NEW AI허브 데이터 활용을 위한 기계 번역앱 구축과 번역기 평가 및 신규 말뭉치 구축 (2023)
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-10-30 데이터 최종 개방 1.0 2024-06-28 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-28 산출물 공개 Beta Version 소개
- 번역 메모리(TM)로 활용할 AI허브 공개 데이터의 정제•검수 데이터 - 기계 번역기 성능 향상을 위한 신규 말뭉치를 비롯한 비교 평가 데이터
구축목적
- AI 허브에 공개된 말뭉치 데이터를 활용하여 TM 구축 - 기계 번역기 성능 향상을 위한 신규 말뭉치와 비교 평가 데이터 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 AIHUB / 학술 논문 라벨링 유형 번역 (자연어) 라벨링 형식 json 데이터 활용 서비스 1) TM 활용 API 서비스 / 2) 번역기 평가 앱 서비스 데이터 구축년도/
데이터 구축량2023년/1,400,000문장 -
- 데이터 구축 규모
데이터 구축 규모 1 데이터 소스 구축 데이터 담당기관 2차년도 AI Hub ① TM 구축 (Translation Memory) 트위그팜, 시스트란, 휴텍씨 최소 800,000 문장
(한중 53만, 한일 19만 5천, 영한 9천, 한영 6만 6천)데이터 구축 규모 2 담당기관 2차년도 ➁ TM 활용 API 서비스 트위그팜 TM 활용 API 구축
(Create, Update, Delete 구현)➂ 번역기 평가 앱 서비스 트위그팜, 시스트란 기계번역기 비교앱(Platform) 구축
(Web, Android, iOS)데이터 구축 규모 3 데이터 소스 구축 데이터 담당기관 2차년도 구축
플랫폼➃ 신규 말뭉치 데이터 트위그팜, 글나무,
렉스코드, 시스트란, 휴텍씨최소 600,000 문장
(한-영 20만, 한-일 20만, 한-중 20만)➄ 번역기 평가 데이터 트위그팜, 글나무,
렉스코드최소 600,000 건
(한국어, 영어 외 기타 언어)➅ 유사 문장 데이터 트위그팜 최소 600,000 건
(한국어, 영어 외 기타 언어)⑦ MTPE 시험 데이터 트위그팜, 휴텍씨 최소 100,000 건
(한국어, 영어 외 기타 언어)- 데이터 분포
데이터 분포 1차 경로 2차 경로 3차 경로 제출 수량 최종(문장 수) 01. TM 구축 데이터 01 한일(문화) - 195,489 02 한중
(기술과학 사회과학)- 549,710 03 영한(특허) - 19,638 04 한영(인문학 기초과학) - 70,234 04. 신규 말뭉치 01 한영(8) 공학(1) 35,155 농수해양학(1) 24,830 복합학(1) 5,123 사회과학(1) 92,304 예술체육학(1) 4,846 의약학(1) 34,552 인문학(1) 5,352 자연과학(1) 9,522 02 한일(8) 공학(1) 34,837 농수해양학(1) 24,859 복합학(1) 5,127 사회과학(1) 90,485 예술체육학(1) 4,855 의약학(1) 36,145 인문학(1) 5,360 자연과학(1) 9,543 03 한중(8) 공학(1) 34,084 농수해양학(1) 24,850 복합학(1) 5,131 사회과학(1) 91,791 예술체육학(1) 4,831 의약학(1) 36,182 인문학(1) 5,365 자연과학(1) 9,529 05. 번역기 평가 데이터 - - 659,986 06. 유사문장 데이터 - - 634,647 07. MTPE 시험 데이터 - - 100,280 총 수량 2,864,642 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 인공지능 모델(알고리즘) : TM 영-한 데이터
인공지능 모델(알고리즘) : TM 영-한 데이터 개발 언어 Python 3.9.18 프레임워크 Pytorch 2.1.1 학습 알고리즘 OpenNMT-Transformer 학습 조건 - batch_size: 8,192
