-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-10-30 데이터 최종 개방 1.0 2024-08-05 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-08-05 산출물 공개 Beta Version 소개
- 한국과 인도네시아어 맥락을 포함한 인도네시아어 말뭉치 데이터로 다국어로 학습된 초거대 AI 학습 시 한국과 인도네시아 관련 맥락의 이해를 돕는 2억 토큰으로 이루어진 말뭉치입니다.
구축목적
- 인도네시아어 자동 번역, 텍스트 요약, 검색 엔진, 챗봇 등 다양한 자연어처리 모델 성능 향상을 위한 초거대 (생성형)AI 학습셋 구축 - 한국-인도네시아 관계에서 한류, 한국 문화, 관광, 상품 등 관련 도메인 인식 정확도 향상을 위한 개체명 인식 데이터셋 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 csv 데이터 출처 뉴스, 트위터, 위키피디아 라벨링 유형 개체명 인식(자연어) 라벨링 형식 json 데이터 활용 서비스 초거대 AI 학습 데이터 구축년도/
데이터 구축량2023년/200,113,484 토큰 -
- 데이터 구축 규모
데이터 구축 규모 구분 총계 파일 개수 8,790,584 문장 개수 13,781,860 토큰 개수 200,113,484 - 데이터 분포
- 데이터 수량 분포데이터 분포 - 데이터 수량 분포 분류 SNS Newspaper Others 분류 상세 Twitter(X) LexisNexis Wikipedia, Terkinni.com 파일 개수 (비율) 8,632,379 124,161 34,044 문장 개수 (비율) 11,421,340 1,937,865 422,655 토큰 개수 (비율) 149,884,150 40,386,582 9,842,752 - Training / Validation / Test 분류
데이터 분포 - Training / Validation / Test 분류 분류 Training Validation Others 분류 비율
(라벨링 데이터 기준)8 1 1 원천데이터 파일 수 220 29 28 라벨링데이터 파일 수 7,032,326 879,058 879,060 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 개체명 인식 모델
- 인도네시아어로 학습된 사전학습 모델 불러와서 미세조정 학습 진행
- IndoBERT (https://huggingface.co/indobenchmark/indobert-base-p2)로 학습 진행
