NEW 생성형AI AI응답 결과에 대한 품질 평가 데이터
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-10-30 데이터 최종 개방 1.0 2024-07-05 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-07-05 산출물 공개 Beta Version 소개
- 요약, 질의 응답, 대화 시스템 평가 등 자연어 생성 테스크를 평가할 수 있는 체계적이고 신뢰할 만한 AI 응답 평가 지표 제시하는 데이터
구축목적
- 명확한 응답 평가 지표를 제시하고, 이를 기반으로 AI 응답 품질 평가 데이터를 구축하여 AI 응답 품질을 정량적으로 평가하고 개선함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 tsv 데이터 출처 자체 생성/수집 라벨링 유형 텍스트 분류(자연어), 이진분류(자연어), 요약(자연어), 문장 원본 주석(자연어) 라벨링 형식 json 데이터 활용 서비스 AI 비서, 챗봇 서비스 데이터 구축년도/
데이터 구축량2023년/라벨링 데이터 : 1,001,428 발화 (56,819 대화 세션) -
- 데이터 구축 규모
데이터 구축 규모 원시데이터 수량 원천데이터 수량 라벨링데이터 수량 tsv tsv json 110만 (발화) 107만 (발화) 1,001,428만 (발화)
56,819만 (대화)- 데이터 분포
데이터 분포 구분 항목명 정량목표 결과값 다양성 전체 발화 수 1,000,000 이상 1,001,428 대화별 화자당 발화 수 최소 7발화 7 발화 : 0.01% 8 발화 : 19.42% 9 발화 : 80.04% 10발화 : 0.38% 11발화 : 0.15% 대화 주제 분포 구성비 중첩률 50% 구성비 중첩률 68.36% 목표 구성비 구축 구성비 미용,건강,식음료 14.30% 미용,건강,식음료 12.66% 여행,여가,취미 14.30% 여행,여가,취미 9.25% 주거,생활,사람관계 14.30% 주거,생활,사람관계 8.64% 경제활동,상품/상거래 14.20% 경제활동,상품/상거래 7.76% 엔터테인먼트, 14.30% 엔터테인먼트, 15.71% 오락, 예술 오락, 예술 인문사회 14.30% 인문사회 23.73% 기술,자연과학 14.30% 기술,자연과학 22.25% 합계 100% 합계 100% 평가 지표별 ‘NO’ 응답수 목표 수량 구축 수량 언어학적 수용성 30,000 언어학적 수용성 218,168 일관성 30,000 일관성 182,606 흥미유발 30,000 흥미유발 130,093 비편향성 30,000 비편향성 166,991 무해성 30,000 무해성 200,696 정확성 30,000 정확성 289,886 이해가능성 30,000 이해가능성 149,677 적절성 30,000 적절성 193,797 구체성 30,000 구체성 108,806 호감성 4,000 호감성 23,676 구문정확성 구조 정확성 99.50% 100% 형식 정확성 99.50% 100% 의미정확성 대화주제 분류 적정성 90% 98.57% 대화 요약 적정성 90% 95.24% AI 응답 결과 평가 지표 분류
적정성90% 98.37% 유효성 평가 지표 분류 성능 90% 93.88% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 모델 설명
- 발화 단위로 글쓰기에 대해 평가하는 모델(9가지 항목), 대화 전체에 대한 호감성을 평가하는 모델 두 가지 모델로 구성되어 있다.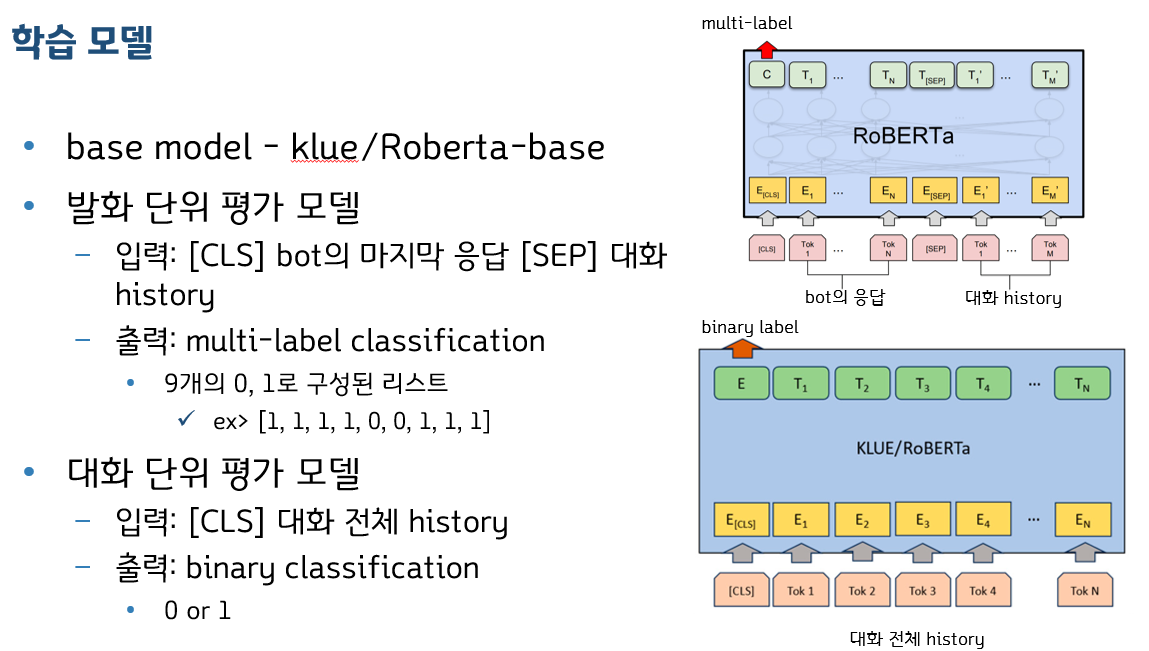
- 모델 학습
- 두 모델은 각각 Training / Validation / Test 데이터를 80% / 10% / 10% 비율로 학습했다. 각 지표별로 아래 표와 같은 성능을 보였고, 전체 평균 Accuracy는 0.9388이다.
