링 데이터
라벨링 데이터 {
"image": [
{
"id": 29024,
"filename": "C_Source_029024_etc_mix",
"width": 568,
"height": 365
}
],
"metadata": {
"image_id": 29024,
"data_category": "경제",
"chart_source": "정보통신산업진흥원",
"chart_color": "컬러",
"chart_multi": "단일형",
"chart_year": "2013",
"chart_main": "기타",
"chart_sub": "혼합형“
},
"annotations": [
{
"image_id": 29024,
"is_title": true,
"is_legend": true,
"is_datalabel": true,
"is_unit": true,
"is_base": false,
"is_axis_label_x_axis": true,
"is_axis_label_y_axis": true,
"title": "국내 주요 패키지 SW기업 26개사 매출액 합계 추이",
"legend": ["매출액 합계"],
"unit": "억원",
"base": "",
"axis_title": {
"x_axis": "",
"y_axis": "“
},
"axis_label": {
"x_axis": [
"2008년",
"2009년",
"2010년",
"2011년",
"2012년",
"2013년“
],
"y_axis": [
"-",
"50,000",
"100,000",
"150,000",
"200,000“
]
},
"data_label": [
[
"10,936",
"10,057",
"12,297",
"13,170",
"12,182",
"13,226“
]
]
},
{
"image_id": 29024,
"is_title": true,
"is_legend": true,
"is_datalabel": true,
"is_unit": true,
"is_base": false,
"is_axis_label_x_axis": true,
"is_axis_label_y_axis": true,
"title": "국내 주요 패키지 SW기업 26개사 매출액 합계 추이",
"legend": ["증가율"],
"unit": "%",
"base": "",
"axis_title": {
"x_axis": "",
"y_axis": "“
},
"axis_label": {
"x_axis": [
"2008년",
"2009년",
"2010년",
"2011년",
"2012년",
"2013년“
],
"y_axis": [
"-20.0%",
"-10.0%",
"0.0%",
"10.0%",
"20.0%",
"30.0%",
"40.0%",
"50.0%“
]
},
"data_label": [
[
"15.8%",
"-8.0%",
"22.3%",
"7.1%",
"-7.5%",
"8.6%“
]
]
}
],
"description": "2008년부터 2013년까지 비정기 간격의 국내 주요 패키지 SW기업 26개사 매출액 합계 추이와 증가율을 나타낸 혼합형 그래프이다. 매출액 합계를 살펴보면, 2008년은 10,936억원이고, 2009년은 10,057억원이고, 2010년은 12,297억원이고, 2011년은 13,170억원이고, 2012년은 12,182억원이고, 2013년은 13,226억원이다. 증가율을 살펴보면, 2008년은 15.8%이고, 2009년은 -8%이고, 2010년은 22.3%이고, 2011년은 7.1%이고, 2012년은 -7.5%이고, 2013년은 8.6%이다.",
"summary": [
"2008년부터 2013년까지 비정기 간격의 국내 주요 패키지 SW기업 26개사 매출액 합계 추이와 증가율을 나타낸 혼합형 그래프이다.",
"매출액 합계는 2013년이 13,226억원으로 가장 많고, 2009년이 10,057억원으로 가장 적다.",
"증가율은 2010년이 22.3%로 가장 높고, 2009년이 -8%로 가장 낮다.“
]
} -
데이터셋 구축 담당자
수행기관(주관) : ㈜메트릭스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 나윤정 02 6244 0790 [email protected] 사업 총괄 및 관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜메트릭스 수집, 정제, 가공, 검사 ㈜더바이럴 가공 ㈜서홍테크 검사 ㈜한알음정보 검사 ㈜브레인벤쳐스 품질 검증, AI 모델 개발 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 나윤정 02-6244-0790 [email protected] 박래희 02-6377-0826 [email protected] AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 김원회 070-4128-0515 [email protected] 이준호 070-4128-0515 [email protected] 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 이미연 070-5129-0253 [email protected] 임수연 070-5129-0253 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.