구축된 인도네시아어 말뭉치의 라벨링 데이터를 Train set, Validation set, Test set을 8 : 1 :1 비율로 분리하여 학습 및 학습 결과 검증에 활용
사전학습된 모델에 개체명이 태깅되어 있는 Train set 데이터로 미세조정 학습
학습 완료 후, 완료된 모델로 태깅이 되어 있지 않은 인도네시아어 문장에서 각 토큰에 대해 개체명 인식 가능(토큰 별로 띄어쓰기된 텍스트 필요)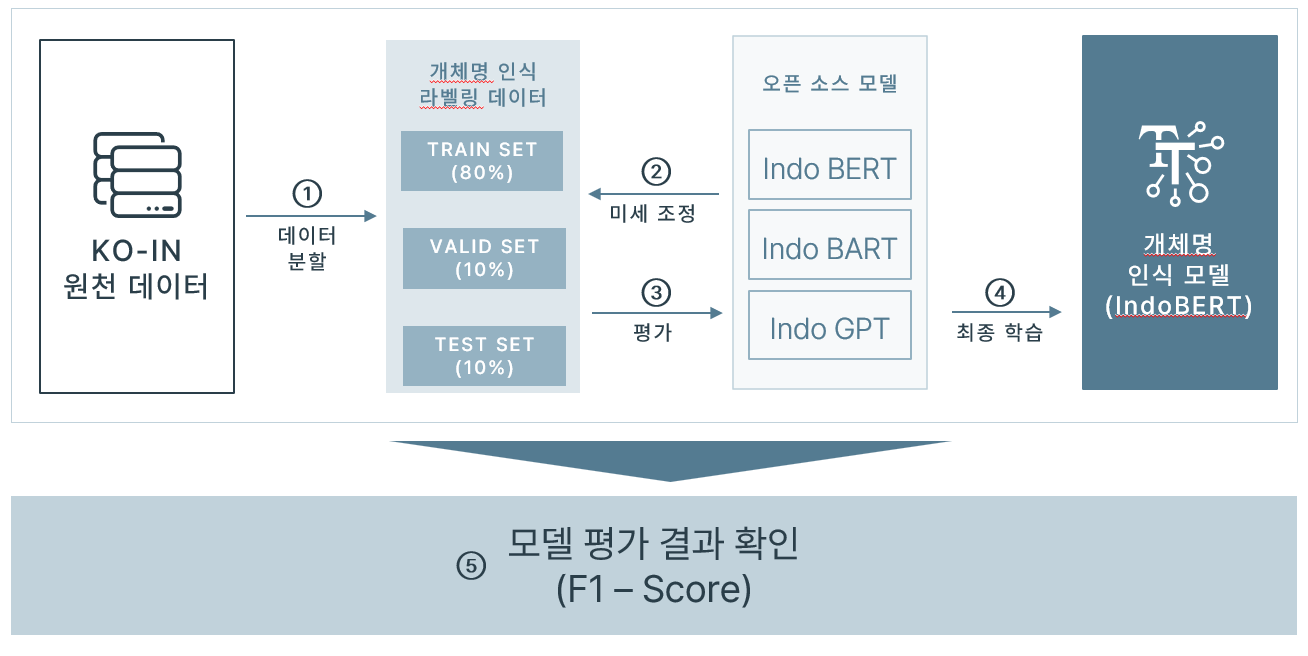
- 언어 생성 모델
- 언어생성이 가능한 초거대 AI 사전학습 모델 불러와서 전체 데이터로 비지도 학습 진행
- 위 데이터의 경우 Meta에서 개발한 다국어 모델 llama-2-7b-chat 모델로 학습 진행
구축된 인도네시아어 말뭉치의 원천데이터 텍스트를 Train set, Validation set 8 : 2 비율로 분리하여 학습 및 학습 결과 검증에 활용
비지도학습이 완료되면 미리 만들어 둔 인도네시아어 질문 답변셋으로 추가 지도 학습 진행(질문과 그에 대한 예상 답변을 학습, 많을수록 좋음)
학습 완료 후, 모델에 인도네시아어로 질문 입력 시 그에 대한 답변 출력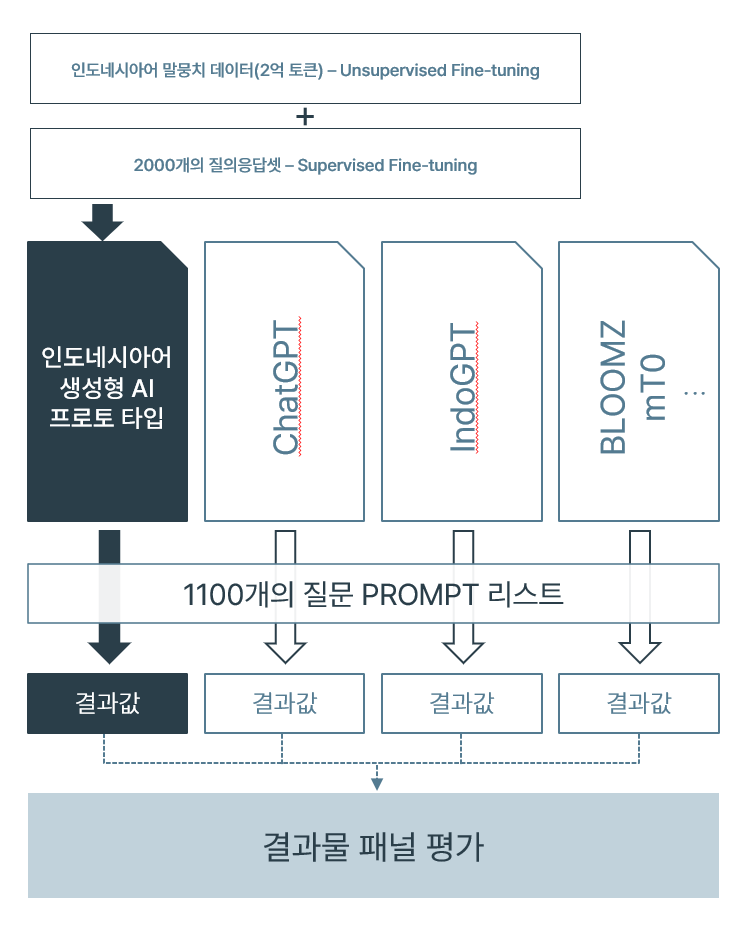
- 서비스 활용 시나리오
1. 개체명 인식 모델
- 인도네시아어 기반의 자연어 데이터 분석 시스템 개발
- 인도네시아어 텍스트 중 한국의 상품, 콘텐츠, 인도네시아어 관련된 개체명들을 구분하여 유의미한 단어 발굴 및 그에 대한 분석 가능2. 언어 생성 모델
- 인도네시아어 중 한국과 인도네시아어 텍스트를 대거 추가 학습하여 인도네시아 진출 한국 기업들의 질의응답, 대화형 서비스 개발에 활용
- 인도네시아 현지인들의 한국의 제품과 콘텐츠 관련 질의가 가능한 챗봇 개발 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 포맷
데이터 포맷 구분 원천데이터 파일 형식 라벨링데이터 파일 형식 형식 CSV JSON - 원천데이터 구성 항목
- 정제된 텍스트 본문과 메타데이터를 포함한 .csv 파일
- 메타데이터 : 텍스트의 출처와 텍스트를 찾은 키워드, 문서 번호, 문장 번호, 문서 작성일, 수정일, 토큰 수- 라벨링 데이터 구성 항목
- 메타 데이터 : 파일명, 제목, 문서 종류, 문서 검색 키워드, 문서 작성일, 문서 수정일, 문서 수집일, 문장 ID, 원천데이터 내 토큰 수, 가공 후 Entity 수, 가공자 ID, 텍스트 데이터, 라벨링 데이터