모델 학습 지표별 성능 항목 TP FP TN FN Accuracy linguistic_acceptability 42237 922 6705 207 0.977452018 consistency 43364 1935 4385 387 0.953625851 interestingness 45376 2846 1776 73 0.941702782 unbias 43665 337 5130 939 0.974516187 harmlessness 43134 311 6273 353 0.986738831 no_hallucination 38478 3256 6893 1444 0.906133291 understandability 44097 2734 2420 820 0.92902079 sensibleness 42724 2675 4215 457 0.937448823 specificity 46114 2126 1768 63 0.956282079 likeability 4283 509 409 481 0.825765576 - 서비스 활용 시나리오
- 생성형 인공지능 모델에 대한 평가
> 최근 LLM과 같은 생성형 인공지능이 많이 공개되고 있는데, 생성형 모델에 대한 평가지표가 마땅치 않은 상황에서 하나의 인간 친화적인 평가지표로 제안될 수 있음.- 생성형 모델의 학습에 이용
> 많은 생성형 모델이 강화학습을 이용하여 학습하고 있는데, 강화학습에서 보상 모델중 하나로 동작 가능- 글쓰기 평가 또는 데이터 구축 등 사람이 작성한 글에 대해 평가
> 데이터 구축시 하나의 검수자로서 역할을 할 수 있음 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 원천데이터 구성
원천데이터 구성 항목 타입 설명 비고 ai_chat_data_id string 데이터셋 ID utterance_seq integer 발화 순서 utterance_text string 발화 uid integer 발화자 구분 terminate integer 마지막 종료 발화인지 여부 발화 종료: 1
발화 지속: 0- 라벨링 데이터 구성
라벨링 데이터 구성 구분 속성명 타입 필수
여부설명 1 dataset object Y 데이터셋 1-1 title string Y 데이터셋 이름 1-2 distributor string Y 데이터 배포자 1-3 year string Y 데이터 생성 년도 1-4 conversations array Y 대화 정보 1-4-1 conversation_id number Y 대화 세션 id 1-4-2 metadata object Y 대화 메타 정보 1-4-2-1 topic string Y 대화 주제 1-4-2-2 speakers array Y 발화자 정보 1-4-1-2-1 speaker_id number Y 화자 id 1-4-1-2-2 speaker_type string Y 화자 타입 1-4-2-3 evaluators array Y 평가자 정보 1-4-2-3-1 evaluator_id number Y 평가자 id 1-4-2-4 answer_evidence array Y AI 답변 근거 정보 1-4-2-4-1 source string Y AI발화 정보의
근거가 되는 URL1-4-3 utterances array Y 발화 정보 1-4-3-1 exchange_id string Y 턴 id 1-4-3-2 utterance_id string Y 발화 id 1-4-3-3 speaker_id number Y 화자 id 1-4-3-4 utterance_text string Y 발화 1-4-3-5 utterance_evaluation array Y 발화 평가 1-4-3-5-1 linguistic_acceptability string Y 언어학적
수용성 평가1-4-3-5-2 consistency string Y 일관성 평가 1-4-3-5-3 interestingness string Y 흥미성 평가 1-4-3-5-4 unbias string Y 비편향성 평가 1-4-3-5-5 harmlessness string Y 무해성 평가 1-4-3-5-6 no_hallucination string Y 정보 근거성 평가 1-4-3-5-7 understandability string Y 이해 가능성 평가 1-4-3-5-8 sensibleness string Y 답변의 적절성 평가 1-4-3-5-9 specificity string Y 답변의 구체성 평가 1-4-4 conversation_summary string Y 대화 요약 1-4-5 conversation_evaluation object Y 대화 단위 응답 평가 1-4-5-1 likeability array Y 대화 내 AI에 대한
호감성 평가 -
데이터셋 구축 담당자
수행기관(주관) : 심심이㈜
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김재윤 02-562-5332 [email protected] - 사업 관리 - 저작/검수 워크벤치 개발 및 운영 - 데이터 샘플링 검수 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜다이얼로그디자인에이전시 - 데이터 설계
- 작업 공정 설계 및 작업 가이드라인 작성
- 데이터 생성 및 라벨링
- 데이터 정제
- 데이터 검수㈜미디어코퍼스 - 데이터 설계
- 작업 공정 설계 및 작업 가이드라인 작성
- 데이터 생성 및 라벨링
- 데이터 정제
- 데이터 검수㈜테디썸 - 데이터 설계
- AI 모델링
- 한국어 LLM 적용 실험데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박일섭 02-881-5758 [email protected] 양성민 02-881-5759 [email protected] AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 함영균 010-7797-4184 [email protected] 정용빈 010-5773-0464 [email protected] 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 김재윤 02-562-5332 [email protected] 임현승 02-562-5332 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.