- batch_type: "tokens"
- train_steps: 150,000
- valid_steps: 1,000
- warmup_steps: 6,000
- learning_rate: 2
- decay_method: "noam"파일형식 • 학습 데이터셋: TM_enko_train.en, TM_enko_train.ko • 평가 데이터셋: TM_enko_test.en, TM_enko_test.ko 전체 구축 데이터 대비
모델에 적용되는 비율AI모델 사용 텍스트 비율(수량)
- <121-1> 영-한 병렬 말뭉치 : 100% (19,638 문장)모델 학습 과정별 데이터
분류 및 비율 정보- Training Set: 85.3% (16,752 문장)
- Validation Set: 10.% (1,964 문장)
- Test Set: 4.7% (922 문장)
총계: 19,638 문장- 인공지능 모델(알고리즘) : TM 한-영 데이터 / 신규말뭉치 한-영 데이터
인공지능 모델(알고리즘) : TM 한-영 데이터 / 신규말뭉치 한-영 데이터 개발 언어 Python 3.9.18 프레임워크 Pytorch 2.1.1 학습 알고리즘 OpenNMT-Transformer 학습 조건 - batch_size: 64
- batch_type: "sents"
- train_steps: 30,000
- valid_steps: 1,000
- warmup_steps: 6,000
- learning_rate: 2
- decay_method: "noam"파일형식 • 학습 데이터셋: TM_koen_train.ko, TM_koen_train.en,
NEW_koen_train.ko, NEW_koen_train.en• 평가 데이터셋: (121-1) TM_koen_test.ko, TM_koen_test.en
(121-4) NEW_koen_test.ko, NEW_koen_test.en전체 구축 데이터 대비
모델에 적용되는 비율AI모델 사용 텍스트 비율(수량)
- <121-1> 한-영 병렬 말뭉치 : 100% (70,234 문장)
- <121-4> 한-영 병렬 말뭉치 : 100% (211,684 문장)모델 학습 과정별 데이터
분류 및 비율 정보- Training Set: 82.5% + 80% (57,943 + 169,348 = 227,291 문장)
- Validation Set: 10% + 10% (7,024 + 21,167 = 28,191 문장)
- <121-1> Test Set: 7.5% (5,267 문장)
<121-4> Test Set: 10% (21,169 문장)
총계: 281,918 문장- 인공지능 모델(알고리즘) : TM 한-일 데이터 / 신규말뭉치 한-일 데이터
인공지능 모델(알고리즘) : TM 한-일 데이터 / 신규말뭉치 한-일 데이터 개발 언어 Python 3.9.18 프레임워크 Pytorch 2.1.1 학습 알고리즘 OpenNMT-Transformer 학습 조건 - batch_size: 2,048
- batch_type: "tokens"
- train_steps: 220,000
- valid_steps: 1,000
- warmup_steps: 6,000
- learning_rate: 2
- decay_method: "noam"파일형식 • 학습 데이터셋: TM_koja_train.ko, TM_koja_train.ja,
NEW_koja_train.ko, NEW_koja_train.ja• 평가 데이터셋: (121-1) TM_koja_test.ko, TM_koja_test.ja
(121-4) NEW_koja_test.ko, NEW_koja_test.ja전체 구축 데이터 대비
모델에 적용되는 비율AI모델 사용 텍스트 비율(수량)
- <121-1> 한-일 병렬 말뭉치 : 100% (195,489 문장)
- <121-4> 한-일 병렬 말뭉치 : 100% (211,211 문장)모델 학습 과정별 데이터
분류 및 비율 정보- Training Set: 80% + 80% (156,391 + 168,969 = 325,360 문장)