- 원천데이터 원문 : 정제된 원천데이터를 문장형태로 입력라벨링 데이터 구성 항목 NO 항목명 타입 항목 설명 예시 1 Doc_ID String 문서 고유 ID "20230808_newsdata_Korea_000400" 2 Filename String 원천데이터 파일명 "2023_nia_KO-INDATA_B_000001.txt" 3 Title String 원시데이터 제목 “Wikipedia_Nongshim” 4 Text String 원시데이터 전문 "Nongshim (Nongshim Co., Ltd.) adalah produsen makanan olahan terbesar di Korea Selatan, mengkhususkan diri dalam mi instan dan makanan ringan." 5 Pub-Type String 원시데이터 종류 "Wikipedia_Info" 6 Pub_Subj String 원시데이터 키워드 "Nongshim" 7 Pub_Date String 원시데이터 작성일 2023-05-16 8 Mod_Date String 원시데이터 수정일 2021-07-18 9 Coll_Date String 원시데이터 수집일 2021-07-18 10 Sen_ID String 문서 내 문장 ID "B_000001_sen001" 11 Word_Count Int 원천데이터 내 포함된 말뭉치의 수 20 12 NER_Count Int 원천데이터 내 포함된 말뭉치 중 가공된 Entity의 수 4 13 Anno_ID String 가공자 아이디 “IN_098” 14 Raw_data Stirng 원천 데이터 "Nongshim (Nongshim Co., Ltd.) adalah produsen makanan olahan terbesar di Korea Selatan, mengkhususkan diri dalam mi instan dan makanan ringan." 15 Entities_list List 각 토큰별 가공된 엔티티 리스트 [BO-Economy-B, BO-Economy-B, BO_Economy-I, BO_Economy-I, O, O, O, O, O, O, LC_Country-B, LC_Country-I, O, O, O, PD_Food-B, PD_Food-I, O, PD_Food-B, PD_Food-I] 16 Entities List 문장별 엔티티 관련 데이터 모음 17 entity string ‘O’이 아닌 엔티티가 태깅된 단어들 Nongshim 18 entityClass string 위 Entity 값에 태깅된 개체명 BO-Economy-B 19 entityStart number Entity_list에서 Entity가 시작되는 위치 1 20 entityEnd number Entity_list에서 Entity가 끝나는 위치 1 - 어노테이션 포멧
어노테이션 포멧 No 항목 필수 여부 타입 비고 1 Col_Date Y string 2 Doc_ID Y string 3 Pub_Type Y string 4 Pub_Subj Y string 5 Filename Y string 6 Title Y string 7 Text Y string 8 Pub_Date Y string 9 data Y array 문장별 생성 9-1 Anno_ID Y string 9-2 NER_Count Y number 9-3 Raw_data Y string 9-4 Entities_list Y array 9-5 Sen_ID Y string 9-6 Word_Count Y number 9-7 Entities Y array Entity list에 태깅된 Entity가 있을 때만 생성 9-7-1 entityClass N string 9-7-2 entityEnd N number 9-7-3 entityStart N number 9-7-4 entity N string - 실제 예시
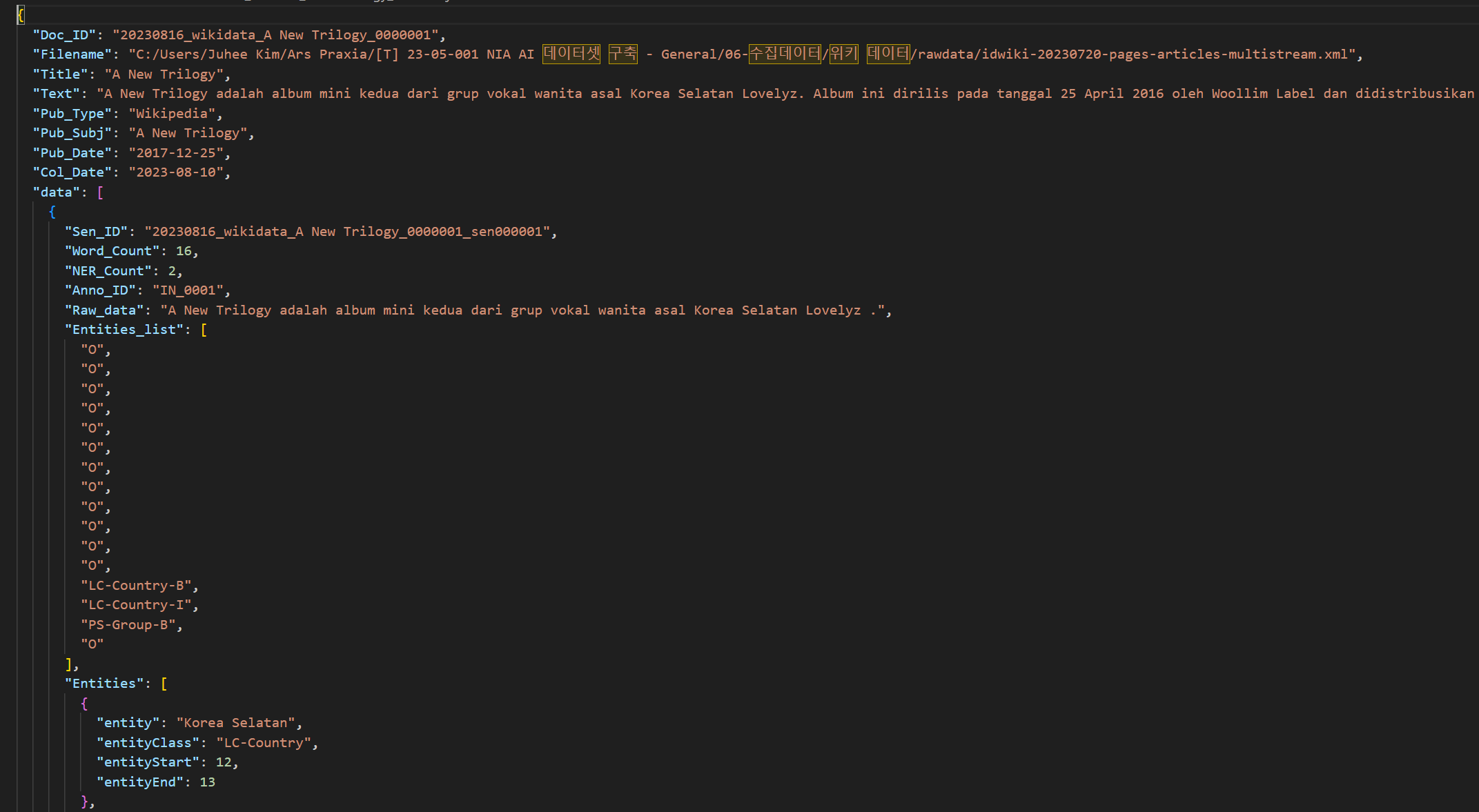
-
데이터셋 구축 담당자
수행기관(주관) : ㈜아르스프락시아
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김민우 070-5100-5266 [email protected] 데이터 구축 사업 실무 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜ 테스트웍스 데이터 라벨링 한국외국어대학교 연구산학협력단 데이터 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김도훈 070-5100-5266 [email protected] 김민우 070-5100-5266 [email protected] AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 김도훈 070-5100-5266 [email protected] 김민우 070-5100-5266 [email protected] 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 김도훈 070-5100-5266 [email protected] 김민우 070-5100-5266 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.