- Validation Set: 10% + 10% (19,549 + 21,120 = 40,669 문장)
- (121-1) Test Set: 10% (19,549 문장)
(121-4) Test Set: 10% (21,122 문장)
총계: 최소 406,700 문장- 인공지능 모델(알고리즘) : TM 한-중 데이터 / 신규말뭉치 한-중 데이터
인공지능 모델(알고리즘) : TM 한-중 데이터 / 신규말뭉치 한-중 데이터 개발 언어 Python 3.9.18 프레임워크 Pytorch 2.1.1 학습 알고리즘 OpenNMT-Transformer 학습 조건 - batch_size: 4,096
- batch_type: "tokens"
- train_steps: 220,000
- valid_steps: 1,000
- warmup_steps: 6,000
- learning_rate: 2
- decay_method: "noam"파일형식 • 학습 데이터셋: TM_kozh_train.ko, TM_kozh_train.zh,
NEW_kozh_train.ko, NEW_kozh_train.코• 평가 데이터셋: (121-1) TM_kozh_test.ko, TM_kozh_test.zh
(121-4) NEW_kozh_test.ko, NEW_kozh_test.코전체 구축 데이터 대비
모델에 적용되는 비율AI모델 사용 텍스트 비율(수량)
- <121-1> 한-중 병렬 말뭉치 : 100% (549,710 문장)
- <121-4> 한-중 병렬 말뭉치 : 100% (211,763 문장)모델 학습 과정별 데이터
분류 및 비율 정보- Training Set: 80% + 80.2% (439,768 + 169,860 = 609,628 문장)
- Validation Set: 10% + 10% (54,971 + 21,175 = 76,146 문장)
- (121-1) Test Set: 10% (54,971 문장)
(121-4) Test Set: 9.8% (20,728 문장)
총계: 최소 761,473 문장- openNMT 기계 번역기 모델
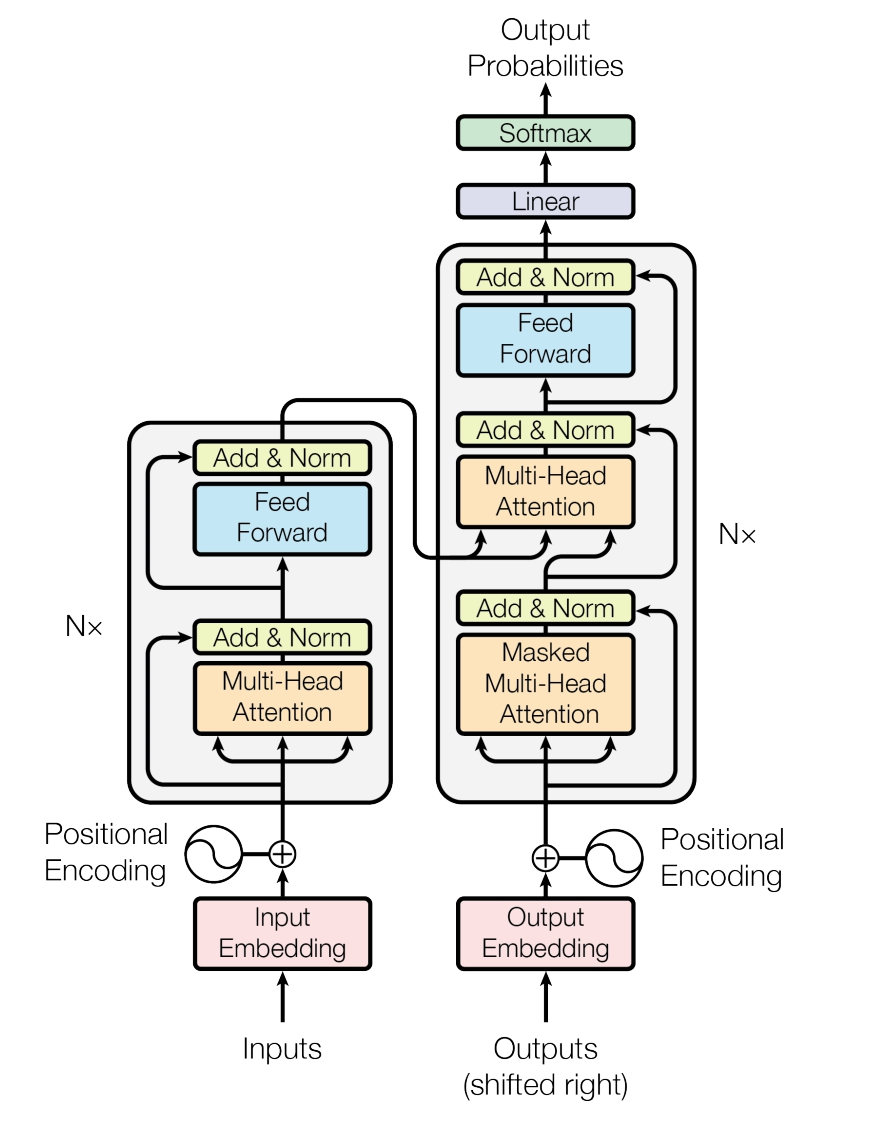
● Transformer 기계 번역기를 현재로 상용에서 사용하고 있는 기계 번역기 모델임
● Transformer의 경우 우수한 결과물을 만들기 위해서는 필수적으로 우수한 학습 데이터가 필요함
● 언어별 본 과제 분야에 특화된 번역기 모델을 학습하여 해당 분야의 수요 기관에서 직접적으로 사용이 가능함 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성 (TM 구축 데이터 및 신규 말뭉치 데이터)
데이터 구성 (TM 구축 데이터 및 신규 말뭉치 데이터) 1레벨 2레벨 3레벨 4레벨 01. TM 구축 데이터 01 한일(문화) 02 한중(기술과학 사회과학) 03 영한(특허) 04 한영(인문학 기초과학) 04. 신규 말뭉치 01 한영(8) 공학(1) 농수해양학(1) 복합학(1) 사회과학(1) 예술체육학(1) 의약학(1) 인문학(1) 자연과학(1) 02 한일(8) 공학(1) 농수해양학(1) 복합학(1) 사회과학(1) 예술체육학(1) 의약학(1) 인문학(1) 자연과학(1) 03 한중(8) 공학(1) 농수해양학(1) 복합학(1) 사회과학(1) 예술체육학(1) 의약학(1) 인문학(1) 자연과학(1) 05. 번역기 평가 데이터 06. 유사문장 데이터 07. MTPE 시험 데이터 - 어노테이션 포맷 (TM 구축 데이터)
어노테이션 포맷 (TM 구축 데이터) 구분 속성명 타입 필수여부 설명 범위 비고 1 data TM 구축 데이터 1-1 SN string y 데이터 식별자 1-2 DOMAIN string y 데이터 분야 1-3 SOURCE_SENTENCE string y 원문 1-4 TARGET_SENTENCE string y 번역문 1-5 source_language_code string y 원문 언어 1-6 target_language_code string y 번역문 언어 1-7 source_word_count number n 원문_어절 수 1-8 target_word_count number n 번역문_어절 수 TM 구축 데이터의 “영한 특허 데이터”의 경우, 언어쌍의 특수성으로 아래와 같은 라벨 구성 요소를 갖춤
TM 구축 데이터의 “영한 특허 데이터”의 경우, 언어쌍의 특수성으로 아래와 같은 라벨 구성 요소를 갖춤 구분 속성명 타입 필수여부 설명 범위 비고 1 data TM 구축 데이터 1-1 SN string y 데이터 식별자 1-2 DOMAIN string y 데이터 분야 1-3 SOURCE_SENTENCE string y 원문 초록/청구항 1-4 TARGET_SENTENCE string y 번역문 초록/청구항 1-5 text_type string y 초록/청구항 1-6 source_language_code string y 원문 언어 1-7 target_language_code string y 번역문 언어 1-8 source_word_count number n 원문_어절 수 1-9 target_word_count number n 번역문_어절 수 - 어노테이션 포맷 (신규 말뭉치 데이터)
어노테이션 포맷 (신규 말뭉치 데이터) 구분 속성명 타입 필수여부 설명 범위 비고 1 data 신규 말뭉치 데이터 1-1 SN string y 데이터 식별자 1-2 DOMAIN string y 데이터 대분류 1-3 SUBDOMAIN string y 데이터 중분류 1-4 FILE_NAME string y 데이터 식별자 1-5 SOURCE_SENTENCE string y 원문 1-6 MT_SENTENCE string y 기계번역문 1-7 TARGET_SENTENCE string y 번역문 1-8 MT_PROVIDER string y 기계번역문 출처 1-9 SOURCE_LANGUAGE_CODE string y 원문 언어 1-10 TARGET_LANGUAGE_CODE string y 번역문 언어 1-11 source_word_count number n 원문_어절 수 1-12 target_word_count number n 번역문_어절 수 -
데이터셋 구축 담당자
수행기관(주관) : 트위그팜
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 백철호 1833-5926 [email protected] 총괄 담당자 수행기관(참여)
수행기관(참여) 기관명 담당업무 글나무 데이터 가공 : 신규말뭉치 기계 번역 (한중)
데이터 검수 : 신규말뭉치 기계 번역 검수 (한영)렉스코드 데이터 가공 : 신규말뭉치 기계 번역 (한일)
데이터 검수 : 신규말뭉치 기계 번역 검수 (한중)휴텍씨 데이터 가공 : 신규말뭉치 기계 번역 및 검수 (한영)
데이터 검수 : 신규말뭉치 MTPE 시험 데이터 (한영)시스트란 데이터 가공 : TM 구축 휴먼 번역 (영한), 신규말뭉치 기계 번역 검수 (한일)
데이터 검수 : TM 구축 휴먼 번역 검수 (영한), 신규말뭉치 기계 번역 검수 (한일)인공지능산업융합사업단 컴퓨팅 자원 제공, 데이터 공용 활용, 홍보 및 네트워킹 표준협회 번역기 평가 앱 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 백철호 02-1833-5926 [email protected] 송수민 02-1833-5926 [email protected] AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 이세영 02-1833-5926 [email protected] 강가람 02-1833-5926 [email protected] 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 백철호 02-1833-5926 [email protected] 송수민 02-1833-5926 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.